

A method and device for constructing an application system based on data support
An application system and data technology, applied in the computer field, can solve the problems of reducing the construction efficiency of the application system, affecting the implementation effect, and increasing the occupation of system resources, so as to reduce the construction cost, optimize the implementation effect, and reduce the effect of noise data
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

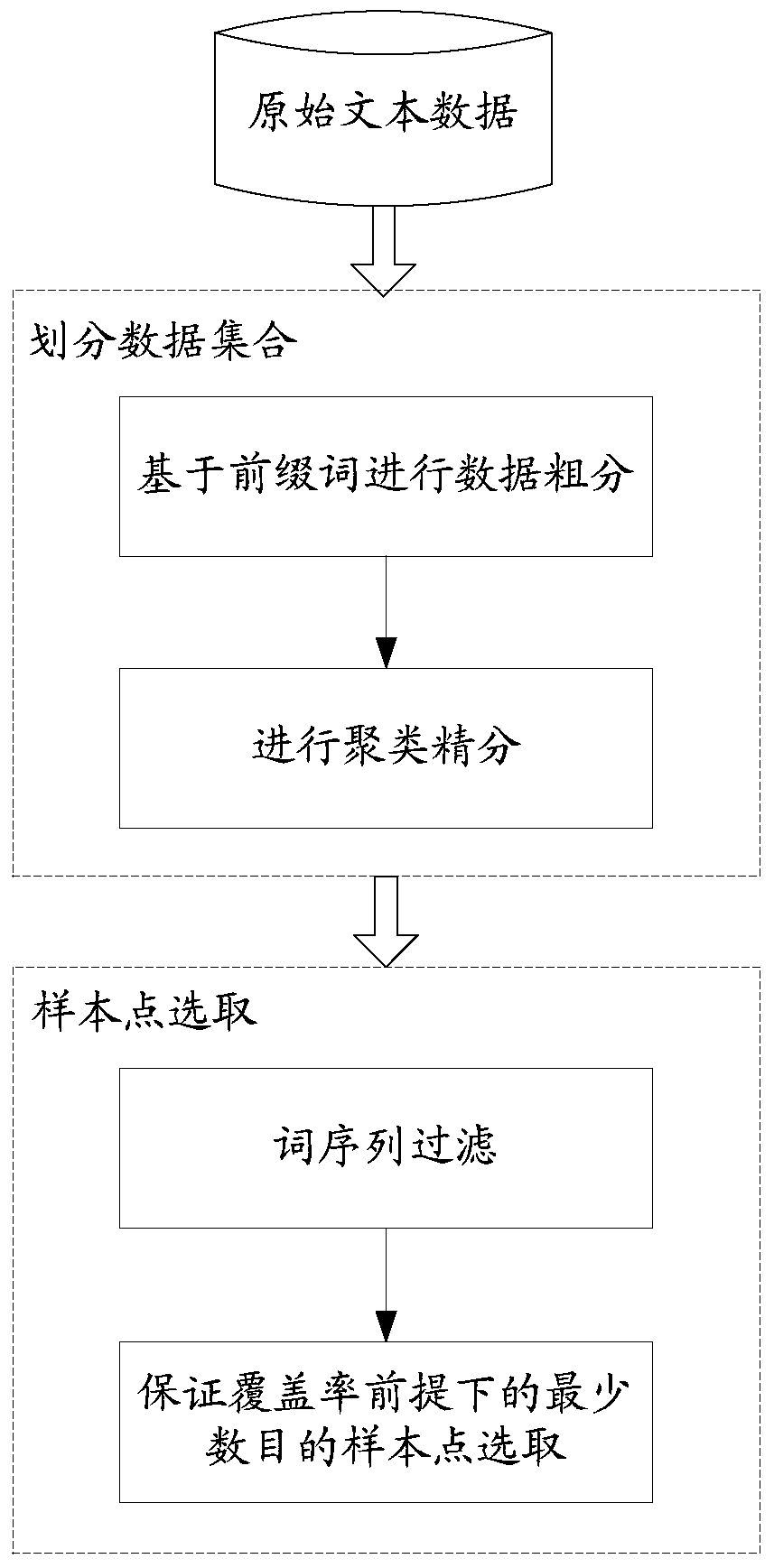
Examples
Embodiment 1
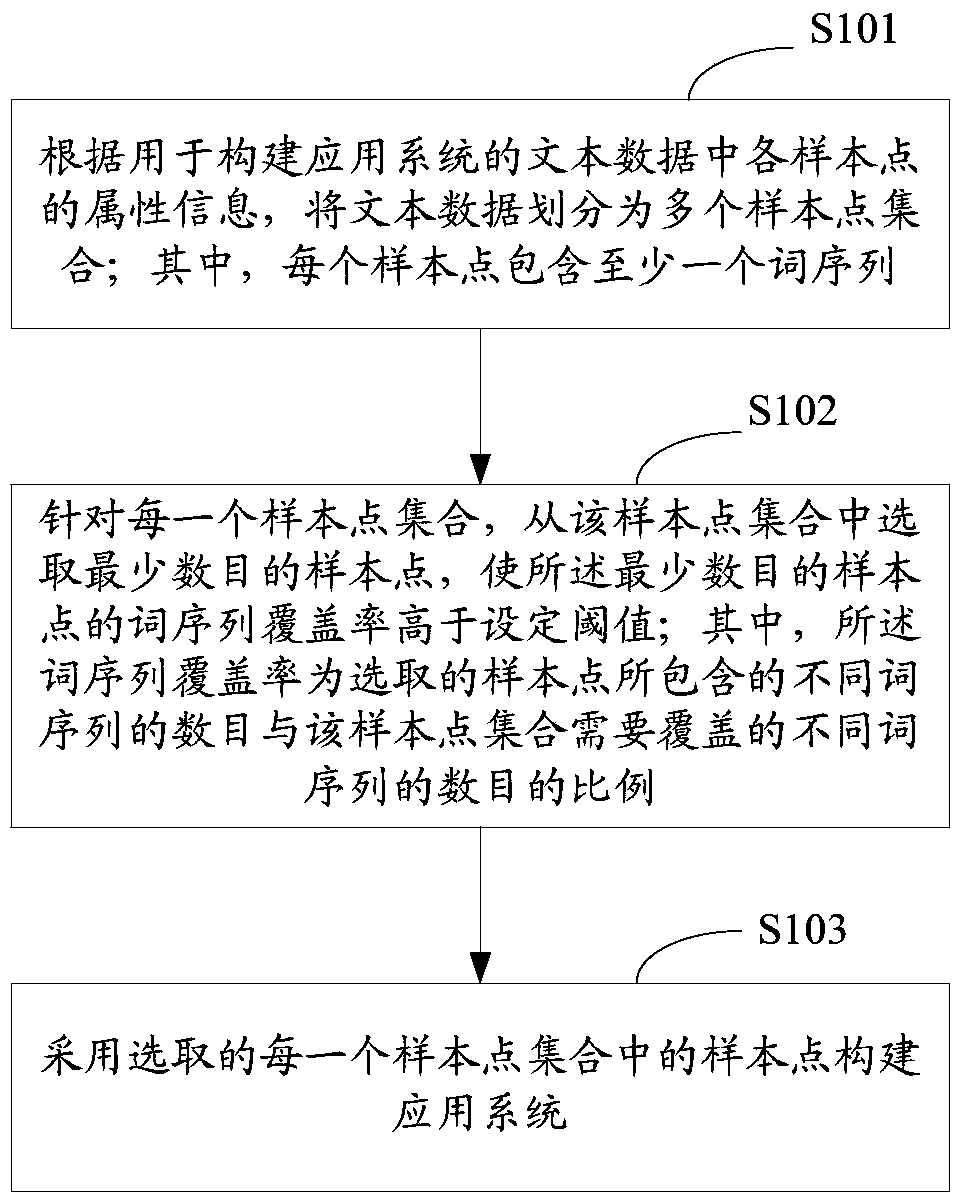
[0050] Such as figure 1 As shown, it is a flowchart of a data-supported application system construction method provided in Embodiment 1 of the present application, including the following steps:
[0051] S101: According to the attribute information of each sample point in the text data used to construct the application system, divide the text data into multiple sample point sets; wherein each sample point contains at least one word sequence.
[0052] In the embodiment of the present application, the sample points may be sentences, phrases, paragraphs, etc. composed of a series of word sequences. The word sequence (N-gram) here is a sequence composed of consecutive N words, and the value of N can be preset, such as 2, 3, 4, 5, etc., or a combination of these numbers, That is, the number of words included in the word sequence can be one or more types; the number of letters or characters included in a word can also be preset. The attribute information may include a clustering fea...
Embodiment 2
[0061] In the second embodiment, clustering is used to divide the set of sample points; when the minimum number of sample points is selected, all the different word sequences included in the entire text data are used as the word sequences to be covered by the application system.
