Chinese microblog topic detection method and system based on semanteme, time and social relation
A technology for social relations and microblog topics, applied in the field of natural language processing and information retrieval, it can solve the problems of short text, polysemy topic detection results, dimension disaster, etc., to speed up microblog search and shorten microblog search time , the effect of improving user experience
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

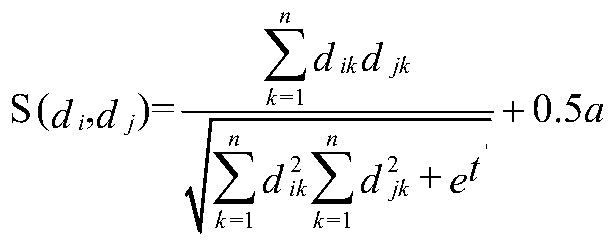
Examples
Embodiment 1
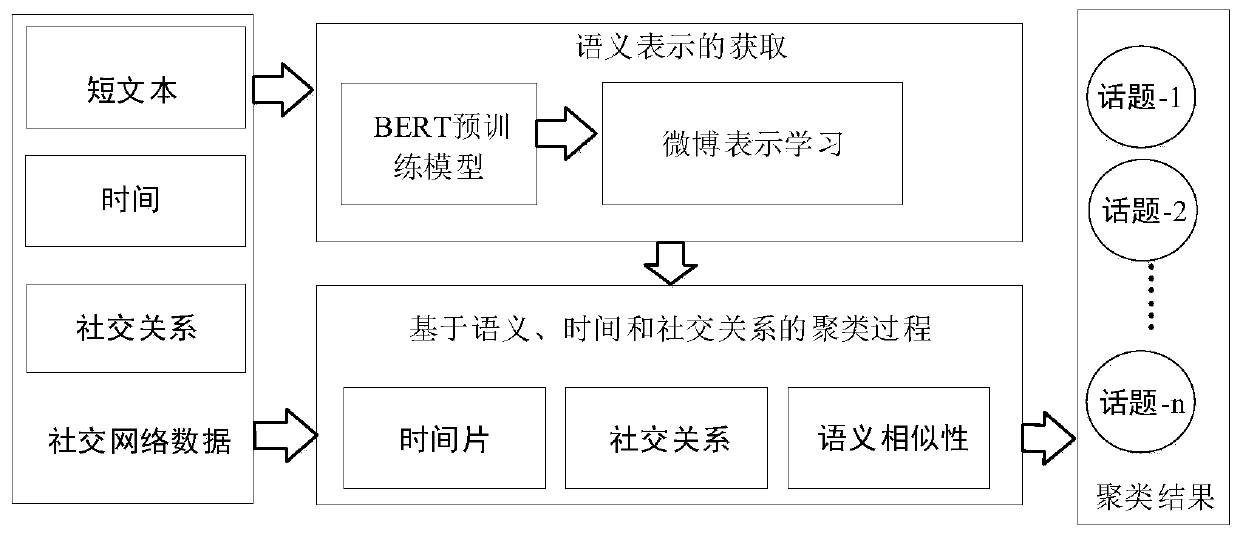
[0034] This embodiment provides a Chinese microblog topic detection method based on semantics, time and social relations, which is used for the identification and acquisition of Chinese microblog topics, such as figure 1 As shown, the method includes the following steps:
[0035] S1: Preprocessing of Weibo data: Remove invalid information, useless characters and stop words in the text of the existing Weibo data set, and construct the input of the pre-trained language model BERT (Bidirectional Encoder Representation from Transformers), that is, the Weibo data Preprocess into a text font
[0036] The microblog data is stored in the MySQL database, and the text of the microblog is used as subsequent input, and each microblog is processed as a string. Use the tool to separate the words in each microblog with spaces, and store each microblog in a list; remove the stop words from the microblogs separated by spaces, and judge each microblog in turn after reading the stop word list ...
