Distributed crawler method, electronic equipment and server
A distributed and server technology, applied in the field of crawler, can solve the problems of high cost, low efficiency, inability to effectively avoid the risk of being blocked and intercepted, and achieve the effect of avoiding interception and efficient crawling
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
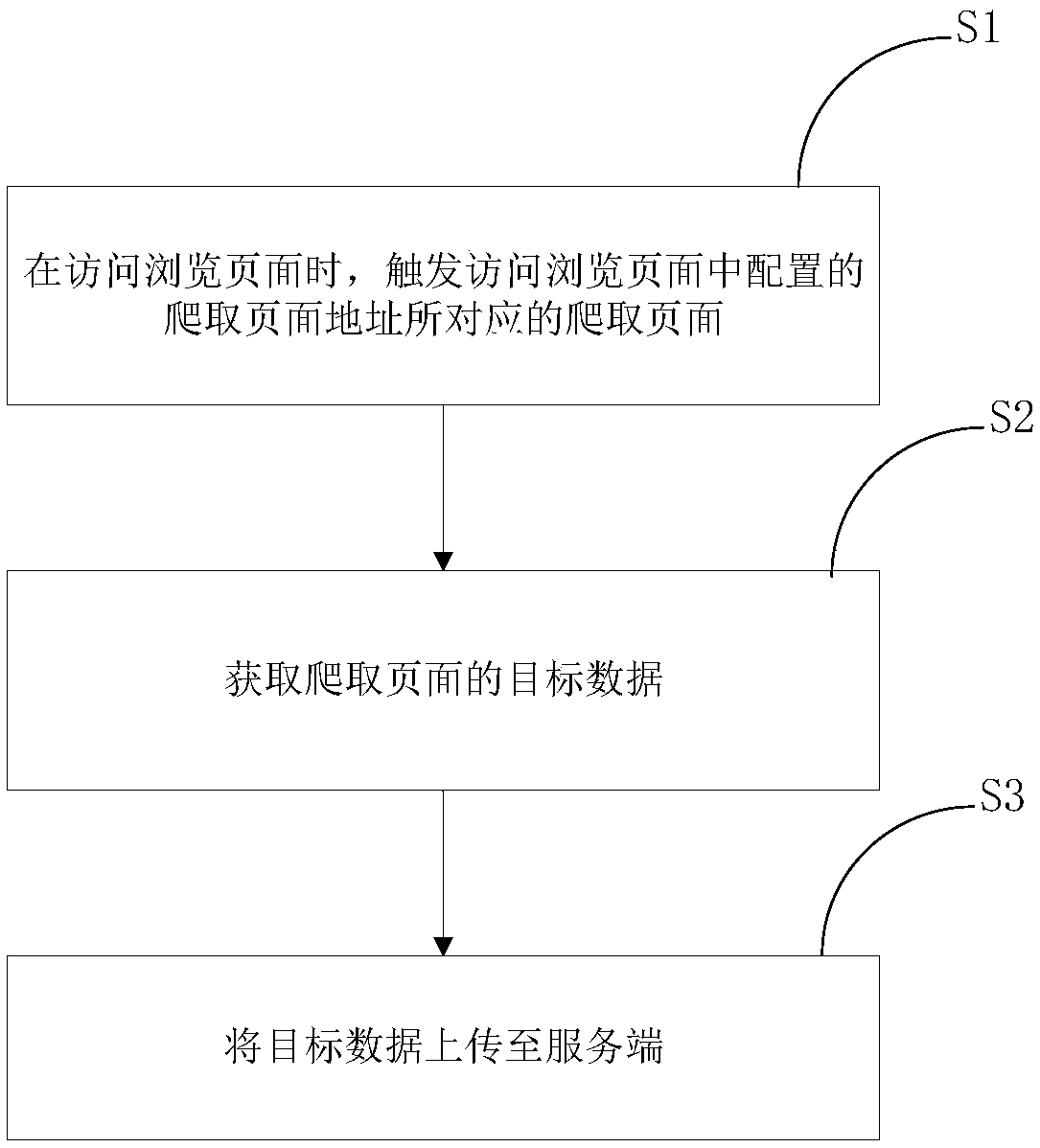
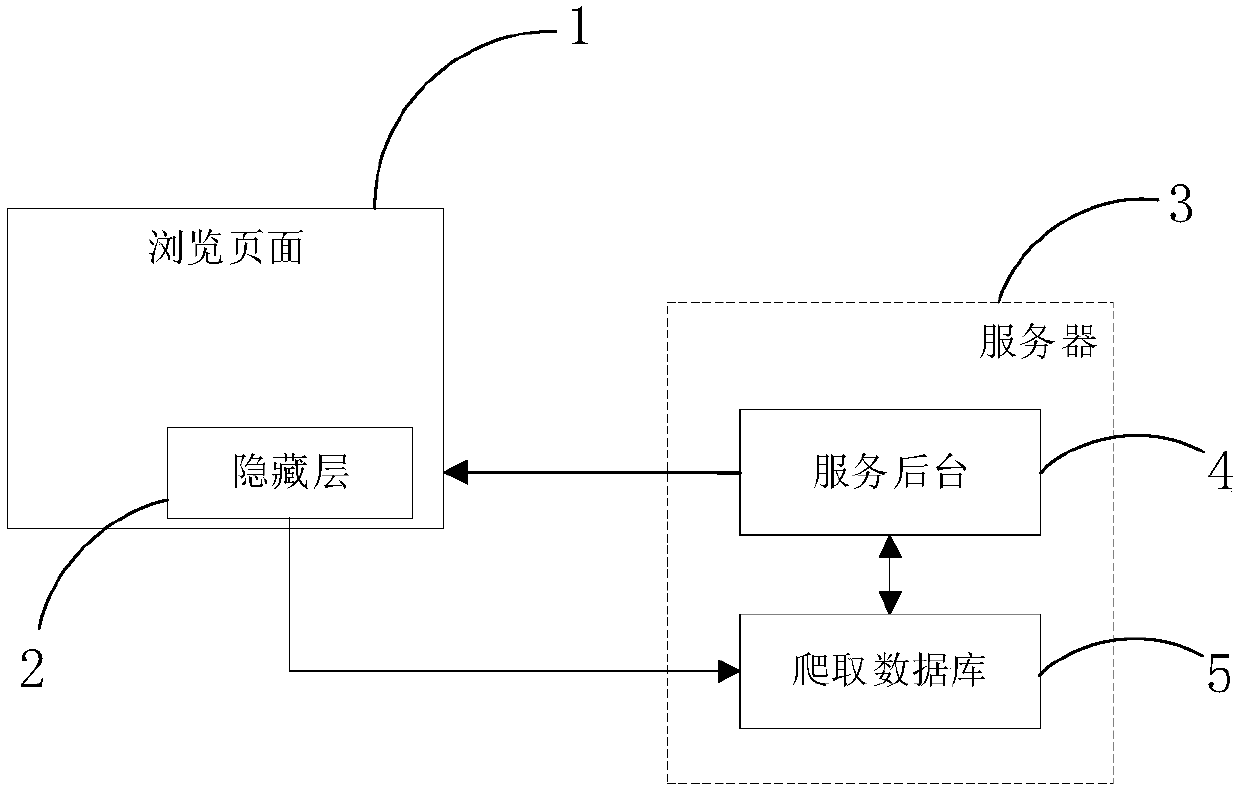
[0049] A distributed crawler method according to the embodiment of the present invention, a crawler is a program or script that automatically grabs information on the World Wide Web according to certain rules, and the crawler itself can be a terminal with a crawling program, or the crawling program itself etc., no limitation is made here. The crawler in this embodiment can prevent malicious blocking programs from blocking the operation of crawling pages of the crawler, such as figure 1 shown and combined with image 3 , the method includes the following steps:
[0050] S1, when browsing the browsing page 1, triggering access to the crawling page corresponding to the crawling page address configured in the browsing page 1. The user can use a terminal such as a computer to access the browsing page 1 that needs to be viewed, for example, use a computer to access the first site and view the browsing page 1 in the site, such as viewing the news page, entertainment page, etc. in t...
