Orthogonal multilateral Hash mapping indexing method for improving massive data inquiring performance
A mass data and hash mapping technology, applied in the complex query field, can solve problems such as dependence, system resource consumption, and less data, and achieve the effect of improving performance and query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
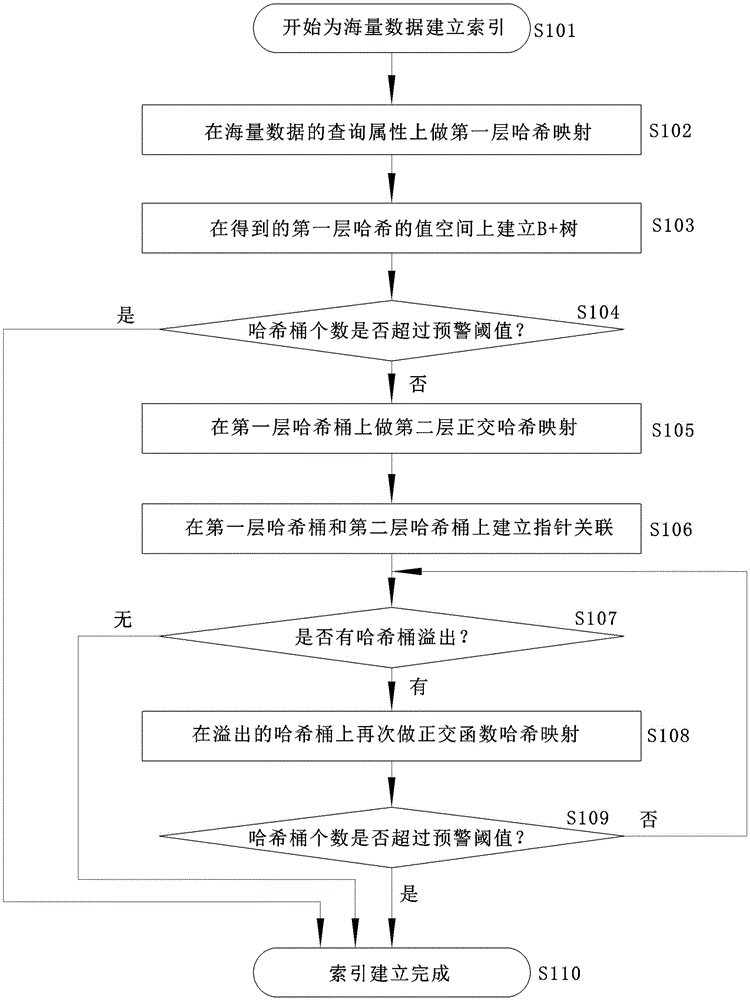
[0020] see figure 1 figure 2 , an orthogonal multi-hash map indexing method for improving the query performance of massive data, comprising the following steps:
[0021] 1) Do the first layer of hash mapping on the query attributes of massive data. This method is applicable to various types of data sources, such as relational databases, data files in the file system, and massive data stored in the format of key-value pairs. All data records are assigned to specific hash buckets after the first layer of hash function mapping;
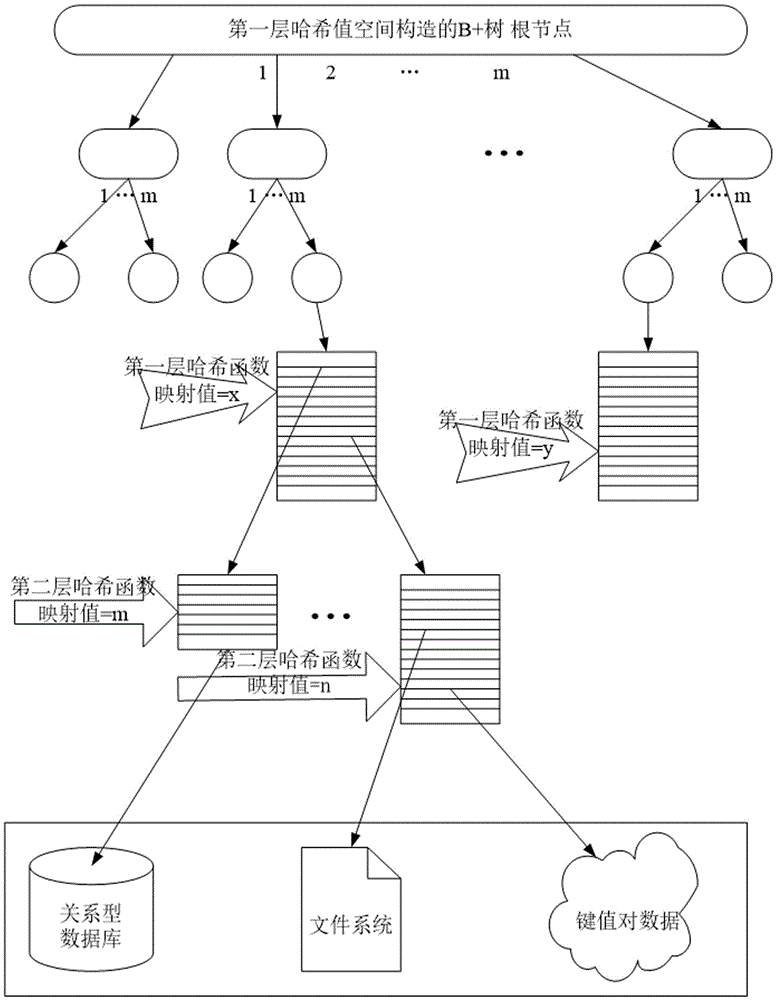
[0022] 2) Build a B+ tree on the value space of the first layer hash, figure 2 It is an m-degree B+ tree, the original linear search time complexity is O(n), optimized to tree search, the tree search time complexity is O(logn), and the search for hash map values is optimized;
[0023] 3) Hash-map the first-level hash buckets again through the second-level hash function, that is, divide the first-level hash buckets again to reduce the data capacity...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com