Embodiment 2
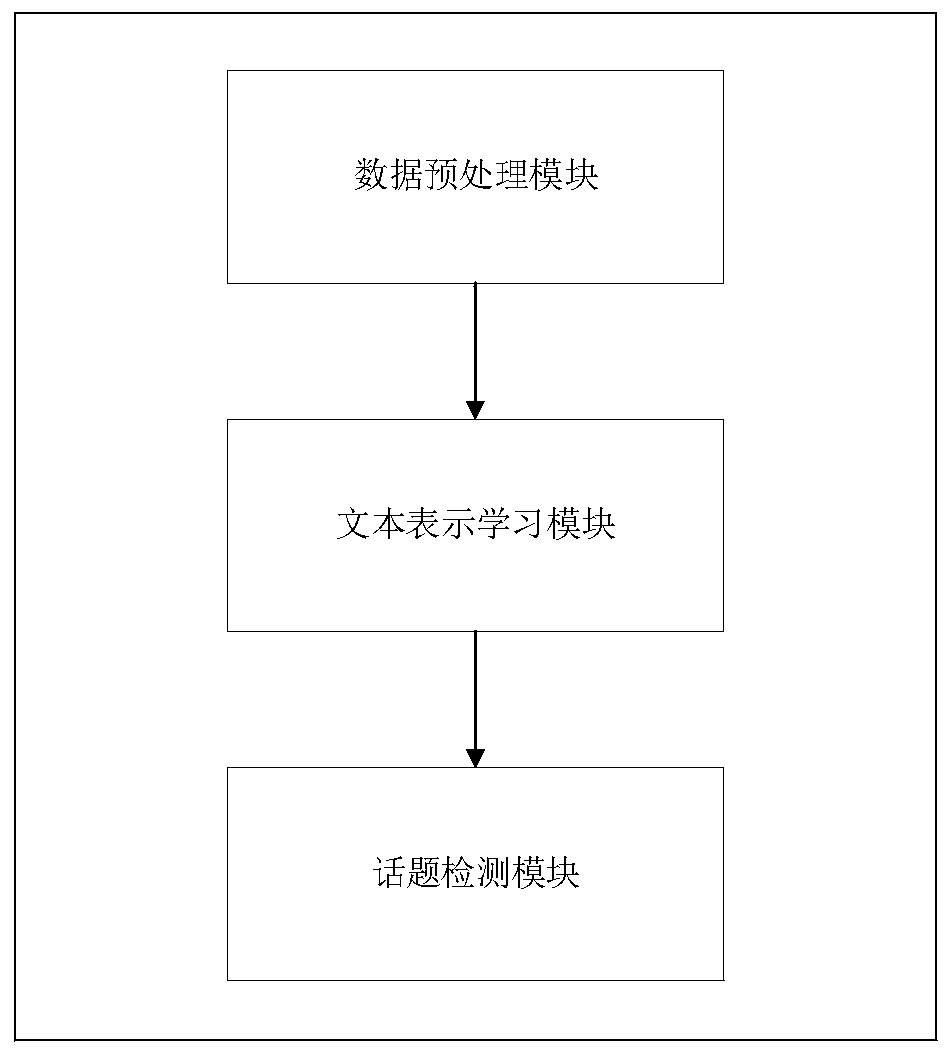
[0060] The present invention proposes a Chinese microblog topic detection system based on semantics, time and social relations, which includes three modules such as figure 2 Shown:
[0061] Data preprocessing module: remove invalid information, useless characters and stop words in the text of the existing microblog dataset, and construct the input of the pre-trained language model BERT (Bidirectional Encoder Representation from Transformers), that is, preprocess the microblog data into text word set.
[0062] Text representation learning module: This invention proposes to use a powerful pre-training model to learn the semantic representation of Chinese microblog short texts. Use the preprocessed microblog text word set to pre-train the BERT model, and through the BERT model based on the MLM (Masked Language Model) training mechanism, the microblog text vector representation with rich semantic information can be obtained.
[0063] Topic detection module: use the proposed tex...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com