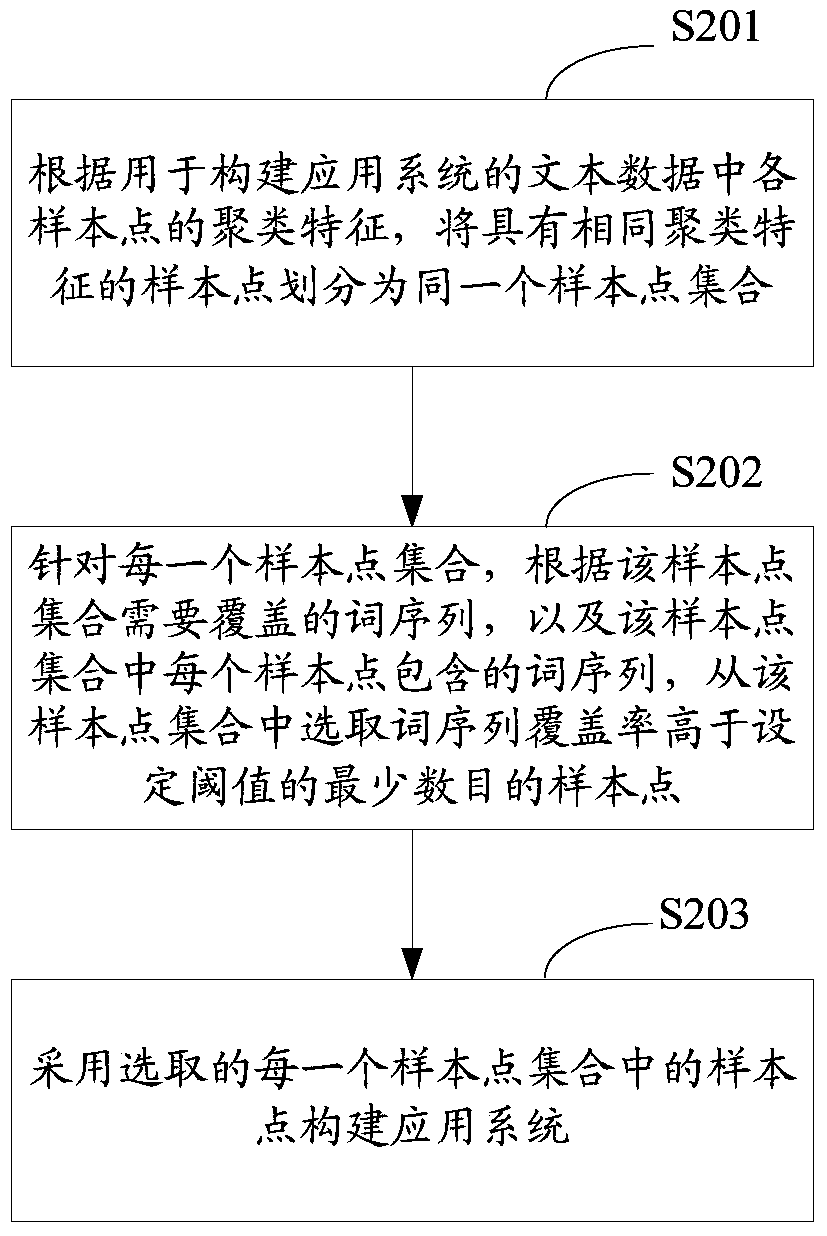
[0062] Such as figure 2 As shown, it is a flow chart of the data-supported application system construction method provided in Embodiment 2 of the present application, including the following steps:
[0063] S201: According to the clustering feature of each sample point in the text data used to build the application system, divide the sample points with the same clustering feature into the same sample point set.
[0064] In the specific implementation process, the clustering features of each sample point can be extracted. For example, the features include: Term frequency–inverse document frequency (TF), inverse document frequency (Term Frequency, IDF) of the word sequence contained in the sample poin...
Embodiment approach
[0075] In this embodiment, after the above-mentioned cluster division in step S201, most of the word sequences contained in the sample points in different sample point sets are different, but there may still be a small part of the word sequences that are repeated, so , in order to further reduce the data scale, the following preferred method can be adopted, each sample point set does not need to cover the word sequences contained in the sample points already selected in other sample point sets. Specifically, for each sample point set, determine the word sequence that the sample point set needs to cover according to the following steps:
[0076] Remove the word sequences included in the sample points selected in other sample point sets from the word sequences that the application system needs to cover, to obtain the remaining word sequences that need to be covered;
[0077] The intersection of each word sequence included in the sample point set and the obtained remaining word s...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More