

Deep clustering voice separation method based on improvement
A technology of speech separation and clustering, applied in speech analysis, instrument, character and pattern recognition, etc., can solve the problem that the separation effect is not ideal.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

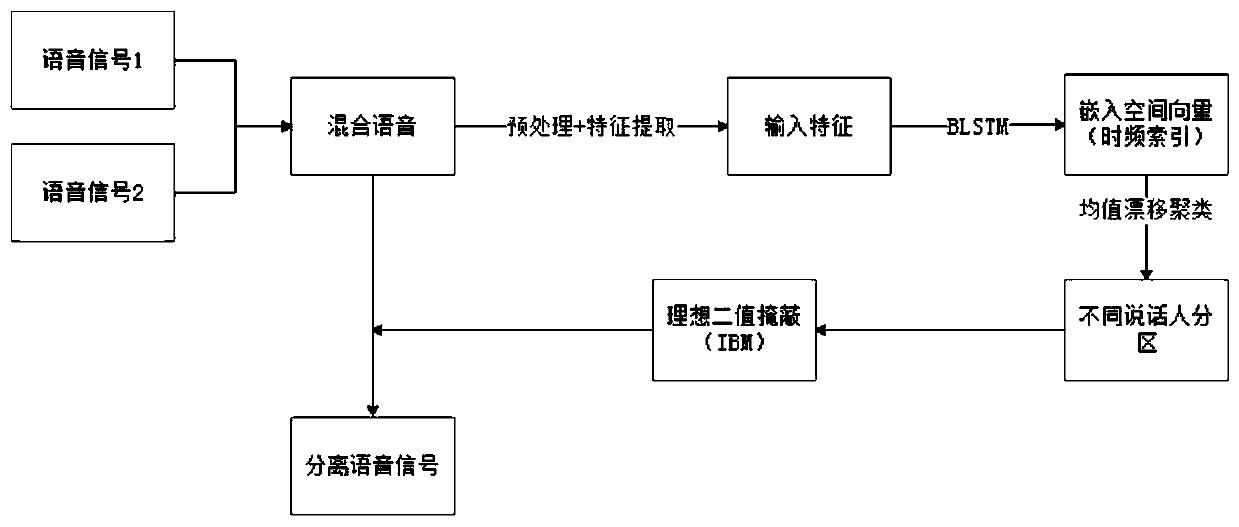
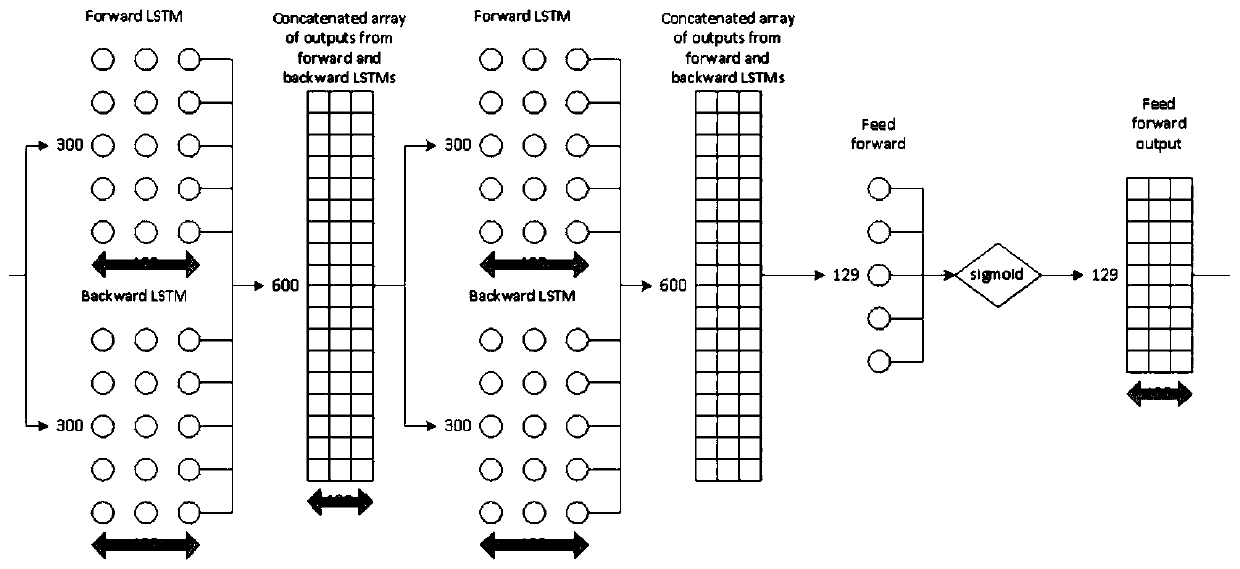
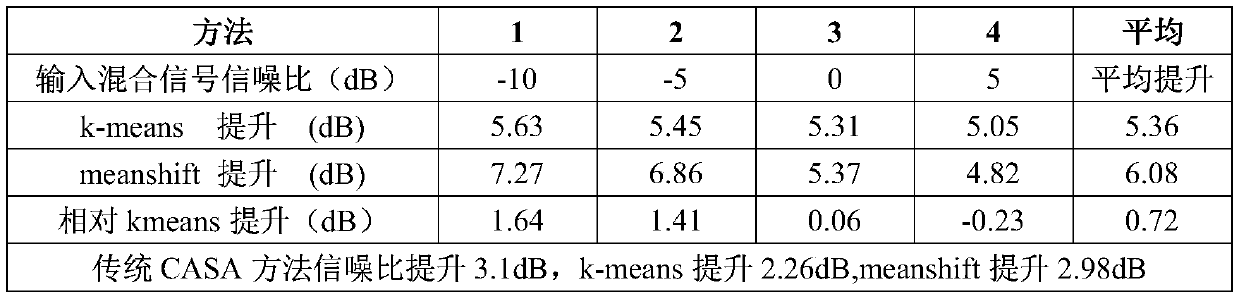
Examples
Embodiment 1
[0040]The voice experiment data used in Embodiment 1 comes from the TIMIT corpus. TIMIT is a classic corpus created by MIT in 1993 and is suitable for speech recognition, speaker classification, etc. The voice sampling frequency of its data set is 8kHz and contains 6300 sentences in total. , each of 630 people from eight major dialect regions in the United States speaks a given 10 sentences, all sentences are manually segmented and labeled at the phone level, 70% of the speakers are male, Most speakers are adult Caucasians. In order to test the speech separation task under different interference conditions, two speeches of different speakers are randomly mixed with SNR=-10dB, -5dB, 0dB, 5dB to form a training set, a verification set and a test set. Experimental conditions in different environments with strong and weak interference can be simulated, and each data set uses a different mixture of data than the other data sets, thus forming a speaker-independent environment. The ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More