

A Robust Speech Recognition Method Based on Acoustic Model Array
An acoustic model and speech recognition technology, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as being easily covered by noise, adverse effects of model self-adaptation, and inability to provide effective effects for speech recognition, so as to achieve enhanced robustness, The effect of reducing influence and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

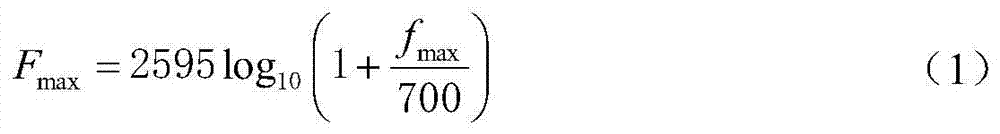
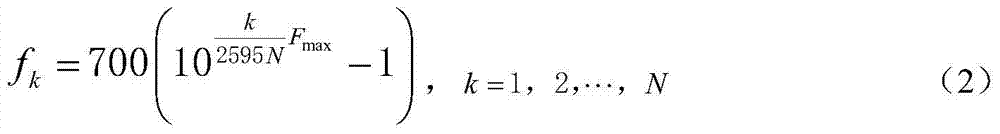
Examples
Embodiment Construction
[0018] Below in conjunction with specific embodiment, further illustrate the present invention, should be understood that these embodiments are only used to illustrate the present invention and are not intended to limit the scope of the present invention, after having read the present invention, those skilled in the art will understand various equivalent forms of the present invention All modifications fall within the scope defined by the appended claims of the present application.
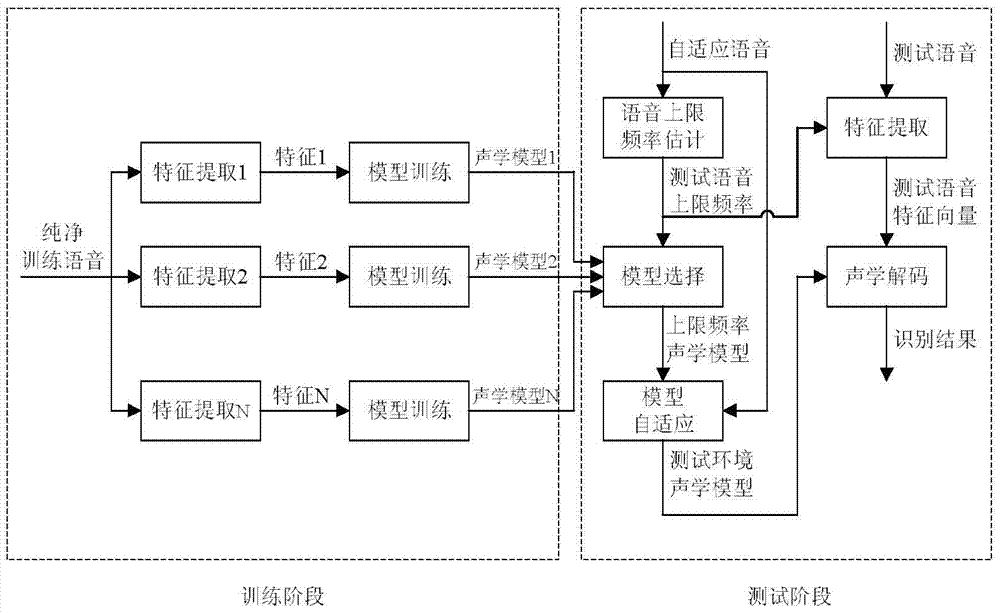
[0019] Such as figure 1 As shown, the robust speech recognition method based on the acoustic model array includes the following steps:
[0020] 1. Training voice upper limit frequency setting:
[0021] Let the highest frequency of speech in the training speech library be f max , first convert it to the Mel frequency domain:
[0022]
[0023] Among them, F max Indicates the highest frequency in the Mel frequency domain. Then, according to F max Set the upper limit frequency of N speech spe...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More