

Speech emotion recognition based on slice convolution
A speech emotion recognition and speech technology, which is applied in the computer field, can solve the problems of long speech signal time and inability to perform unified time-frequency analysis, and achieve the effect of improving recognition efficiency.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0023] The following will clearly describe the technical solutions in the embodiments of the present invention with reference to the accompanying drawings in the embodiments of the present invention. Obviously, the described embodiments are some of the embodiments of the present invention, but not all of them. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts fall within the protection scope of the present invention.
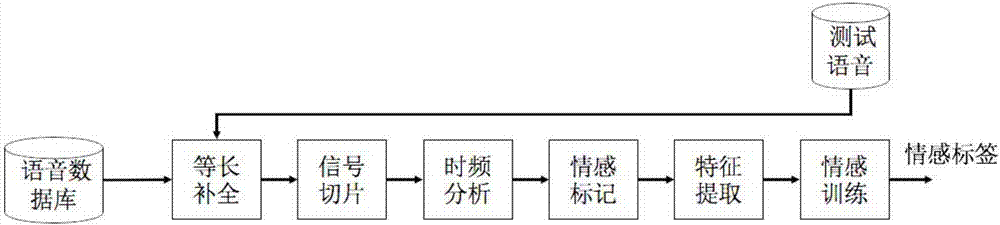
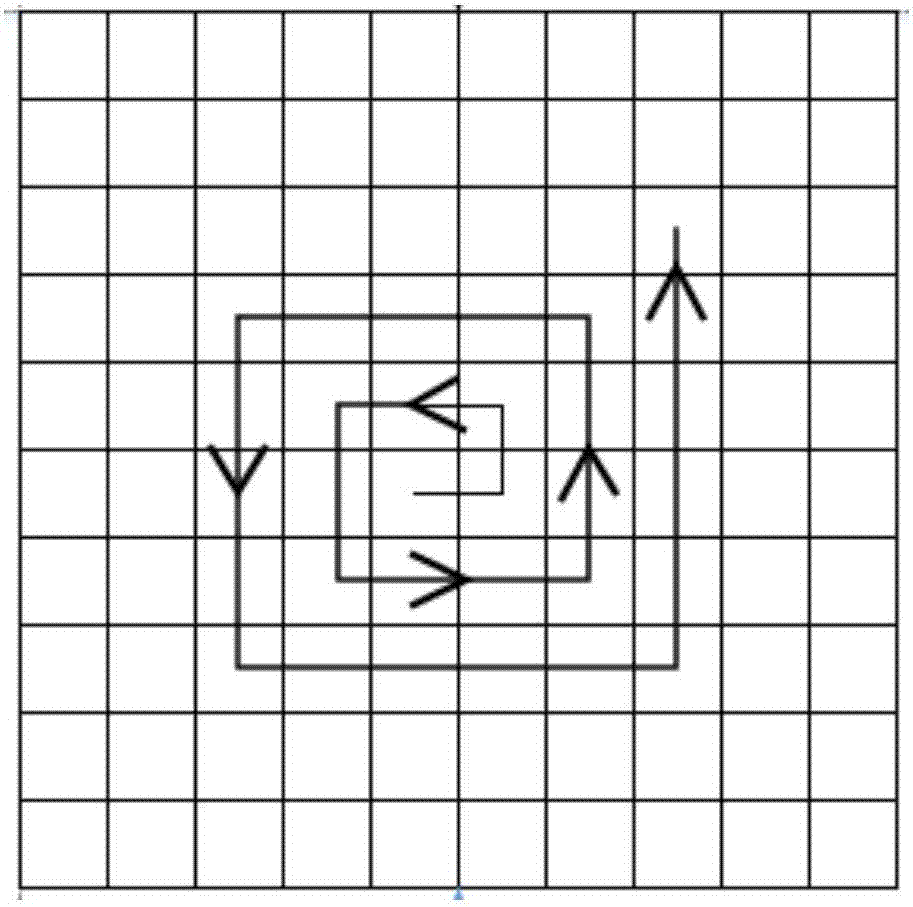
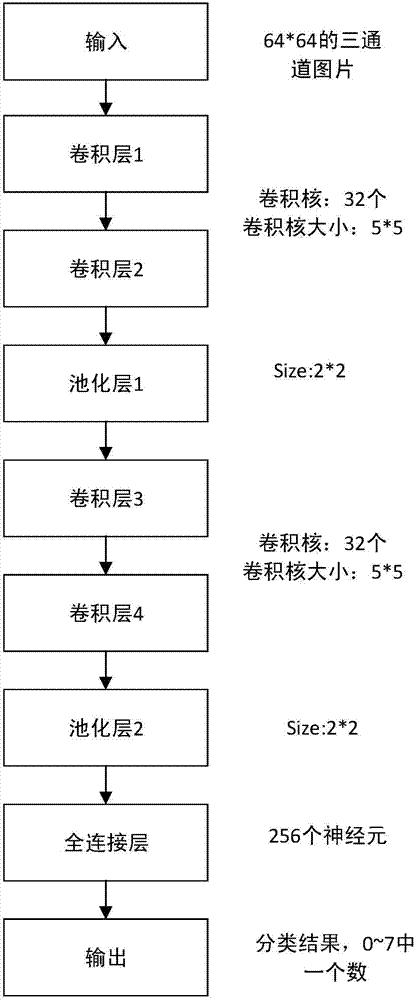
[0024] like figure 1 and image 3 As shown, the present invention provides a method for speech emotion recognition based on time slicing, which is to put the time domain features of sound into the space domain for recognition through sequences, including the following steps:
[0025] Step 1: Set the maximum time length of a voice. For example, in the data set of the embodiment of the present invention, the maximum voice length is 10S. For speech signals that do not...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More