

Case text classification method, system and storage medium based on naive bayes
A text classification and Bayesian algorithm technology, applied in the case text classification method, system and storage medium field based on Naive Bayes, can solve the problems of large difference in the number of training set texts, uneven distribution of categories, etc., and achieve good results. The effect of the classification effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

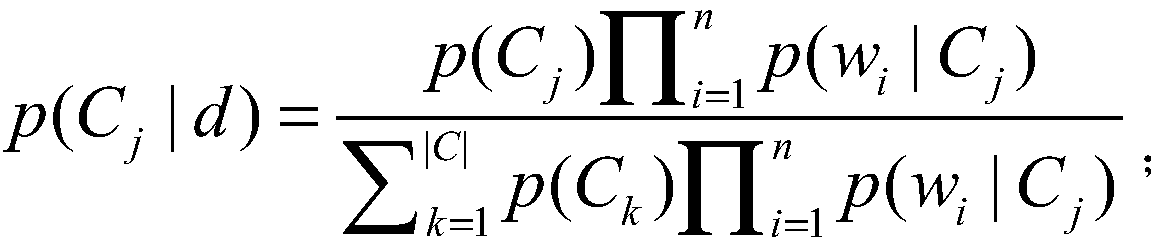
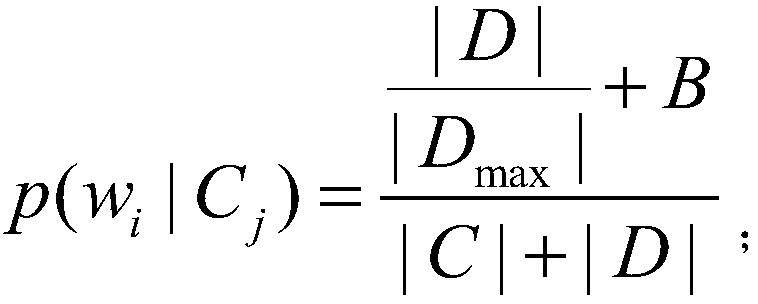
Examples
Embodiment Construction
[0050] The present invention will be further described below in conjunction with the accompanying drawings and specific embodiments.
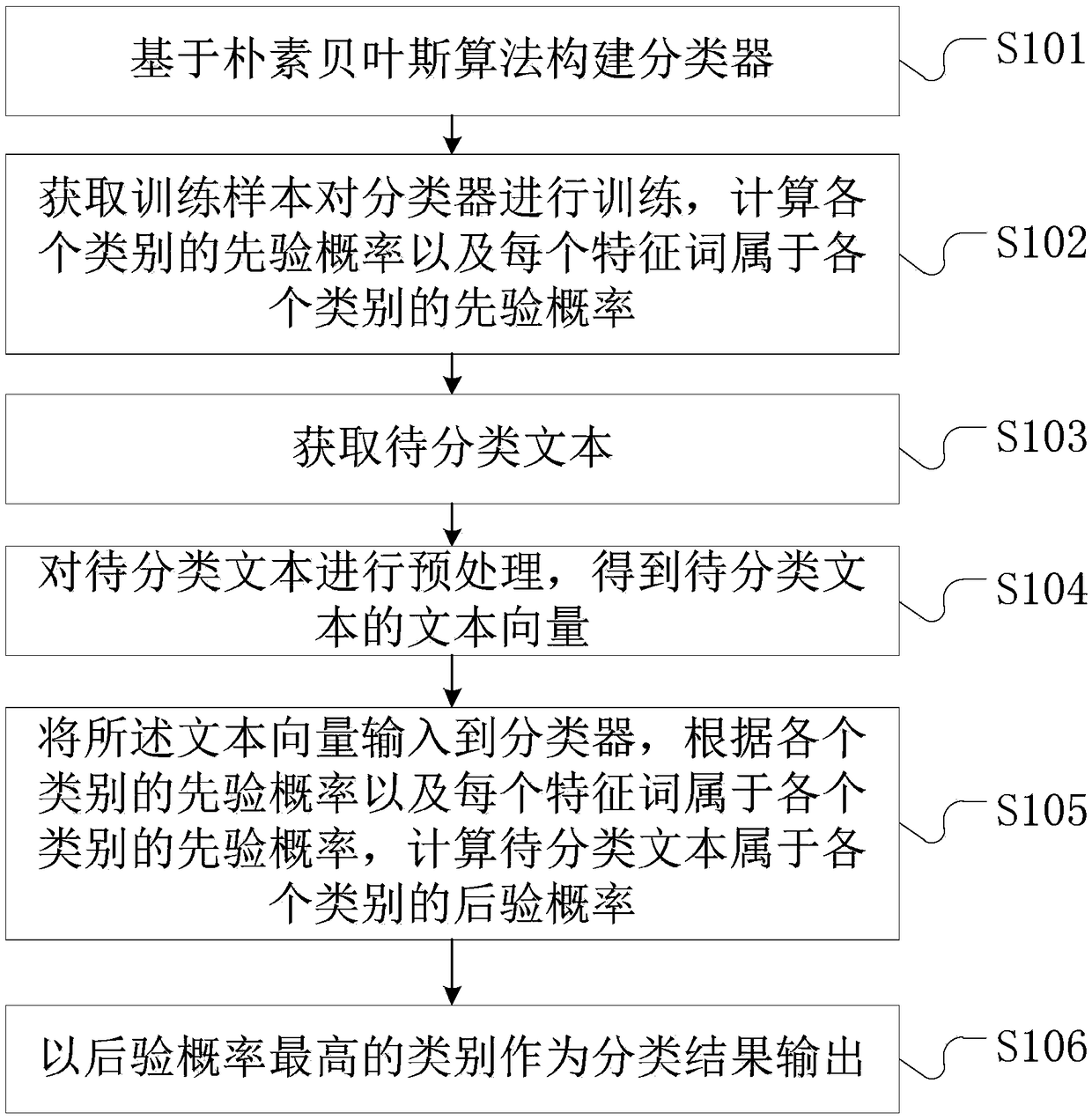
[0051] refer to figure 1 , a case text classification method based on Naive Bayes, including the following steps:
[0052] S101. Construct a classifier based on the naive Bayesian algorithm.
[0053] S102. Obtain training samples to train the classifier, and calculate the prior probability of each category and the prior probability of each feature word belonging to each category. The training samples can be processed training samples or unprocessed training samples. If unprocessed training samples are used, the training samples need to be preprocessed in step S104.
[0054] S103. Obtain the text to be classified. The text to be classified is the original text and has not been processed, so it needs to be processed in step S104.
[0055] S104. Perform preprocessing on the text to be classified to obtain a text vector of the text to be classi...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More