Method and apparatus for processing high concurrency query requests
A query request and processor technology, applied in the field of data processing, can solve problems such as reducing the efficiency of query results and wasting processing resources
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0069] Exemplary embodiments of the present invention will be described in more detail below with reference to the accompanying drawings. Although exemplary embodiments of the present invention are shown in the drawings, it should be understood that the invention may be embodied in various forms and should not be limited to the embodiments set forth herein. Rather, these embodiments are provided for more thorough understanding of the present invention and to fully convey the scope of the present invention to those skilled in the art.
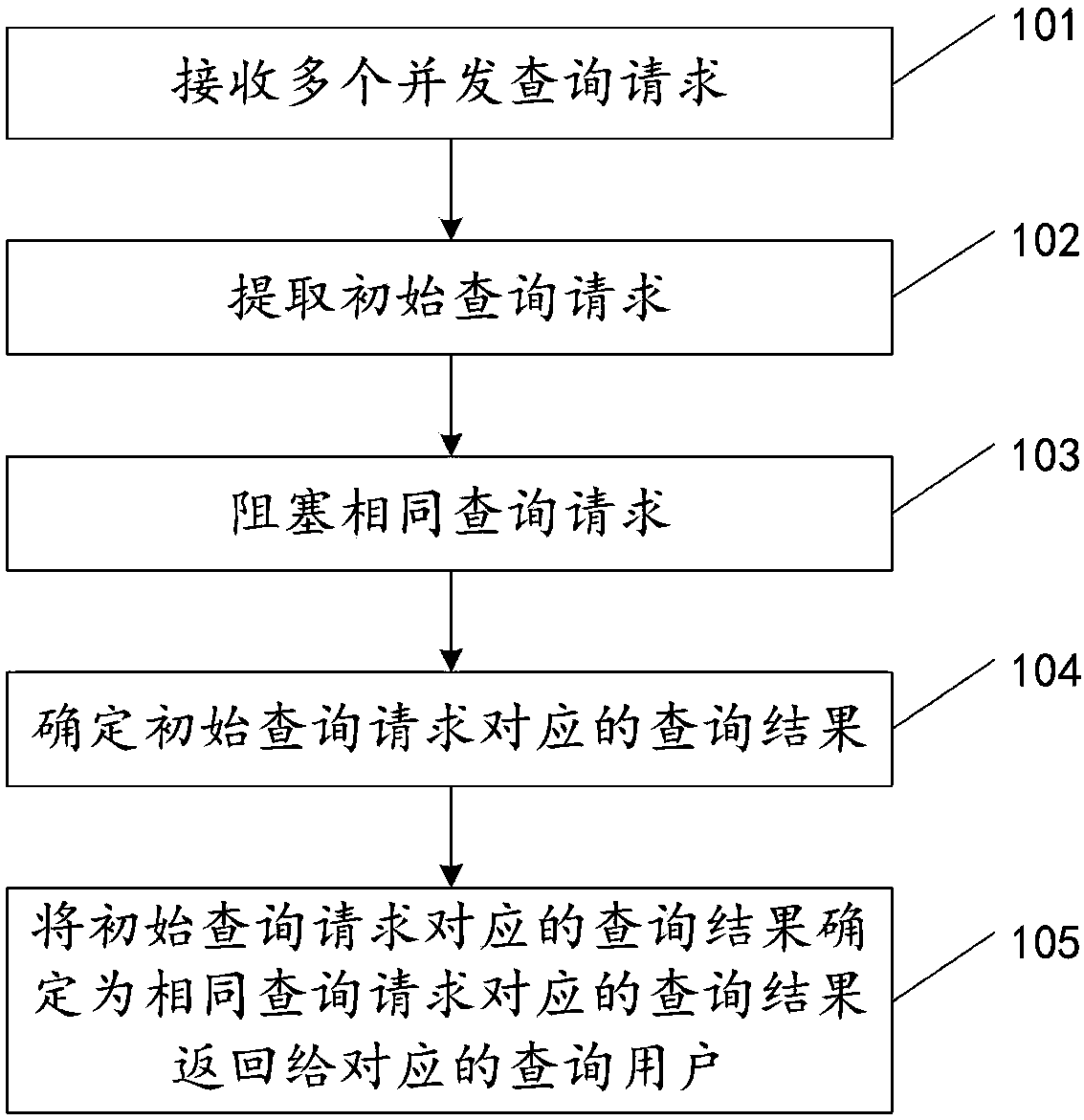
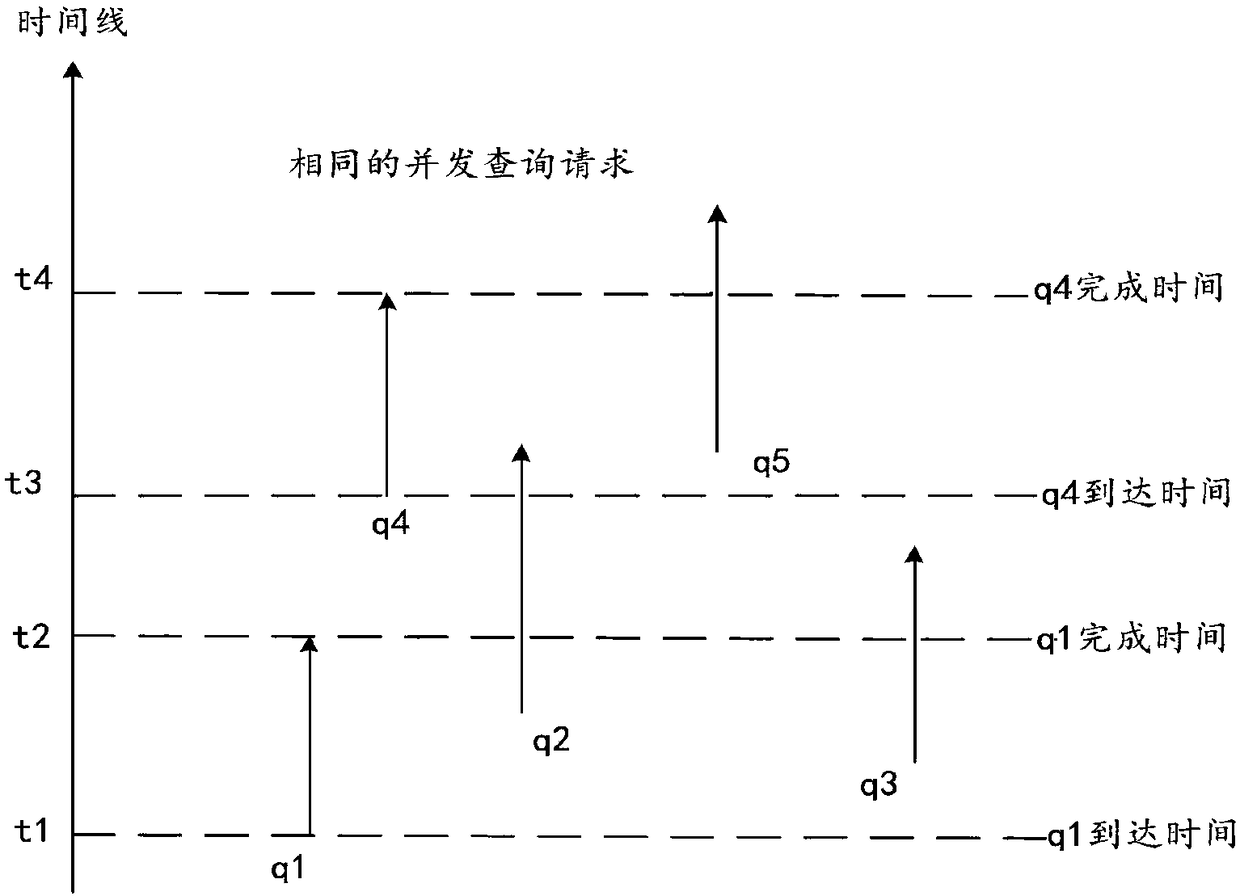
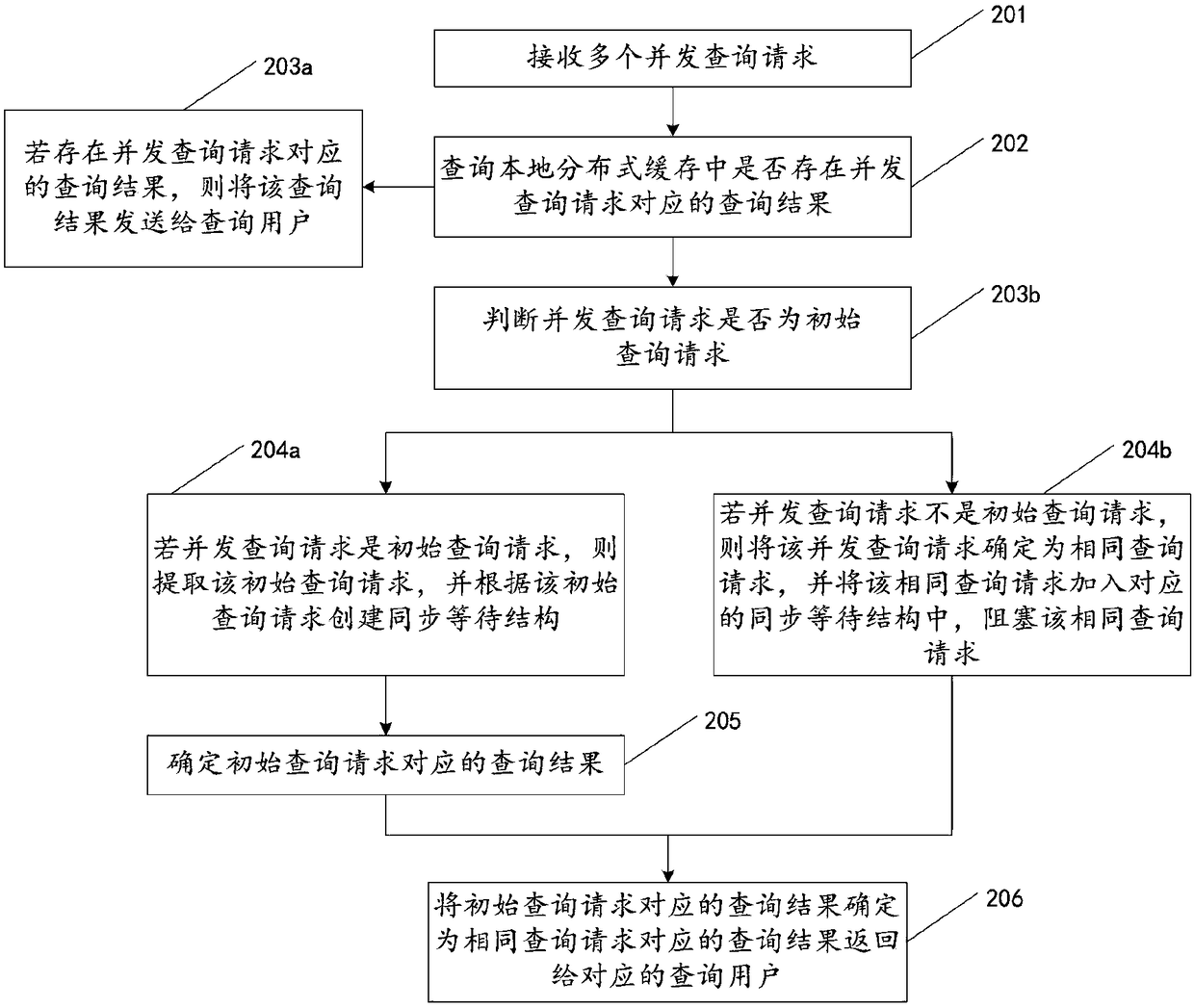
[0070] The embodiment of the present invention provides a method for processing high concurrent query requests, such as figure 1 As shown, the method is to determine the initial query request contained in multiple concurrent query requests received within a period of time and the same query request corresponding to the initial query request, and execute the initial query request, and convert the initial query request corresponding to As a resul...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



