Video title generating method and device
A technology for video titles and titles, applied in the Internet field, can solve the problems of low video title generation efficiency, achieve the effects of improving generation efficiency, increasing information volume, and saving manpower and material resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

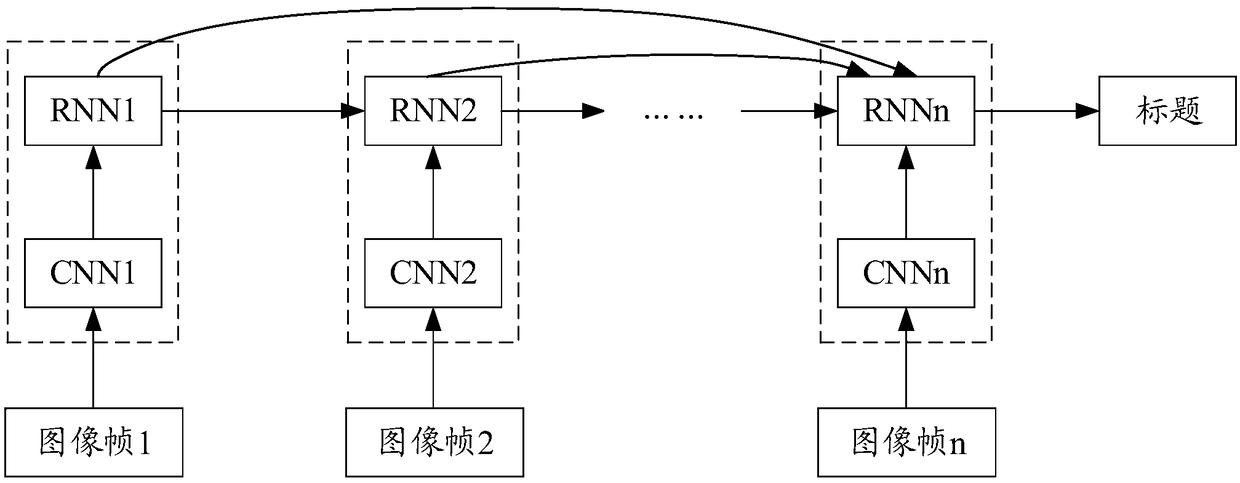
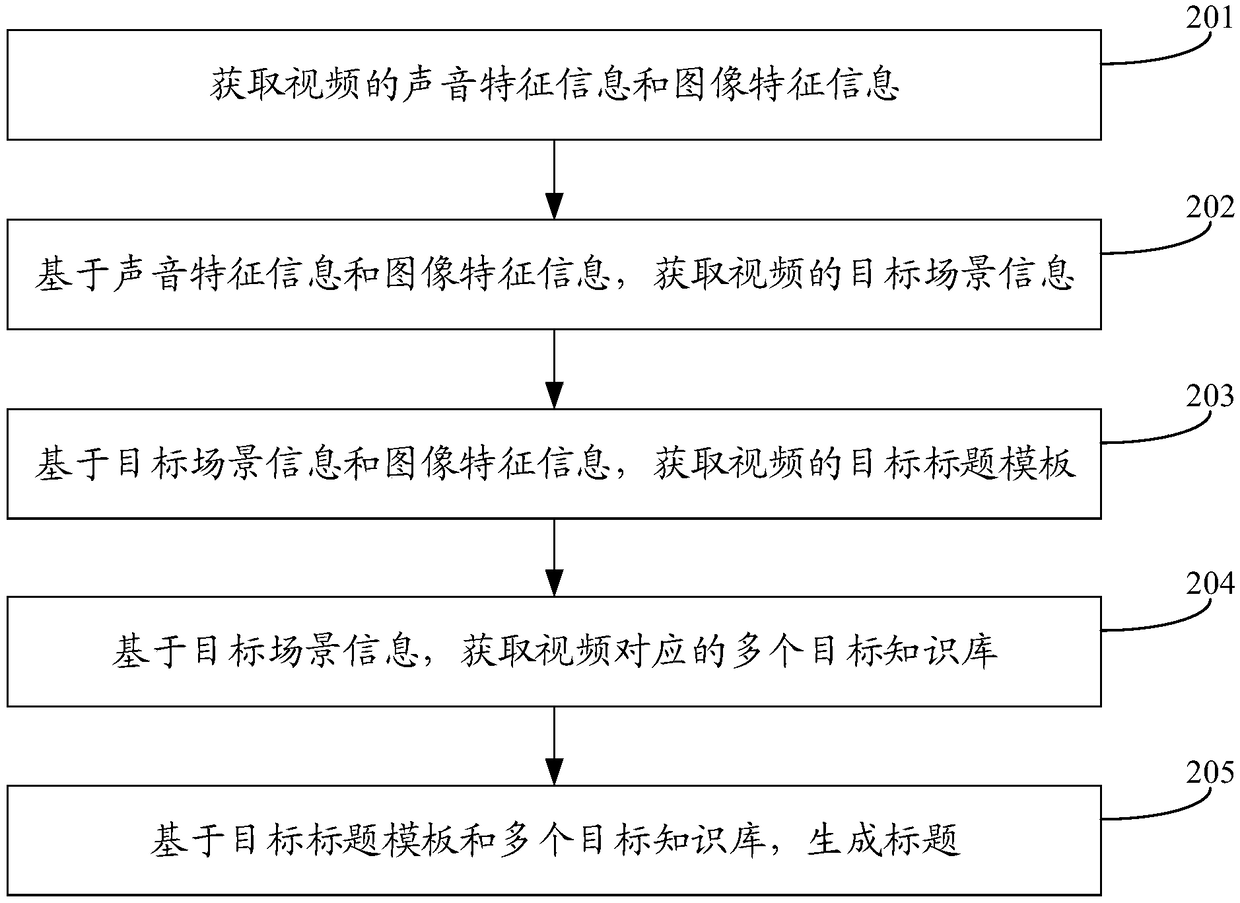

Examples
Embodiment Construction
[0036] In order to make the purpose, technical solution and advantages of the present application clearer, the implementation manners of the present application will be further described in detail below in conjunction with the accompanying drawings.
[0037] With the development of science and technology, more and more users acquire information by watching videos. Moreover, in order to meet the needs of different users, service providers generally provide a large number of videos for users to watch. Before watching a video, a user usually selects a desired video among a large number of videos provided by a service provider according to the title of the video. Therefore, the title of the video has an important impact on the viewing rate of the video. For example, in order to better maintain the game ecology and generate greater user stickiness, game service providers produce a large number of game videos every day for users to watch. Select the video you want to watch.
[00...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com