Speech recognition method and device
A technology of speech recognition and speech annotation, applied in speech recognition, speech analysis, instruments, etc., can solve problems such as speech recognition errors, speech recognition errors, and failure to consider polyphonic characters, and achieve the effect of ensuring accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
[0049] refer to figure 1 , which is a flow chart of a speech recognition method described in an embodiment of the present invention, may specifically include the following steps:
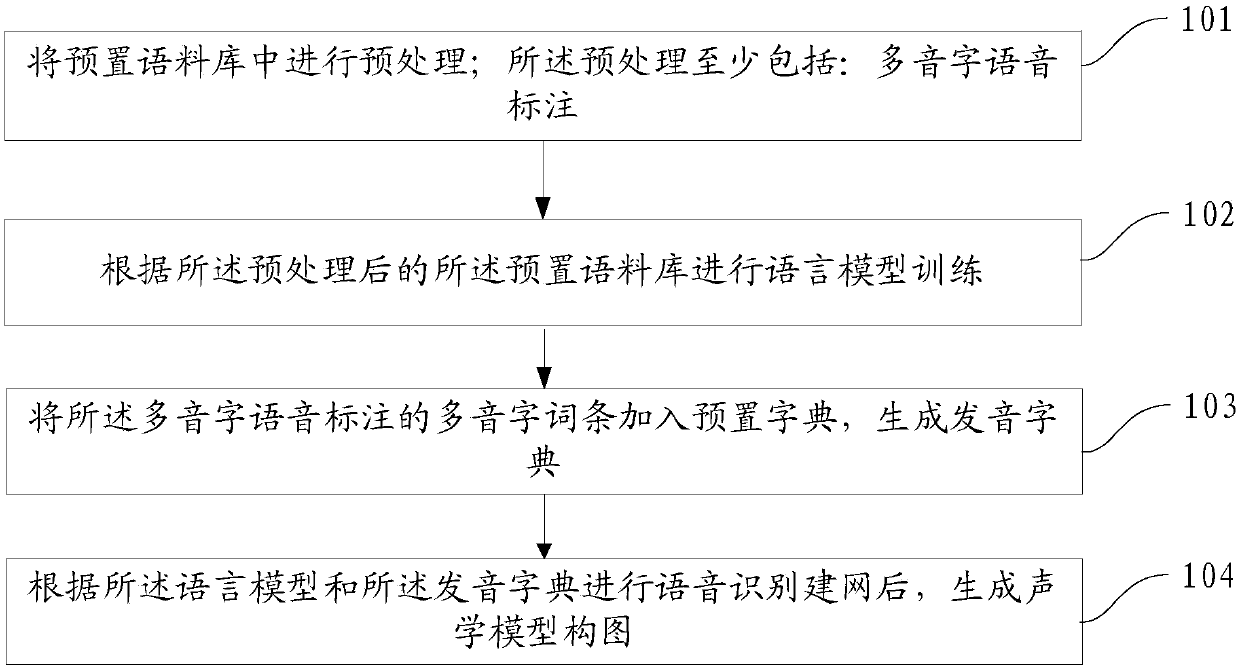
[0050] Step 101, perform preprocessing on the preset corpus; the preprocessing at least includes: phonetic annotation of polyphonic characters.
[0051] In the embodiment of the present invention, after obtaining a corpus, after preprocessing the data in the expected library such as cleaning, word segmentation, etc., the expected data in units of phrases is obtained, and the polyphonic characters that appear in many of the phrases are different according to the phrases. And the pronunciation is different, such as Figure 1A Described, where "De#1" means that the character "De" is a polyphonic character, and there is only one phonetic "De" after the breath, as follows 4-gram: "The breath of life" is changed to "The breath of life #1 ", after manually marking all the polyphonic characters in the exp...
Embodiment 2
[0068] refer to figure 2 , which is a flow chart of a speech recognition method described in an embodiment of the present invention, may specifically include the following steps:
[0069] Step 201, establishing a preset corpus according to the collected Chinese corpus data; the Chinese corpus is extracted from the same language field.
[0070] In the embodiment of the present invention, a corpus refers to a language material library in a popular sense. The corpus in the strict sense refers to a large-scale electronic text library with a certain capacity built by collecting naturally occurring continuous language use texts or discourse fragments according to certain linguistic principles and using random sampling methods. For the information field where the purpose of establishing a corpus is speech recognition, the language text for this specific field is selected, and after preprocessing such as sampling, a corpus for this field is generated.
[0071] It should be...
Embodiment 3
[0095] refer to image 3 , is a structural block diagram of a speech recognition device according to an embodiment of the present invention.
[0096] The corpus preprocessing module 301 is used to perform preprocessing in the preset corpus; the preprocessing includes at least: polyphone phonetic annotation;
[0097] A language model training module 302, configured to perform language model training according to the pre-processed preset corpus;
[0098] Pronunciation dictionary generating module 303, for adding the polyphonic word entry of described polyphonic word phonetic mark to preset dictionary, generates pronunciation dictionary;
[0099] The acoustic model composition generation module 304 is configured to generate an acoustic model composition after the speech recognition network is built according to the language model and the pronunciation dictionary.
[0100] refer to Figure 4 , is a schematic diagram of the relationship between modules in the embod...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com