

Keyword calculation method based on document clustering
A technology of document clustering and calculation method, applied in the direction of text database clustering/classification, calculation, unstructured text data retrieval, etc., can solve the problem of no technical solution and so on
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

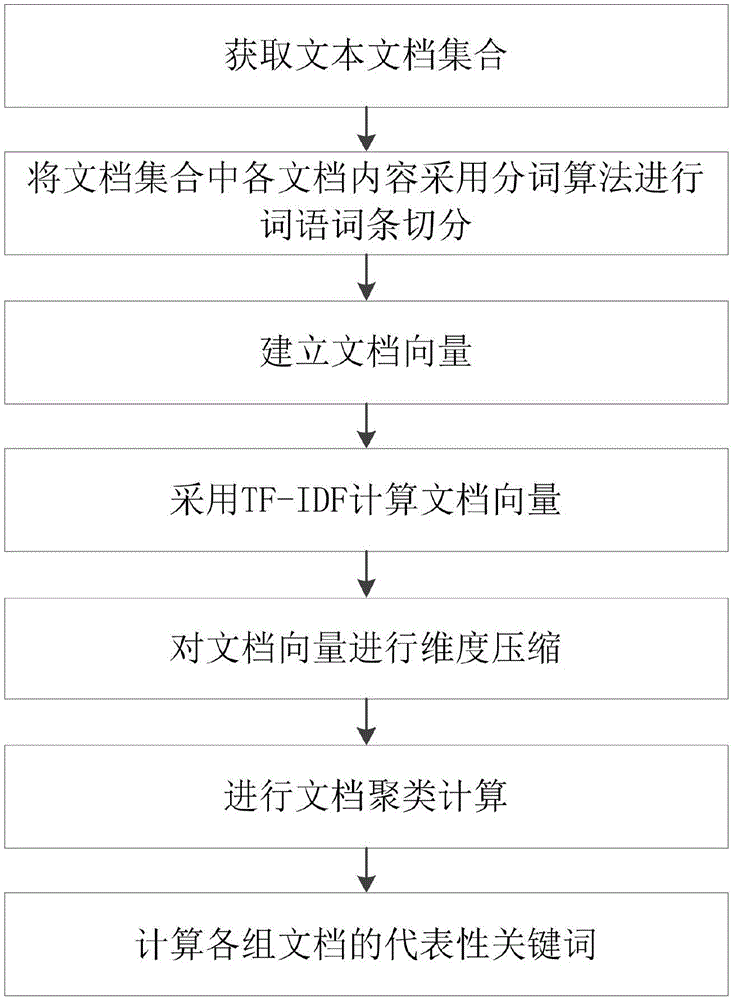
Examples
Embodiment Construction
[0028] The technology involved in the present invention and its notes:
[0029] 1. Text clustering:
[0030] Text clustering (TextClustering) document clustering is mainly based on the well-known clustering assumption: documents of the same type have a greater similarity, while documents of different types have a smaller similarity. Text clustering can divide a relatively large collection of documents into several subcategories, so that similar documents can be organized in the same category. As an unsupervised machine learning method, clustering has certain flexibility and high automatic processing ability because it does not require a training process and manual labeling of documents in advance, and has become an effective method for organizing text information. , summary, and navigation.
[0031] The applications of text clustering technology mainly include:
[0032] Perform clustering operations on documents that users are interested in (such as news or products that us...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More