

Method for big data retrieval based on time characteristics and supporting complicated conditions
A time-featured and complex technology, applied in the field of big data retrieval, can solve the problems of reduced retrieval performance and increased cost, and achieve the effect of maintaining high efficiency, improving efficiency, and satisfying retrieval needs.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
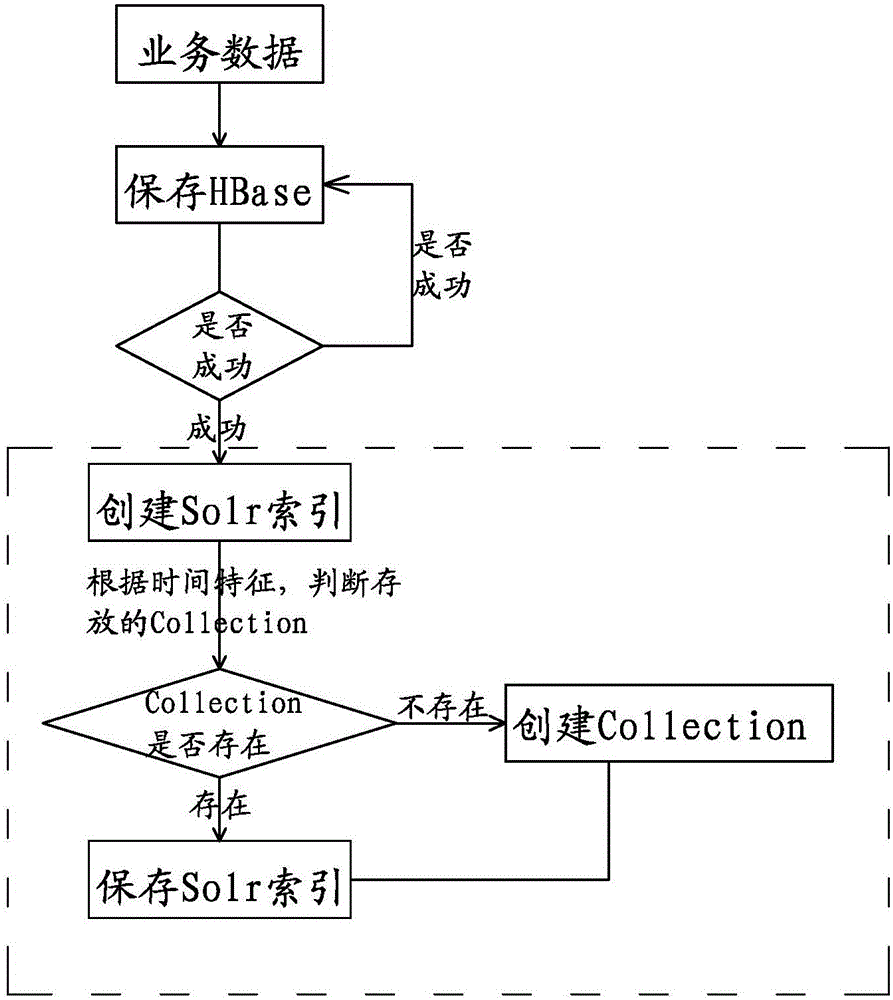
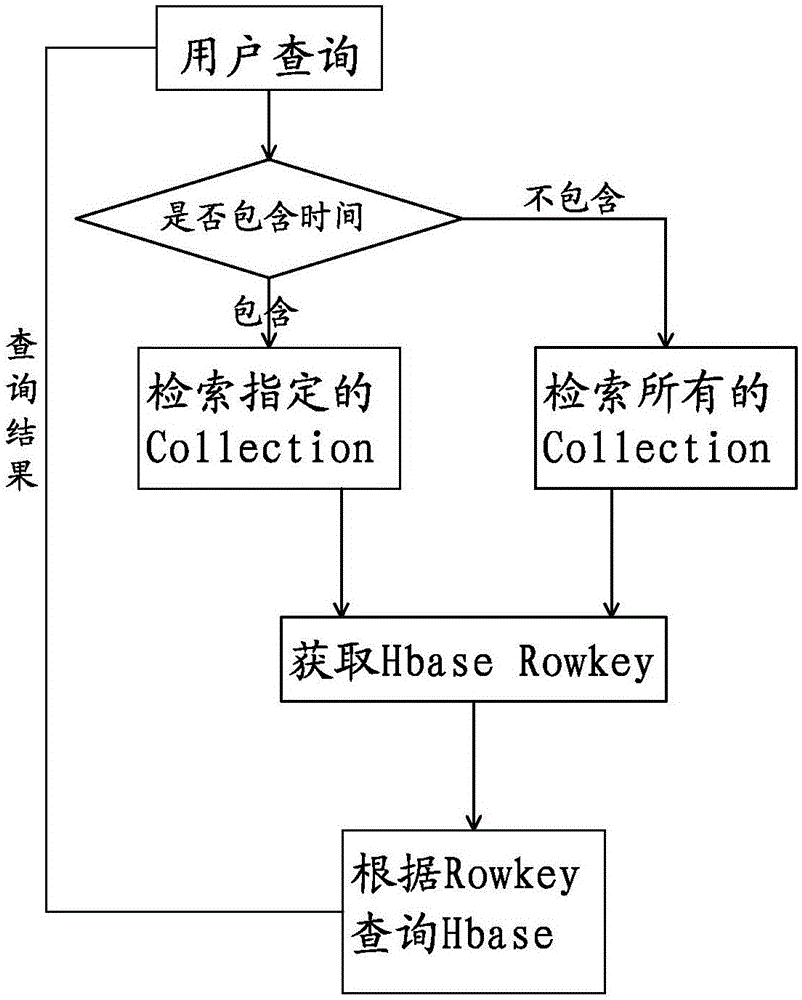
[0017] At present, in big data applications, the data information is stored with time characteristics, that is, time stamps. The present invention divides the data information according to the time characteristics according to the timestamp generated when the data is saved or according to the user-defined time characteristics, and builds indexes with different cluster Collections on the full-text search engine Solr, for example, according to the year and month, in the When the user already knows the generation time of the queried information, he can quickly locate the index library of the current month's cluster Collection for retrieval, which can greatly reduce the scope of retrieval and improve efficiency; when the user cannot determine the generation time of the information Under certain circumstances, the results that meet the user's query are arranged in reverse order according to the time when the information was generated, as the user's default sorting method, and the so...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More