

Real-time query method and system for large-scale knowledge map under memory constraint
A knowledge map and large-scale technology, applied in the field of data processing, can solve the problems of wasting user time, computing power cannot keep up with the growth rate of knowledge map, and difficult query processing, so as to reduce constraints and save query time.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
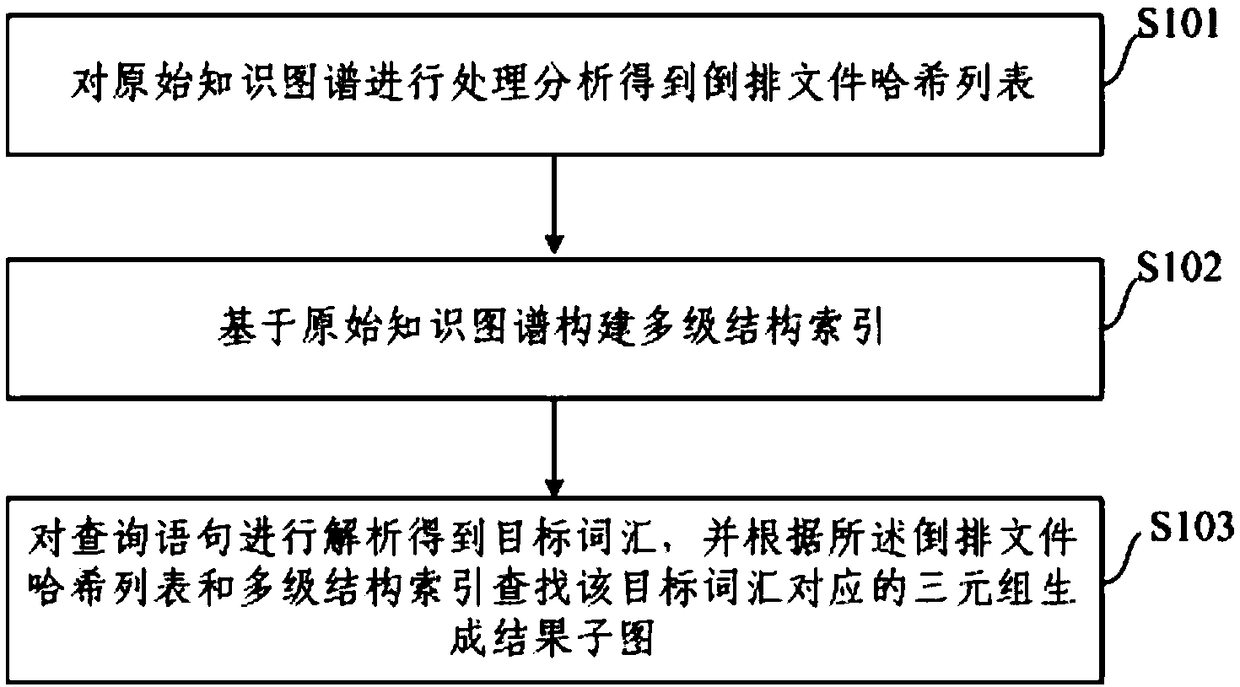
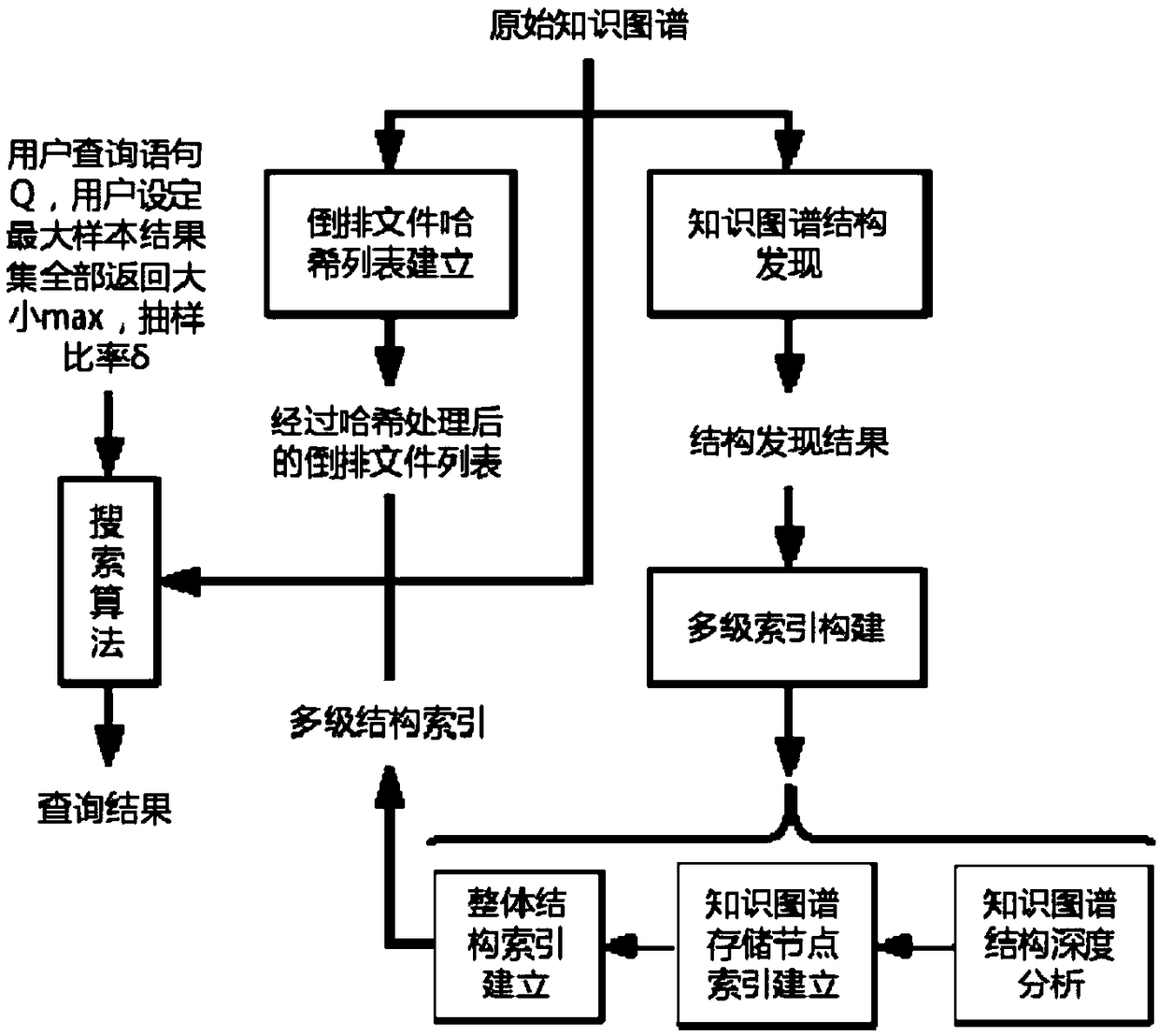
[0056] see figure 1 , which is a flow chart of a real-time query method for a large-scale knowledge map provided under memory constraints according to Embodiment 1 of the present invention; figure 2 It is a schematic diagram according to the principle of the present invention. As shown in the figure, the real-time query method of a large-scale knowledge map provided by the embodiment of the present invention may include the following steps:
[0057] Step S101: Execute the step of establishing the inverted file hash list, that is, process and analyze the original knowledge graph to obtain the inverted file hash list. Due to the high vocabulary repetition rate in non-numerical large-scale knowledge graphs, the use of inverted files can quickly locate triples based on vocabulary. The purpose of hashing inverted files is to speed up vocabulary search and reduce file I / O operate.
[0058] Step S102: Execute the step of building a multi-level structure index, and build a multi-l...
Embodiment 2
[0064] On the basis of the real-time query method of a large-scale knowledge map under the condition of limited memory provided in Embodiment 1, the process of processing and analyzing the original knowledge map in step S101 to obtain the hash list of the inverted file can be specifically implemented in the following manner :
