

Text sequence iterative method for semantic understanding
A text sequence and semantic understanding technology, which is applied in the field of text sequence iteration for semantic understanding, can solve problems such as high cost of reproduction, low efficiency, and scalability to be improved
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
specific Embodiment approach 1
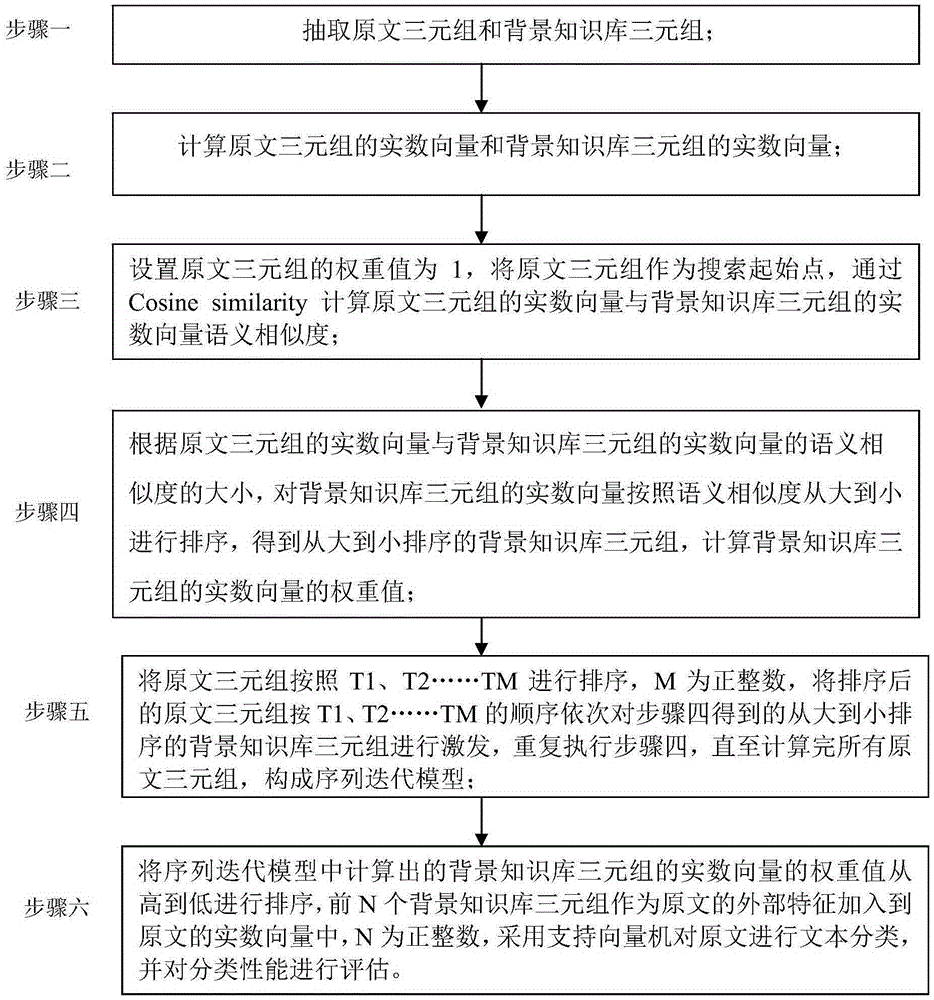
[0034] Specific implementation mode one: combine figure 1 Describe this embodiment, a text sequence iteration method for semantic understanding in this embodiment, specifically prepared according to the following steps:
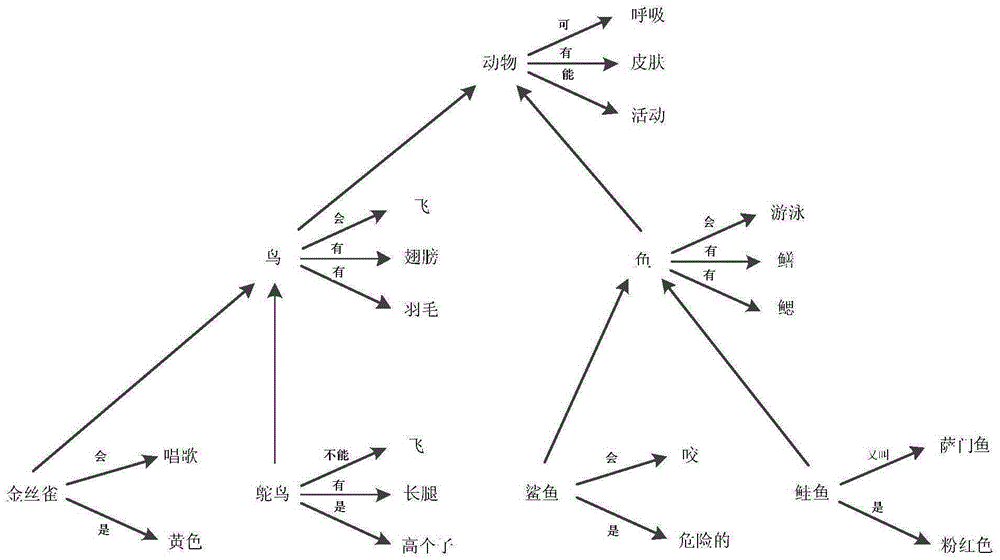
[0035] Step 1. Extract background knowledge base triples and original text triples, and the original text is used to verify the model;
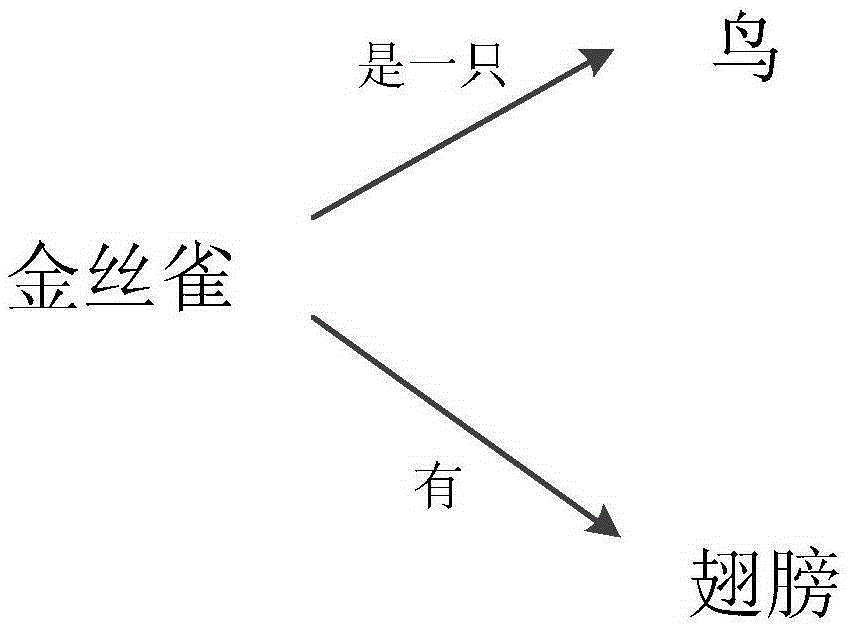
[0036] As the name implies, the knowledge concept is a unit that expresses a complete concept information. As mentioned in 4.2, it is expressed in the form of triples in this model. In order to enable triples to fully express the semantic information in the text, we use Semantic Role Labeling (SRL) to extract the backbone information of the sentences in the text [19] (LiuT, CheW, LiS, etal.Semanticrolelableingsystemusingmaximumentropyclassifier[C] / / ProceedingoftheNinthConferenceonComputationalNaturalLanguageLearning.AssociationforComputationalLinguistics, 2005:189-192.), mainly to extract triples such as A0-predicate-A1, w...
specific Embodiment approach 2
[0042] Specific implementation mode two: the difference between this implementation mode and specific implementation mode one is: the background knowledge base triplet and the original text triplet are extracted in the described step one; The specific process is:
[0043] The experimental data set comes from the Internet text classification corpus provided by Sogou Lab. After preliminary filtering (filtering by artificial settings, filtering out illegal characters in the article and articles with a long text length), the number of available texts is 17,199. There are 9 categories of texts in the Internet text classification corpus, namely finance, IT, health, sports, tourism, education, recruitment, culture, and military. 200 articles are randomly selected for each type of text as test corpus, a total of 1800 original texts. The extraction tool uses Harbin The LTP language technology platform of the Social Computing and Information Retrieval Research Center of the Industrial Un...
specific Embodiment approach 3
[0046] Specific embodiment three: what this embodiment is different from specific embodiment one or two is: the weight value of original text triple is set to 1 in the described step 3, with original text triple as search starting point, by Cosinesimilarity (cosine similarity degree) to calculate the semantic similarity between the real number vector of the original text triplet and the real number vector of the background knowledge base triplet; the specific process is:
[0047] The semantic similarity formula between the real number vector of the original text triplet and the real number vector of the background knowledge base triplet is:
[0048] c o s ( θ ) = A · B | | A | | * | | ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More