

Singing synthetic method for tone conversion
A technology of timbre conversion and synthesis method, applied in speech synthesis, speech analysis, instruments, etc., can solve problems such as difficult acquisition, poor generalization ability, inapplicable singing timbre conversion, etc., to achieve breakthrough dependence and good effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0022] The present invention will be further explained below in conjunction with the accompanying drawings and specific embodiments.
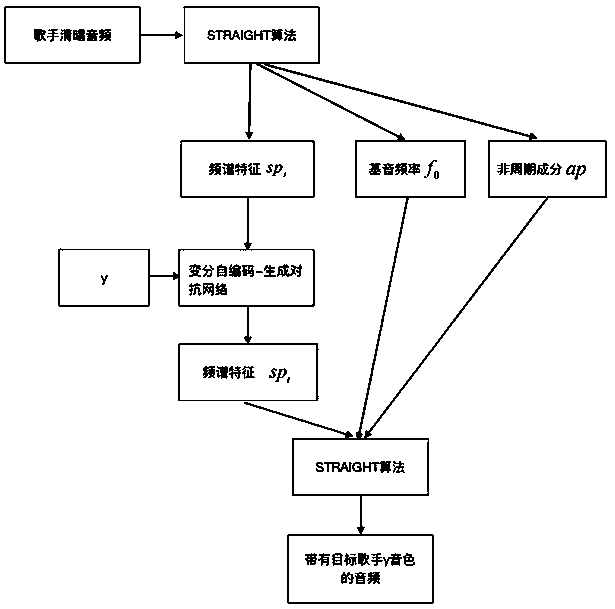
[0023] The present invention provides a singing voice synthesis method oriented to timbre conversion, such as figure 1 Shown include the following steps:
[0024] Step S1: Obtain the singer's cappella audio file, and use the STRAIGHT algorithm to extract its acoustic features;
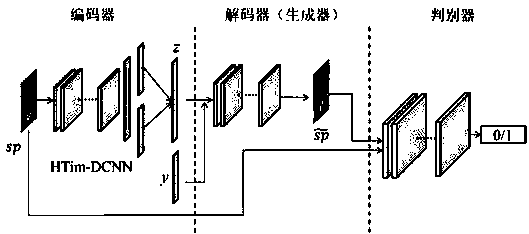
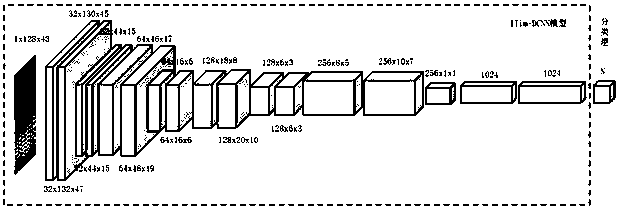
[0025] Step S2: Construct and train a variational autoencoder-generated confrontational network model to obtain a trained singing voice timbre conversion model;
[0026]Step S3: Obtain the a cappella audio file of the source singer, use the STRAIGHT algorithm to extract the acoustic features and input the singing voice timbre conversion model, the model output is the acoustic features after timbre conversion, and then use STRAIGHT to synthesize the acoustic features into the timbre converted singing voice.
[0027] In an embodiment of the present invention, the step S...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More