

A Speech Emotion Recognition Model and Recognition Method Based on Joint Feature Representation
A speech emotion recognition and joint feature technology, applied in speech analysis, instruments, etc., can solve the problems of low emotion recognition performance, poor speech emotion modeling ability, and insufficient use of the complementarity of different features, so as to enhance the description ability. , improve the generalization performance, reduce the effect of parameter redundancy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0057] Below in conjunction with the accompanying drawings, the present invention is further described by means of embodiments, but the scope of the present invention is not limited in any way.
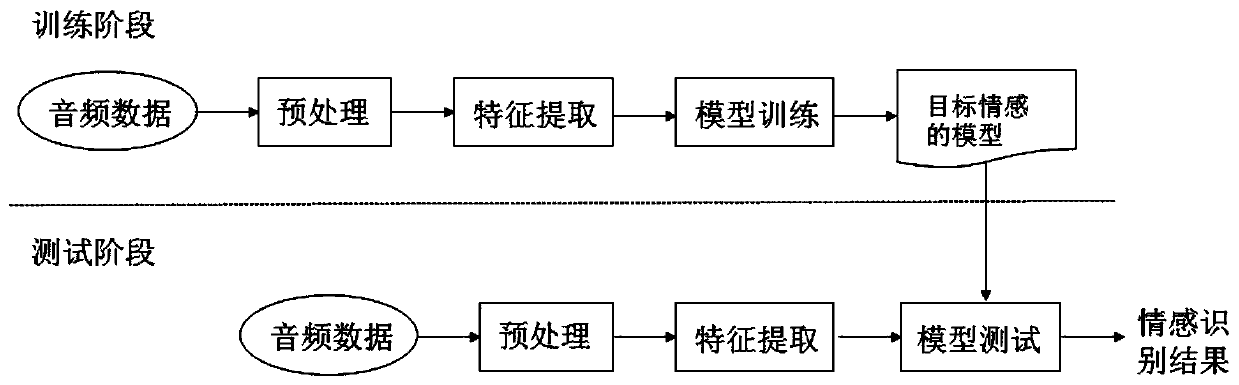
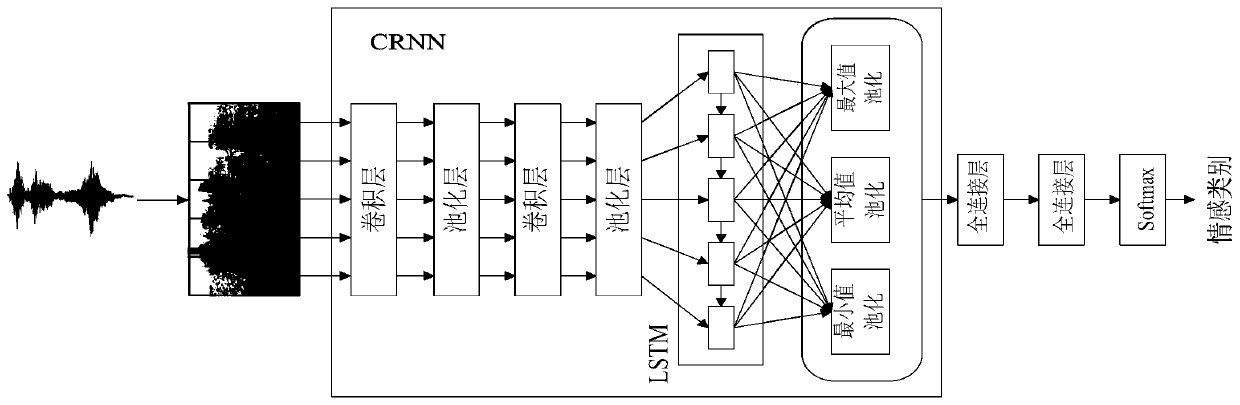
[0058] The present invention provides a speech emotion recognition method based on joint feature representation, the method flow is as follows figure 1 As shown, the convolutional cyclic neural network is improved. By fusing the deep features and manual features learned by the convolutional cyclic neural network from the spectrum, the two are mapped to the same feature space through the hidden layer for classification, making full use of the speech in speech. The emotional information carried can model the speech emotion more effectively, thereby improving the accuracy of speech emotion recognition.
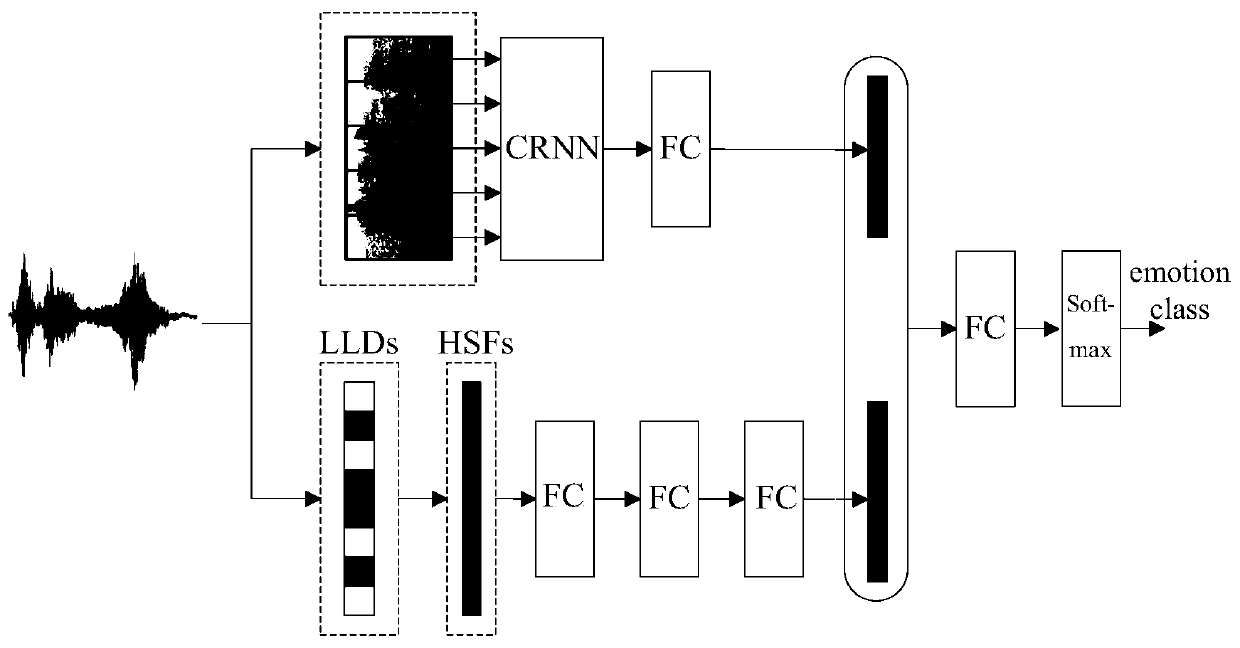
[0059] image 3 A structural block diagram of a joint feature representation-based speech emotion recognition model provided for implementing the present invention according to an examp...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More