

A method and system for document retrieval
A literature retrieval and literature technology, applied in the field of massive data processing, can solve the problems of low efficiency and poor pertinence of retrieval methods, and achieve the effect of improving hit rate, use value and high value
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
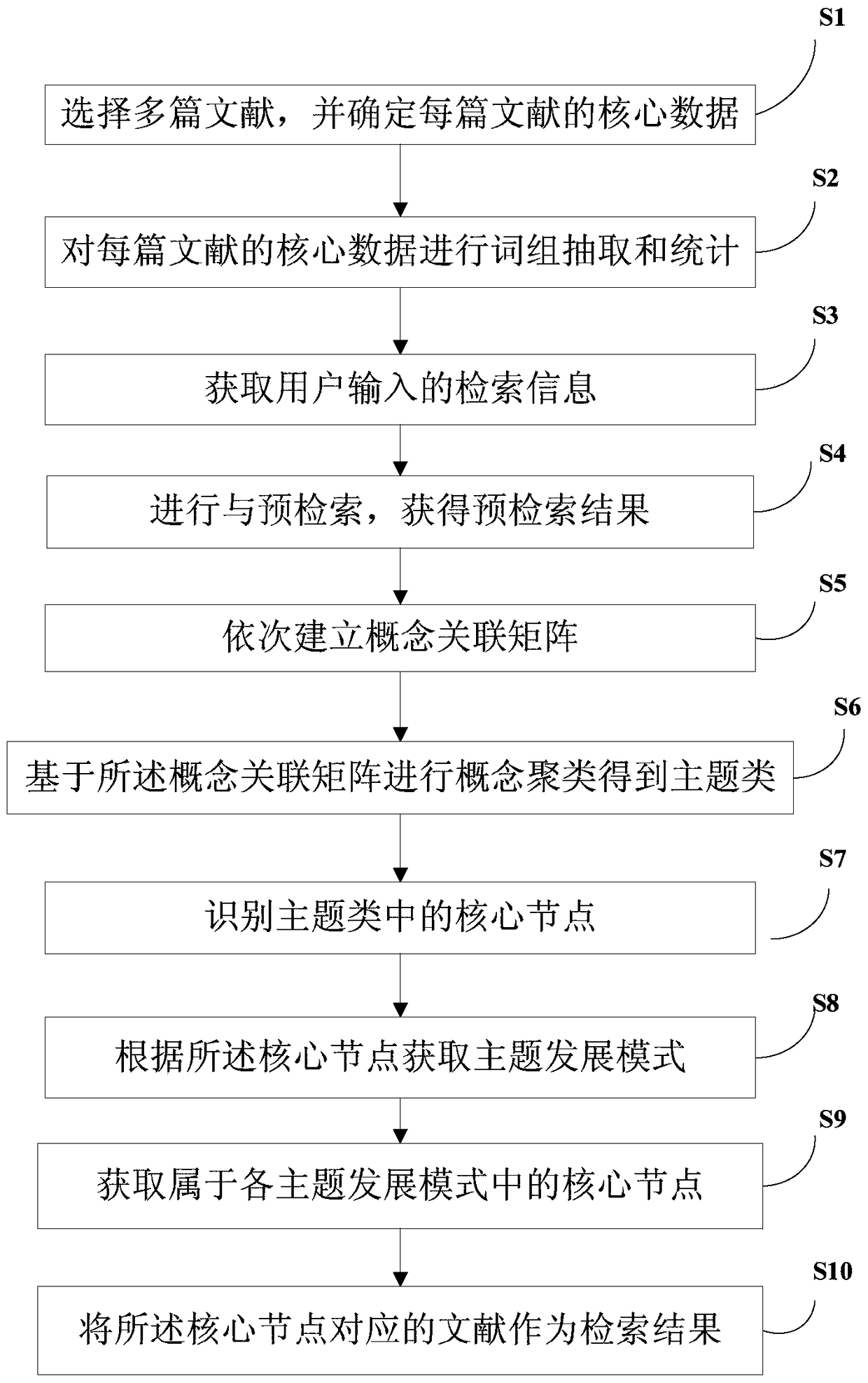
[0053] The invention provides a document retrieval method, which can be used for retrieval of scientific and technological documents, the flow chart is as follows figure 1 shown, including the following steps:
[0054] The first is the preprocessing of documents, including step S1 and step S2.
[0055] S1. Select multiple documents and determine the core data of each document.
[0056] When selecting multiple documents, select the documents that belong to the related field of the content to be retrieved as needed. The selected documents may be some documents in the field related to the retrieval information, or documents in some authoritative periodicals and other databases. Due to the large amount of full-text data in the literature, it is not easy to reflect the core content of the literature. Selecting the core content of the literature for analysis can make it more targeted. Here, the core content of the retrieved documents, such as the subject of the document (or the t...
