Abnormal network flow detection method based on automatic coding
A network traffic and automatic coding technology, applied in the field of network security, can solve problems such as insufficient recognition rate, low efficiency in processing massive data, poor adaptive ability, etc., to improve accuracy and precision, reduce training and testing time, The effect of delay time
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
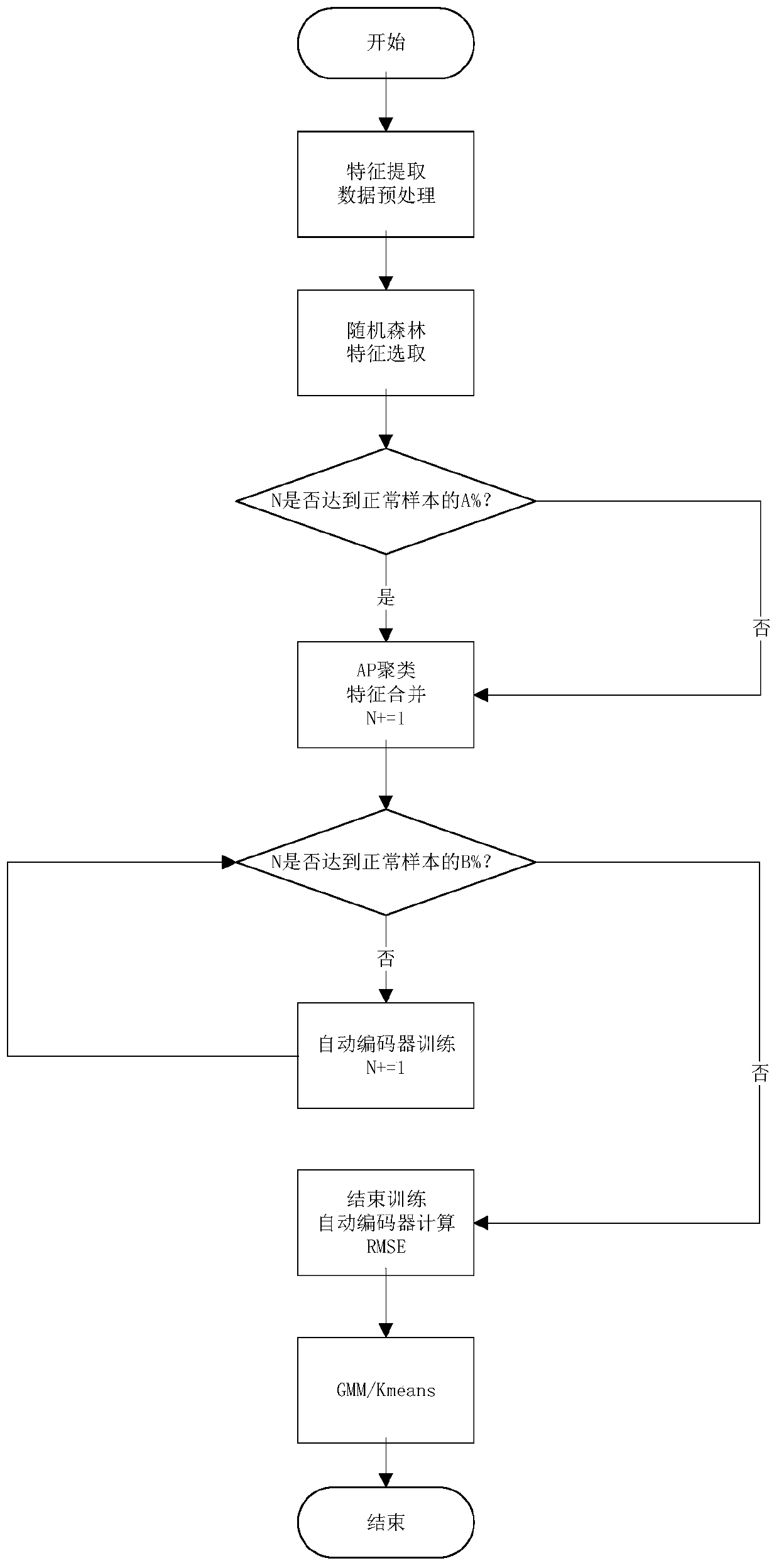
[0046] A method for detecting abnormal network traffic based on automatic coding, said method comprising the steps of:
[0047] Step 1 extracts effective features from the original features; specifically, extracts features from the network traffic packet pcap, stores them in a file using pandas.DataForm, performs advanced feature extraction operations, and adds them to the original features to obtain a new data set; Build 1,000 decision trees to build a random forest algorithm. Each tree in the random forest is sampled with replacement from the original data set to construct a sub-dataset; use the sub-dataset to build a sub-decision tree, and the sub-data The set is placed in each sub-decision tree, and each sub-decision tree outputs a result; by voting on the judgment results of the sub-decision tree, the output result of the random forest is obtained; for the decision tree T in the random forest, it is calculated that it is outside its own bag (out of bag) the number of clas...
Embodiment 2
[0052] The overall thinking of the present invention is, firstly carry out effective feature selection to original feature by random forest algorithm, then use Affinity Propagation clustering algorithm (AP) to compare the similarity of the best feature with the normal data of feature selection, Find the features with strong correlation, and then use AutoEncoder as the network structure, use the three-layer network structure and fewer parameters to reconstruct the new data, so as to calculate the root mean square error between the original data and the dimensionality reduction data (RMSE). During this period, we also use the extreme learning machine to optimize the weight and bias, so that the difference between the normal sample and the reconstructed data is equal to 0, so that our model has good expressive ability in the training phase. Finally, in the test phase, we only need to input the data that has been selected through the feature into our model to calculate the root me...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More