

Method for text error correction after voice recognition based on domain identification
A speech recognition and text error correction technology, applied in speech recognition, speech analysis, natural language data processing, etc., can solve the problems of a large number of manual intervention, low error correction efficiency, and inability to correct proprietary names, etc., to reduce a lot of time Effects of loss, data accuracy and authenticity, enhanced practicability and robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
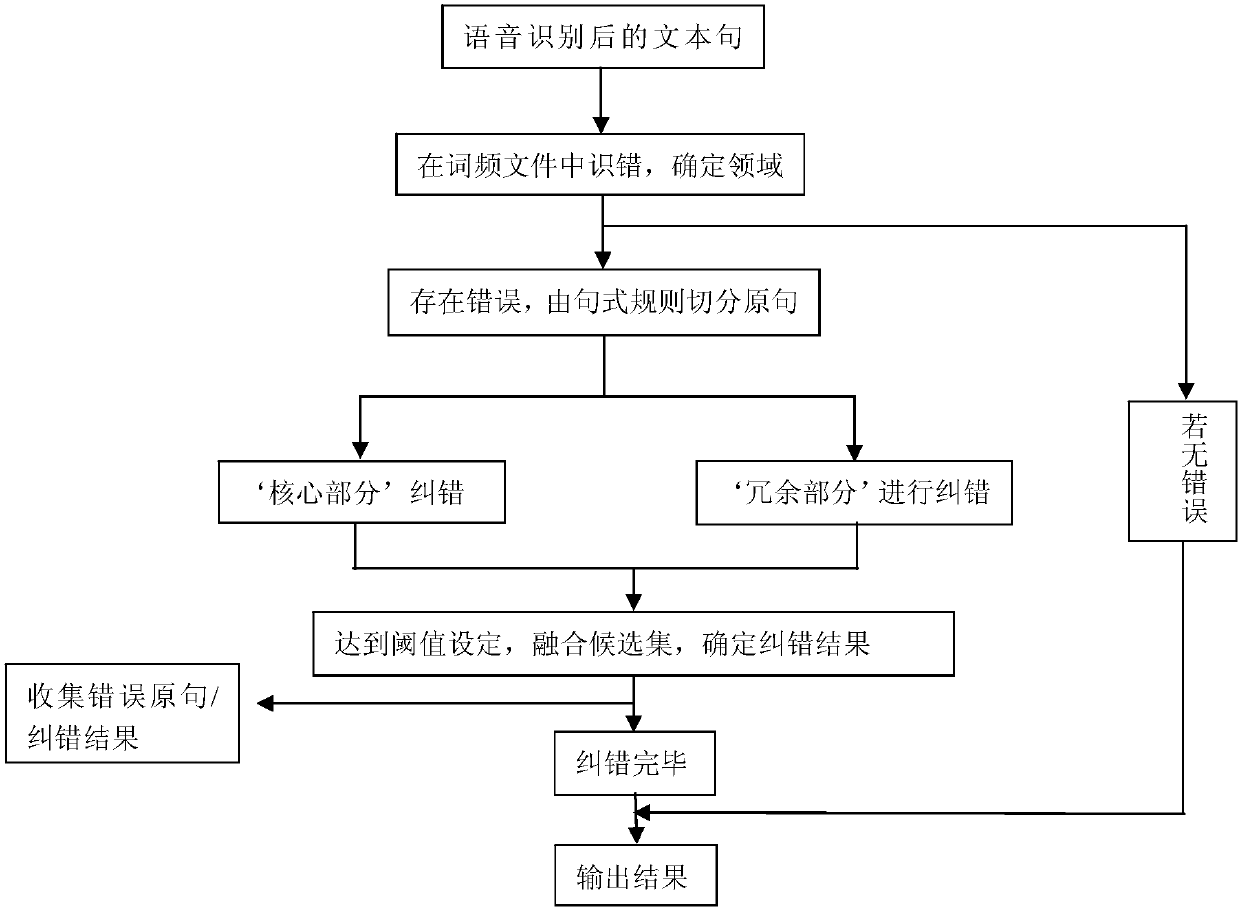
[0037] The present invention aims to propose a method for correcting text errors after speech recognition based on domain recognition, which solves the problems that the processing method in the traditional technology requires a lot of manual intervention, the error correction efficiency is low, and the proper name cannot be corrected.
