Stadium auxiliary training method and system
A technology for sports venues and training methods, applied in the field of sports training methods and systems, can solve problems such as lack, and achieve the effect of convenient training
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
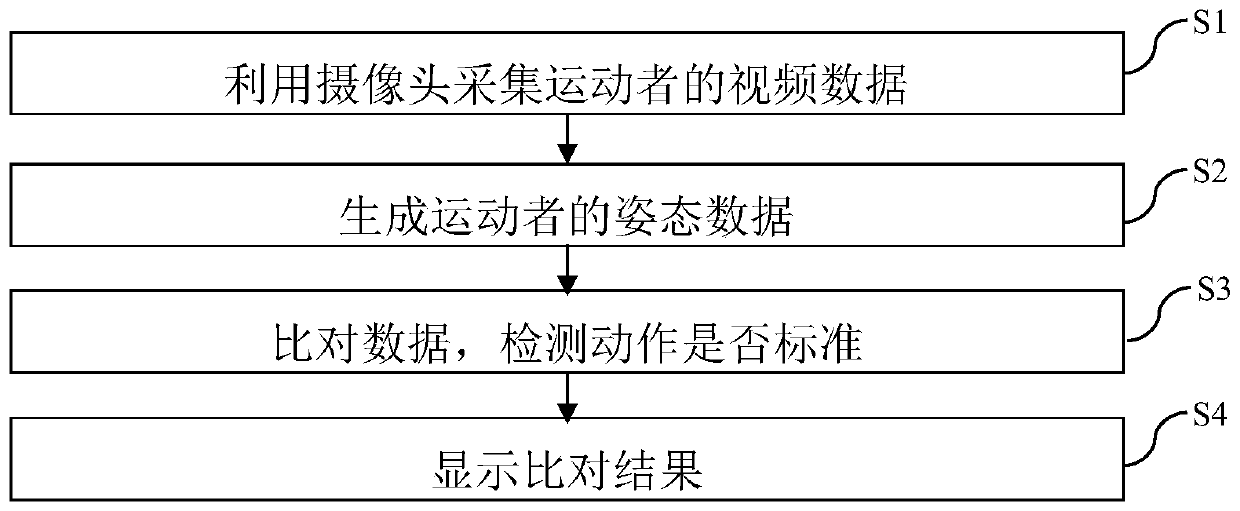
[0043] Embodiment 1 provides a kind of gymnasium auxiliary training method, as figure 1 shown, including the following steps:
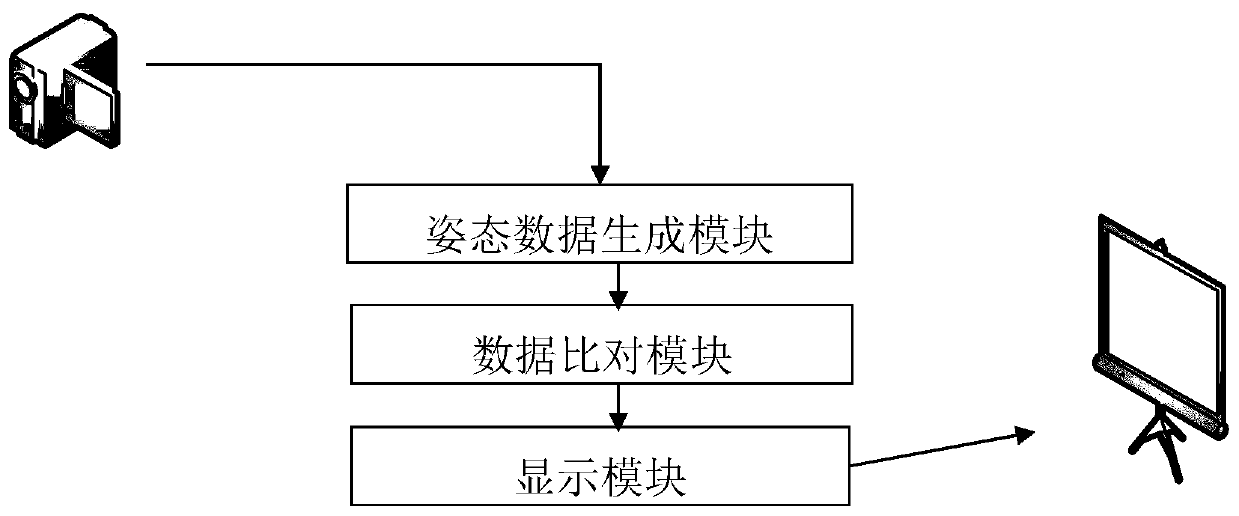
[0044] S1. Use the camera to collect the video data of the athlete;
[0045] S2. Detect the skeletal joint points of the human body from the video data, and generate posture data of the athlete;
[0046] S3. Using the preset standard skeletal joint point posture data to compare with the athlete's skeletal joint point posture data to detect whether the movement of the athlete is standard;
[0047] S4. When the movement of the athlete is not standard, replay the movement of the athlete on the display screen, and mark the nonstandard position.
