

Data processing method, system and device based on tagSQL
A technology of data processing and Hadoop cluster, applied in the field of big data, can solve problems such as lack of mastery of the interface language, programmers unable to quickly carry out big data development work, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0044] The present invention will be further described in detail below in conjunction with the accompanying drawings and specific embodiments. For the step numbers in the following embodiments, it is only set for the convenience of illustration and description, and the order between the steps is not limited in any way. The execution order of each step in the embodiments can be adapted according to the understanding of those skilled in the art sexual adjustment.
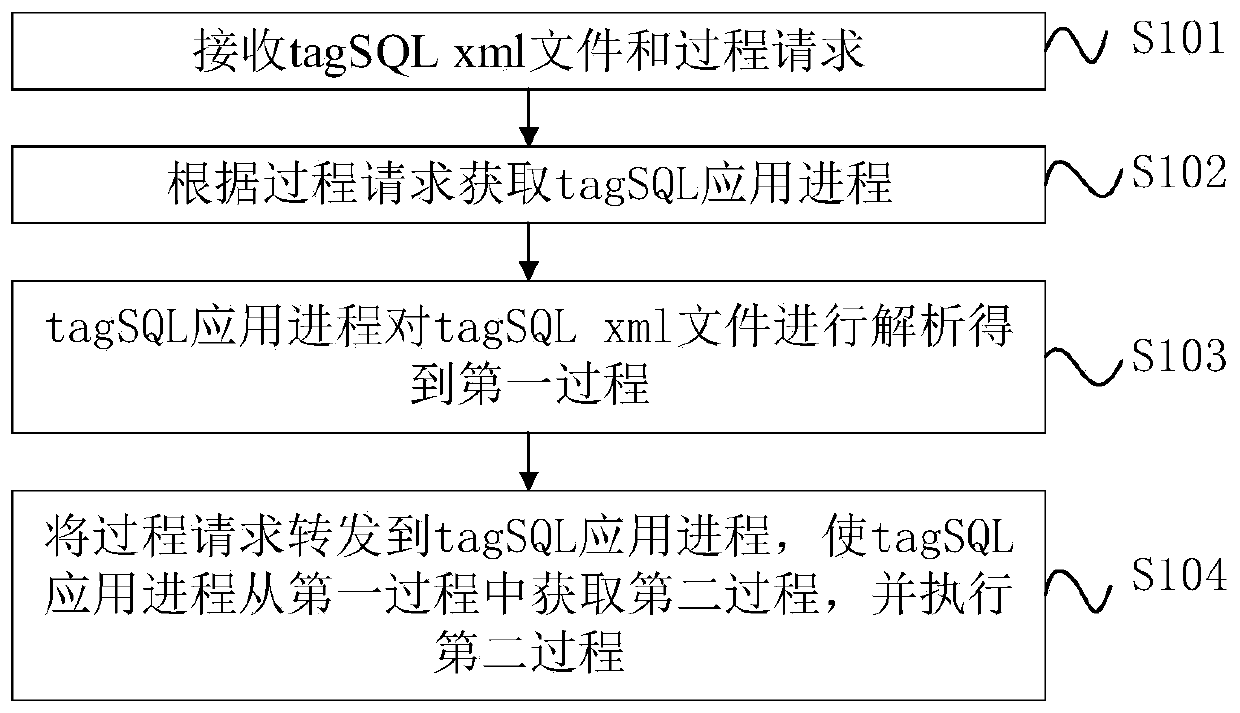
[0045] refer to figure 1 , a data processing method based on tagSQL, comprising the following steps:
[0046] S101. Receive tagSQL xml file and process request;
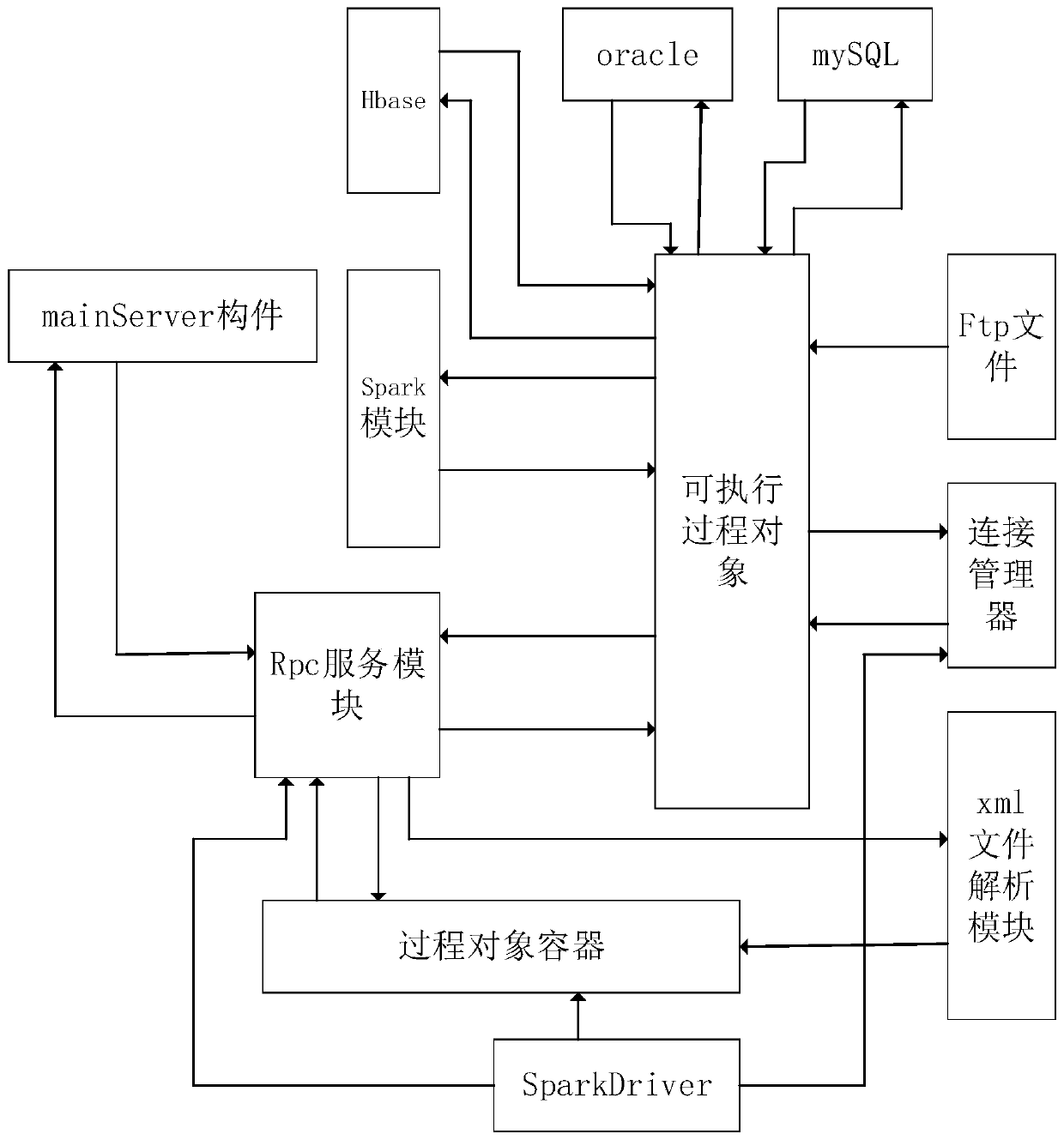
[0047] Specifically, the tagSQL is a tagged SQL language. The tagSQL xml is a file formed by tag SQL language. Send tagSQL xml files and process requests through kettle (an open source ETL scheduling tool) or tagSQLDevTool (debugging tool). mainServer (server) receives tagSQL xml files and process requests sent by kettle or tagSQLDevTool. Among them, k...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More