

Periodical literature table extraction method based on text state characteristics
A state feature and table technology, which is used in text database query, unstructured text data retrieval, special data processing applications, etc. Applicability, effect of correct extraction
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0048] In order to make the object, technical solution and advantages of the present invention clearer, preferred embodiments are given to further describe the present invention in detail. However, it should be noted that many of the details listed in the specification are only for readers to have a thorough understanding of one or more aspects of the present invention, and these aspects of the present invention can be implemented even without these specific details.
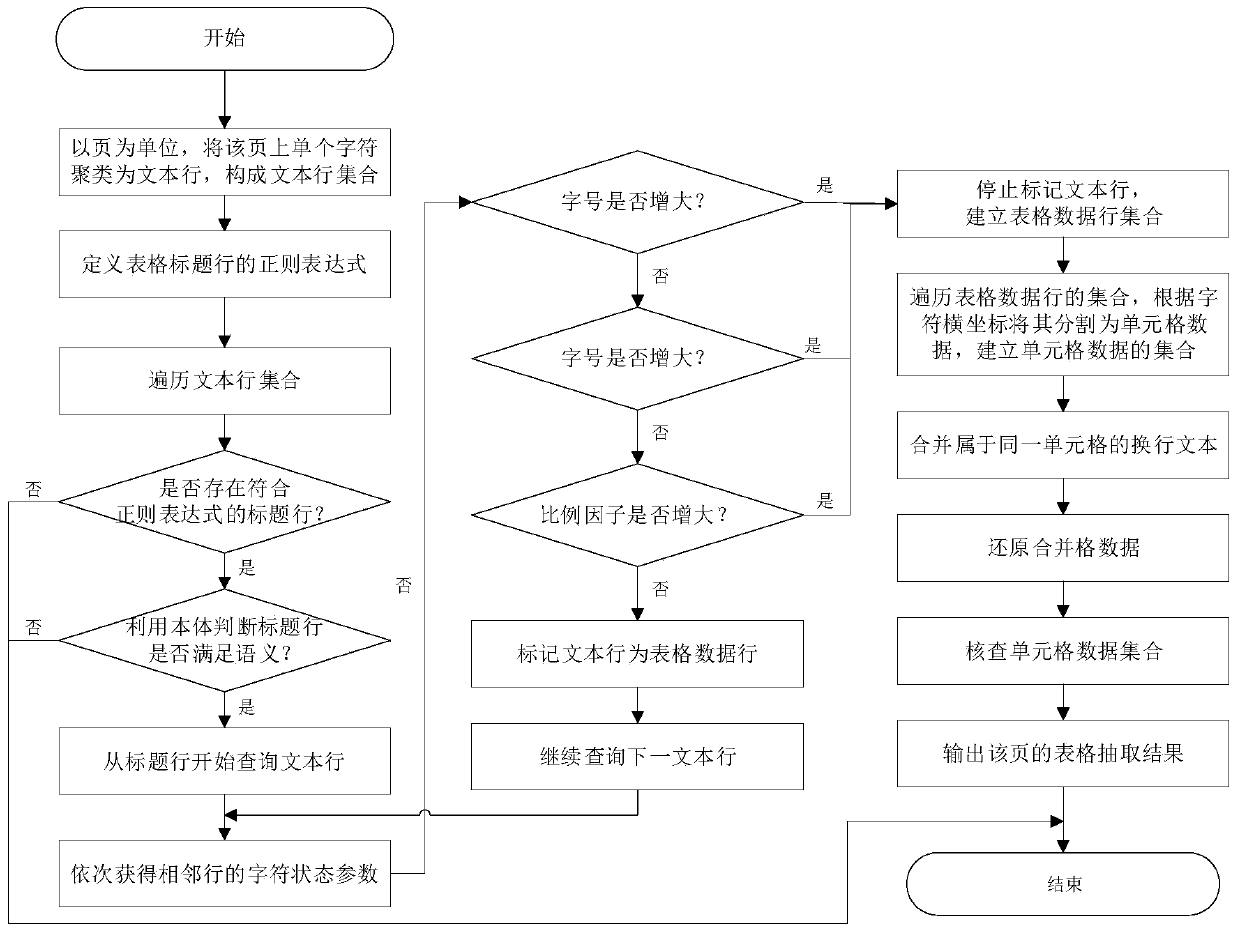
[0049] Such as figure 1 Shown, the present invention a kind of periodical document table extraction method based on text status feature, described method comprises the following steps:
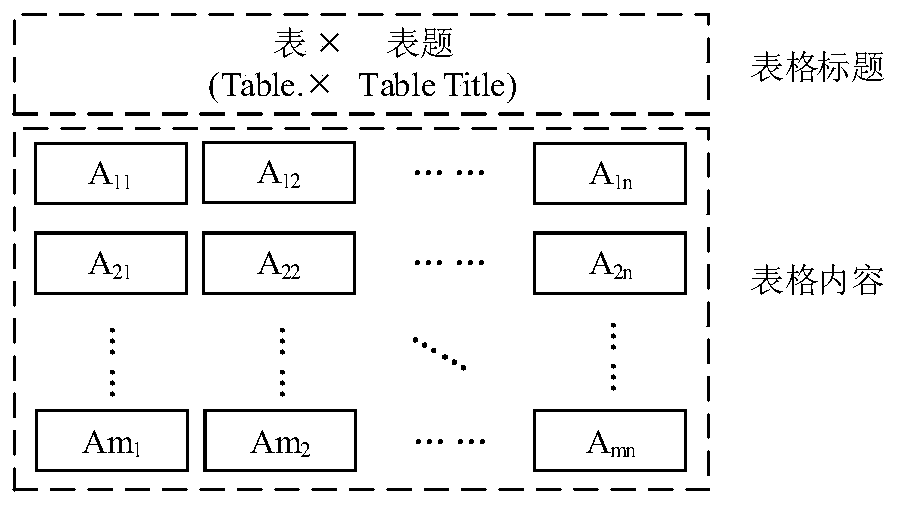
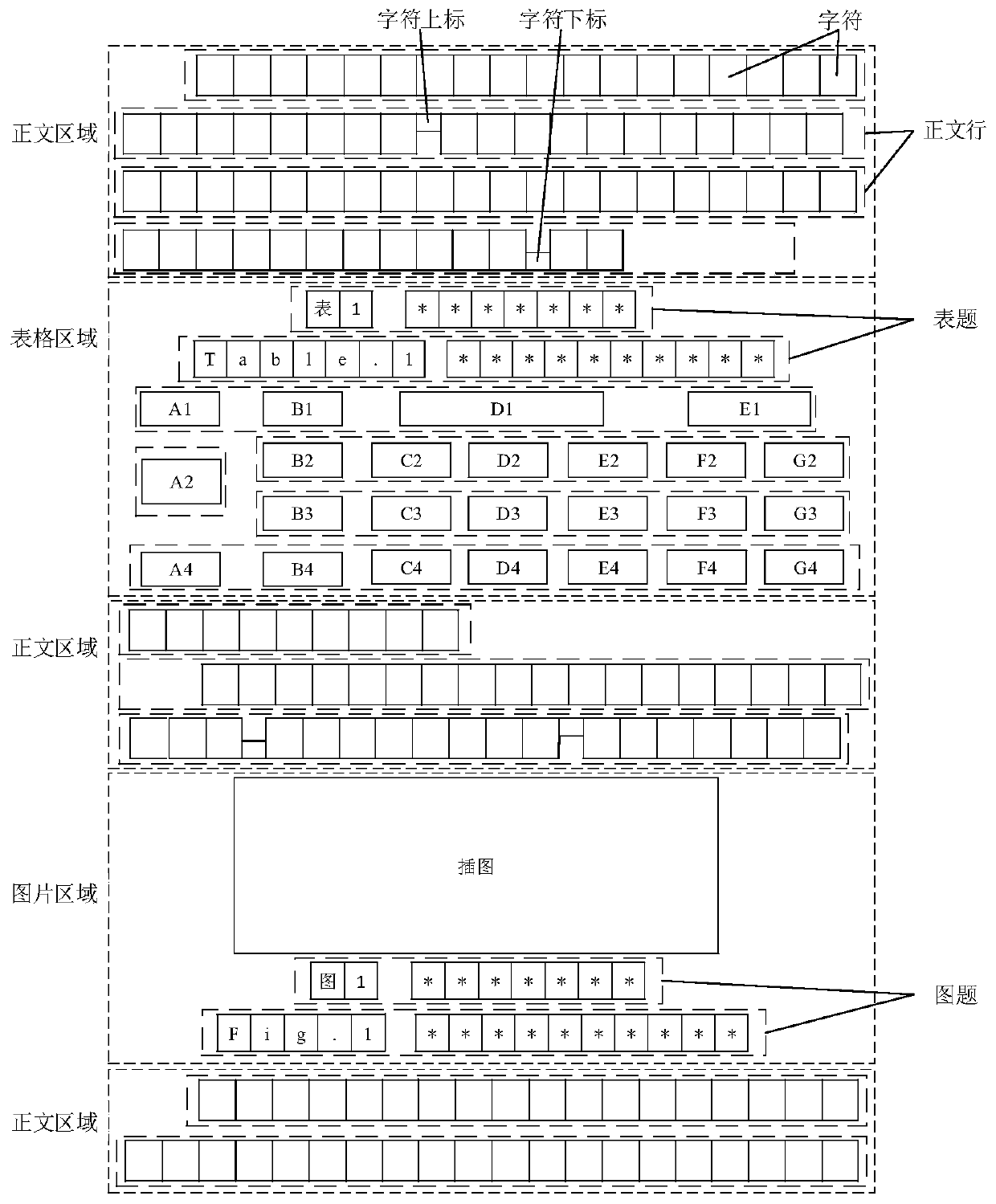
[0050] Step 1: The method abstracts the table of the journal document into the following model according to the characteristics of the table in the journal document, and builds the present invention based on this. The table model of the abstract journal literature is composed of two parts: the table title and the table content....
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More