[0065] Step 1: Extract the tuple information in the form of vocabulary first and then offset in the original knowledge graph. The first vocabulary and then offset form refers to the form of (offset, vocabulary, ..., vocabulary), that is, the tuple in the form of (offset, vocabulary, ..., vocabulary) extracted from the original knowledge graph in step 1 information.
[0066] Step 2: Convert the extracted tuple information into a form of vocabulary first and then offset. The first vocabulary and then the offset form refers to the form of (vocabulary, offset, ..., offset), that is, the tuple information in the form of (offset, vocabulary, ..., vocabulary...
Embodiment 3
[0078] On the basis of the real-time query method of large-scale knowledge graph under the condition of limited memory provided in Embodiment 2, the process of constructing a multi-level structure index based on the original knowledge graph in step S102 can be specifically implemented in the following manner:
[0079] The present invention separates the ontology layer of the original knowledge map to obtain a preliminary structure discovery, and then constructs a multi-level index structure, including three parts: deep analysis of the knowledge map structure, establishment of a knowledge map storage node index, and establishment of an overall structure index.
[0080] (1) In-depth analysis of knowledge graph structure: Data classification, cleaning, and simplified data representation are performed on the preliminary structure discovery results of knowledge graph to obtain data classification and simplification results of knowledge graph; the data simplified representation is to ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More