

Method for outlier data mining based on parallel computation
A technology of outlier data and parallel computing, applied in data mining, calculation, electrical digital data processing, etc., can solve problems such as inability to find hidden outlier data, inability to provide valuable information, inconsistent valuable information, etc., to achieve a solution The problem of uneven data distribution and the effect of solving the problem of local order but global disorder
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

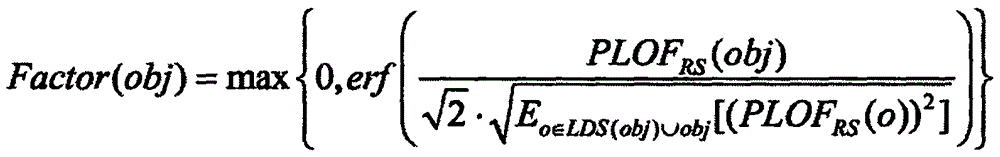
Examples
Embodiment Construction
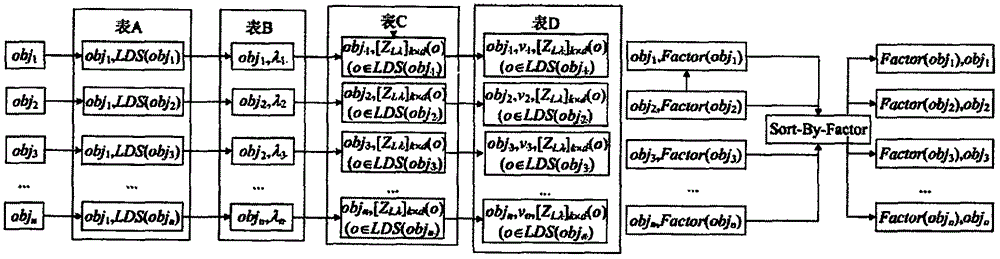
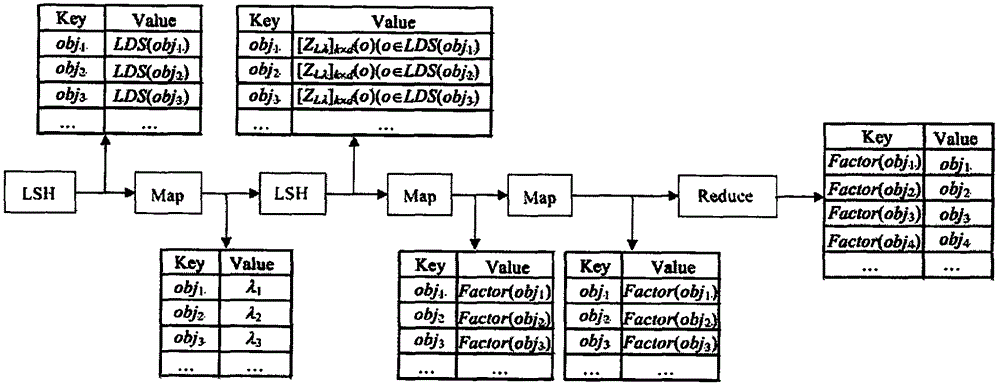
[0024] In order to deepen the understanding of the present invention, the present invention will be further described in detail below in conjunction with the accompanying drawings and embodiments. The following examples are only used to illustrate the technical solution of the present invention more clearly, but not to limit the protection scope of the present invention.
[0025] Traditional algorithm:
[0026] Suppose DS is any d-dimensional data set, attribute set FS={A1, A2,...Ad}, xij(i=1, 2,...,n; j=1, 2,...,d) represents the i-th data The value of the jth attribute of the object obji. If the value of each dimension of the subspace definition vector v of the i-th object obj is 0, it indicates that obj is consistent with the local distribution characteristics; if there is a related subspace in the i-th object obj, it indicates that obj is inconsistent with the local distribution characteristics. Usually we use Factor(obj) to describe the degree of outlier:
[0027] ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More