Embodiment 2
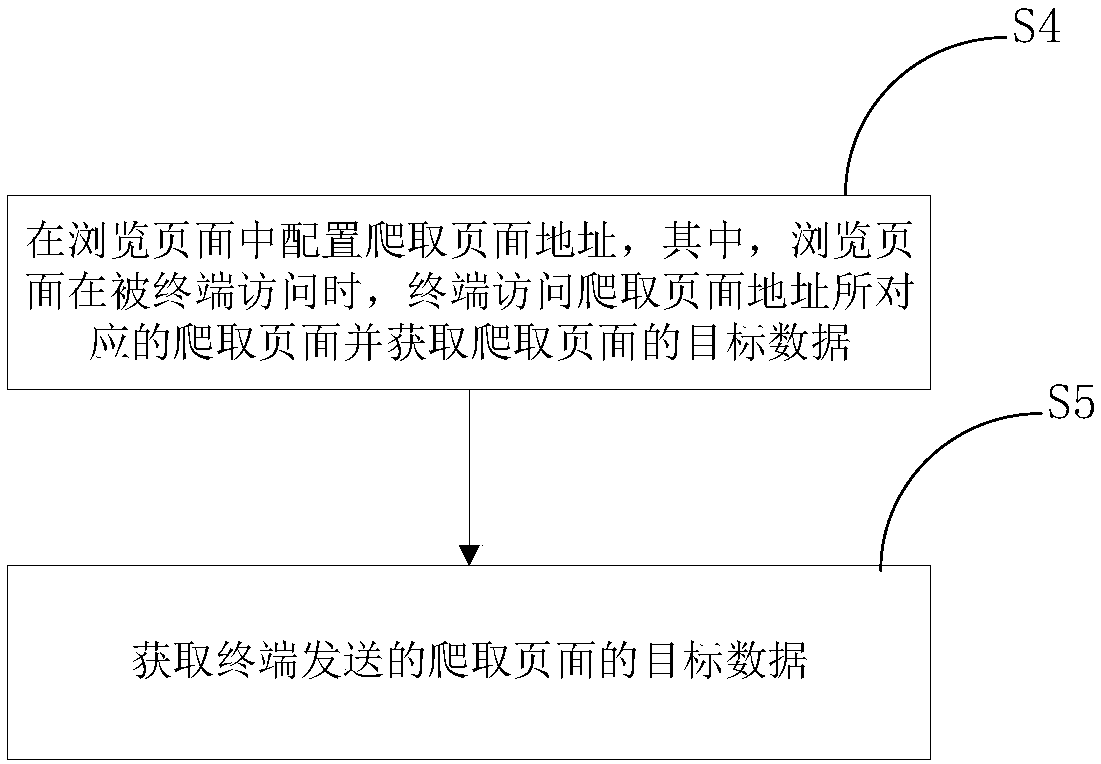
[0057] The embodiment of the present invention provides a distributed crawler method. A crawler is a program or script that automatically captures information on the World Wide Web according to certain rules. The crawler itself can be a terminal with a crawling program, or a crawling program. itself, etc., are not limited here. like figure 2 shown and combined with image 3 , the method includes the following steps:
[0058] S4. Configure the crawling page address in the browsing page 1, wherein, when the browsing page 1 is accessed by the terminal, the terminal accesses the crawling page corresponding to the crawling page address and obtains the target data of the crawling page. In one embodiment, the server (which may be server 3) can be used to configure the address of the crawled page in browsing page 1 through the network, so as to control the crawled pages that distributed crawlers need to crawl, such as modifying the The preset program set in the crawling page modif...
Embodiment 3
[0064] The present invention provides a distributed crawler device. The crawler is a program or script that automatically captures information on the World Wide Web according to certain rules. The crawler itself can be a terminal with a crawling program, or the crawling program itself, etc. It is not limited here. The device includes a trigger module, a first acquisition module and a communication module;
[0065] The triggering module is configured to trigger access to the crawled page corresponding to the crawled page address configured in the browsed page 1 when the browsed page 1 is accessed. The user can use a terminal such as a computer to access the browsing page 1 that needs to be viewed, for example, use a computer to access the first site and view the browsing page 1 in the site, such as viewing the news page, entertainment page, etc. in the site, in one embodiment Among them, when the user visits the browsing page 1, the triggering module can automatically trigger ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More