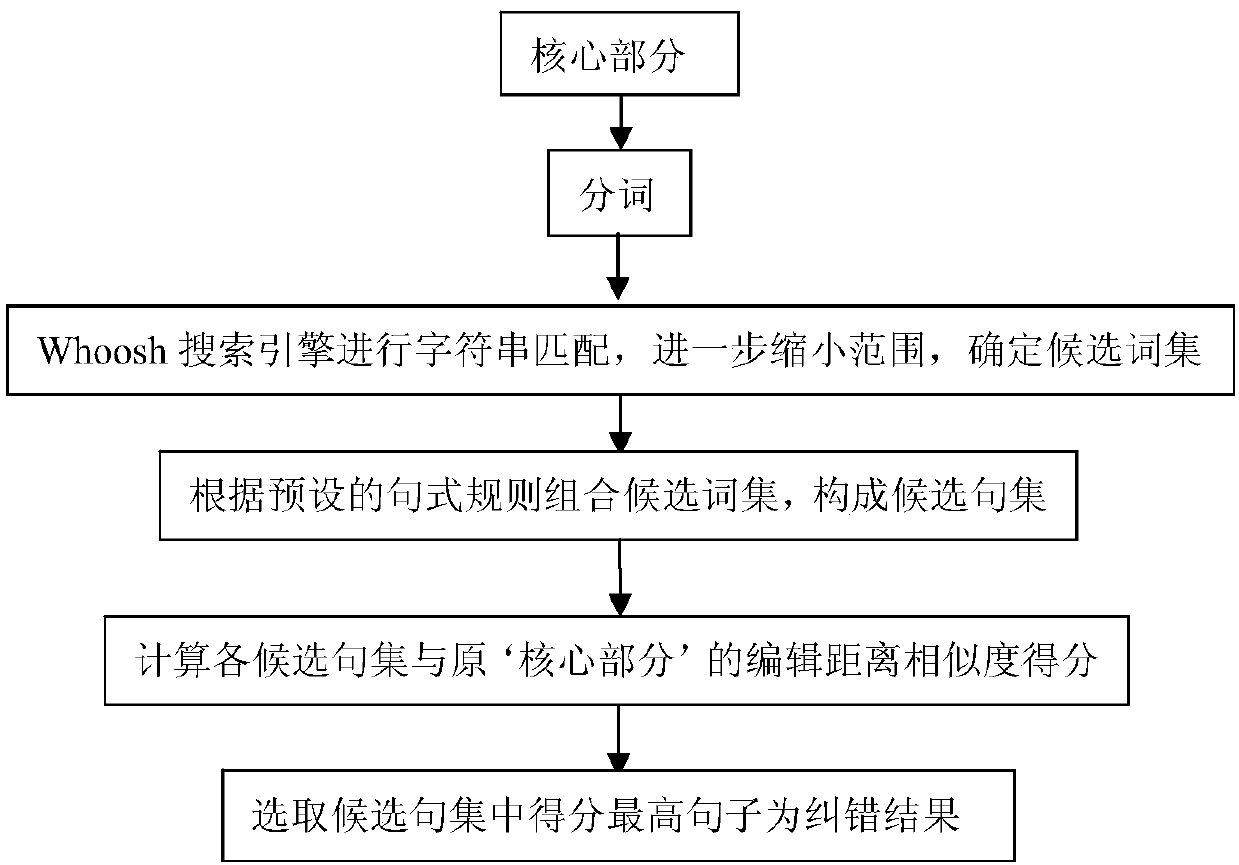
[0038] The invention adopts the Bigram model and the whoosh search engine to judge the field of the input text. By introducing the Markov hypothesis, Bigram solves the problems of sparse data and too large parameter space in n-grams. It is assumed that the appearance of a word only depends on the previous A word that appears, thereby establishing a relationship between words. The whoosh search engine helps to establish domain discrimination and builds an index according to the input text, which can quickly realize the candidate set recognition of fuzzy matching, and improve the speed of text error correction after multi-domain semantic recognit...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More