Embodiment 2
[0096] In addition, a specific application example is also provided in this embodiment, the retrieved information is provided by the user, and the rest of the process is completed in the background server.
[0097] S1. First, select a data source. In this example, more than 30,000 English core periodicals of 18 rice species in 20 years (1995-2012) were used as the data source. The specific periodical list is shown in Table 2.
[0098] Table 2 List of Journal Data Sources
[0099]
[0100]
[0101] Then, the core content of the documents such as the subject (or title), search terms (keywords in general), and abstracts are extracted from the above documents as the core data set.
[0102] S2. Perform phrase extraction and statistics on the core data of each of the above documents, and map phrases with similar meanings into the same concept to obtain a concept set, which includes concept, source and concept frequency.
[0103] When performing knowledge extraction, a total ...
Embodiment 3
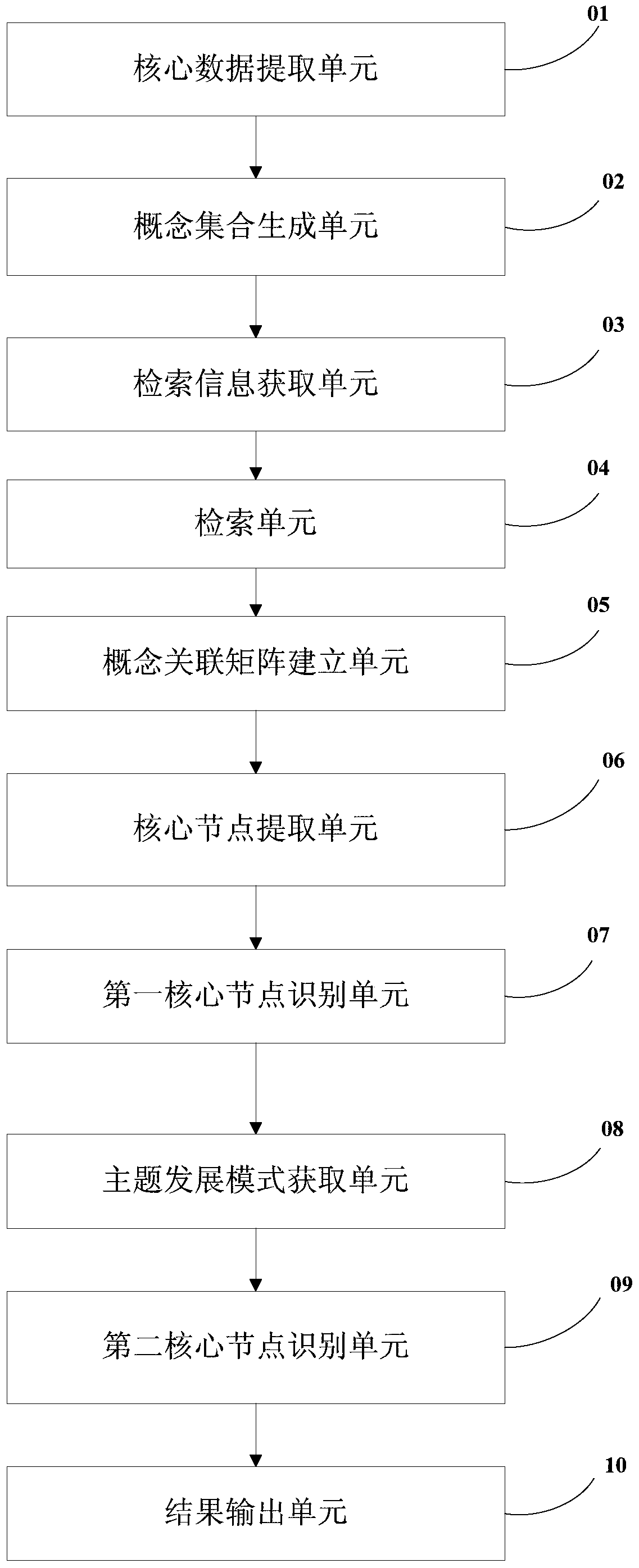
[0164] As another embodiment of this embodiment, this embodiment provides a document retrieval system, the structural block diagram is as follows image 3 shown, including:
[0165] Core Data Extraction Sheet 01, select multiple documents and determine the core data of each document;
[0166] The concept set generation unit 02 is used to extract and count the phrases of the core data of each document, and map the phrases with similar meanings to the same concept to obtain a concept set, which includes concept, source and concept frequency;
[0167] The search information acquisition unit 03 is used to obtain the search information input by the user, and the search information includes search words, search time period and time slice length;
[0168] Retrieval unit 04, performing a pre-retrieval of search term matching in the core data of the document according to the search term, and obtaining the document matching the search term and the publication time and concept set of th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More