

A Cross-media Retrieval Method Based on Markov-like Correlation Measure
A correlation measurement and cross-media technology, applied in the field of cross-media retrieval, can solve problems such as slow retrieval speed, large amount of cross-media retrieval data, and high algorithm complexity, and achieve the effect of reducing time complexity
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
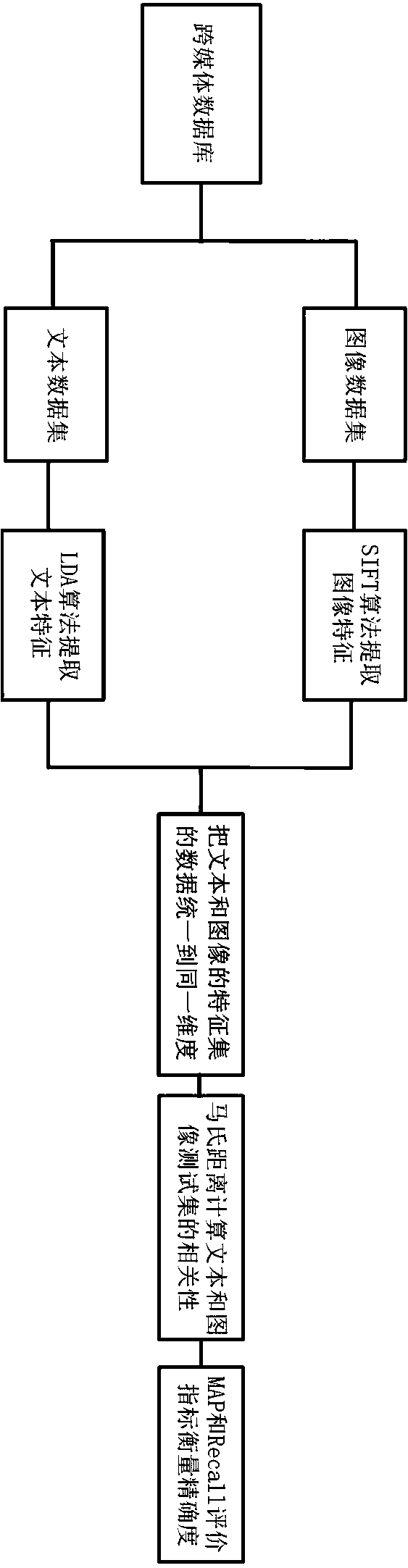
[0032]In order to illustrate the present invention more clearly, the Wikipedia dataset is used as the data source to search, and the ideas of the present invention are elaborated more deeply and specifically; the Wikipedia dataset contains two media, text and images, and the dataset is composed of , history, geography and art and other 10 categories, the text is some news reports about the content of these categories, and the image is a picture related to the content. The Wikipedia dataset contains a total of 2866 samples.
[0033] In conjunction with accompanying drawing, the concrete steps of the present invention are as follows:
[0034] Step 1: Input the Wikipedia dataset database, which contains 2866 pairs of text and images.
[0035] Step 2: Store the text and images in the text and image databases respectively in the Wikipedia dataset image dataset folder and the Wikipedia dataset text dataset folder under the Wikipedia dataset, and store the Wikipedia dataset image dat...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More