[0048] The traditional key point detection of human skeleton adopts the method of template matching to detect the skeleton joint points and limb structure of the human body. However, if the detected skeletal joint points do not contain depth information, it will be difficult to perform accurate analysis and ev...
Embodiment 2
[0052] Embodiment 2 and Embodiment 3 provide two different methods for obtaining depth information of skeletal joint points. Embodiment 2 At least two cameras are arranged in the stadium, and step S22 calculates the depth data of the bone joint points through the video data of more than two viewing angles.
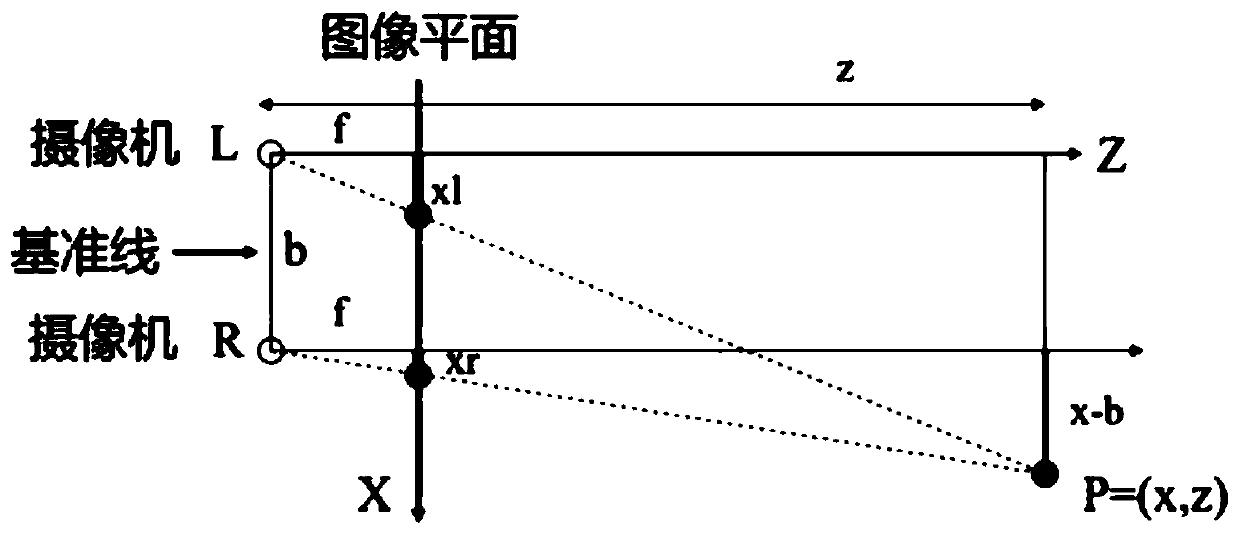
[0053] Depth estimation generally requires binocular positioning in three-dimensional space, because the image seen by a single eye is two-dimensional, and two-dimensional information cannot be used to represent three-dimensional space, that is, the offset generated by the position far away from the camera is small, and the position close to the camera The offset produced by the position is larger. The existence of this difference is brought about by the three-dimensional space. The geometric law when two cameras shoot video on the same horizontal line is as follows: image 3 shown.
[0054] The depth of the scene is represented by z; the three-dimensional scene is mappe...
Embodiment 3
[0058] Embodiment 3 only deploys one camera, and calculates the depth data of skeletal joint points through monocular video, and the specific method is:
[0059] S221, using the one-side image of the binocular video as an input for training, and using the other-side image as a reference standard, to establish a neural network;
[0060] S222. Perform binocular video training on the data through the neural network, and obtain a neural network function for predicting the corresponding image on the other side through the input image;
[0061] S223. Input monocular video data, and use the neural network function to obtain the image on the other side corresponding to each frame of image, thereby converting the monocular video data into binocular video data;
[0062] S224. Calculate depth data of skeletal joint points through the binocular video data.
[0063] Suppose we have a very powerful function F, use the left image as the training input, and the right image as the corresponding...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More