

Two-stage text feature selection method under unbalanced data set
A feature selection method, feature selection technology, applied in the direction of digital data processing, natural language data processing, special data processing applications, etc., can solve the problems of ignoring feature correlation, biasing the majority class, ignoring, etc., to improve classification accuracy , design reasonable effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

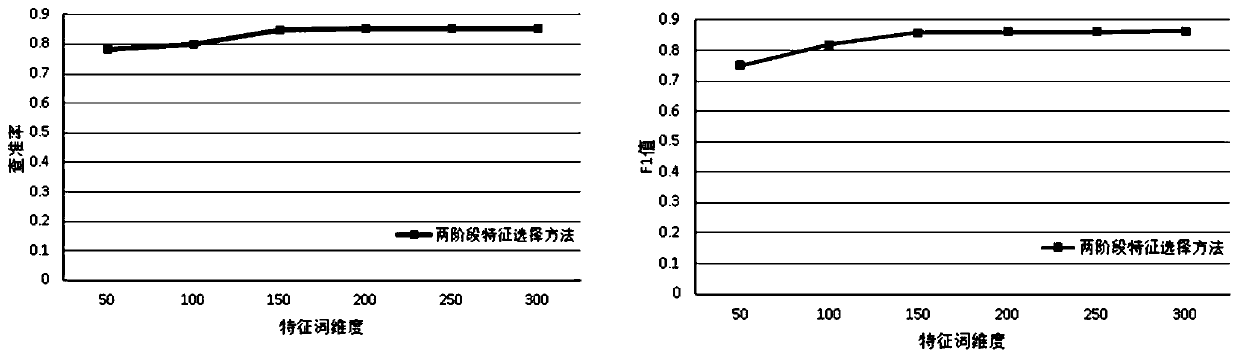
Examples
Embodiment Construction
[0049] Below in conjunction with accompanying drawing and specific embodiment the present invention is described in further detail:
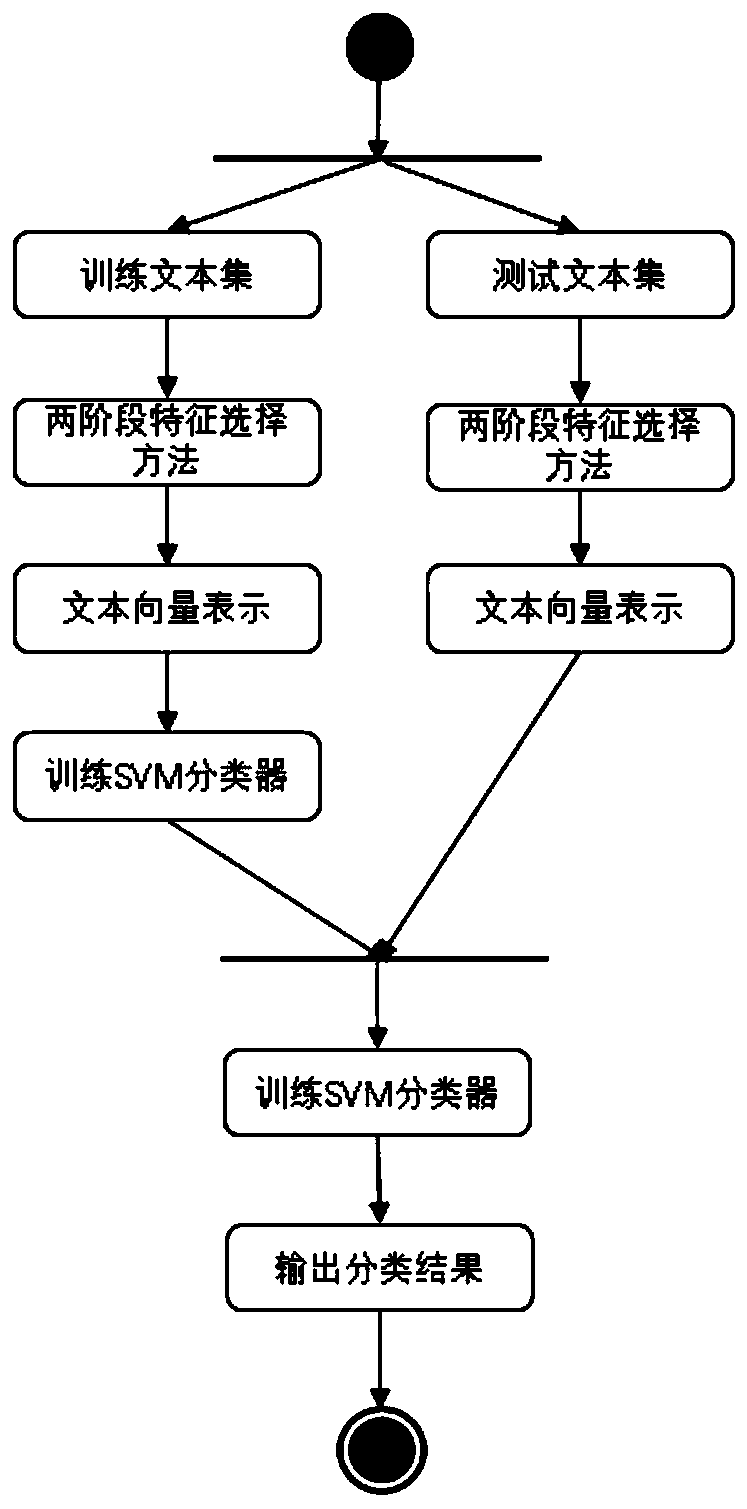
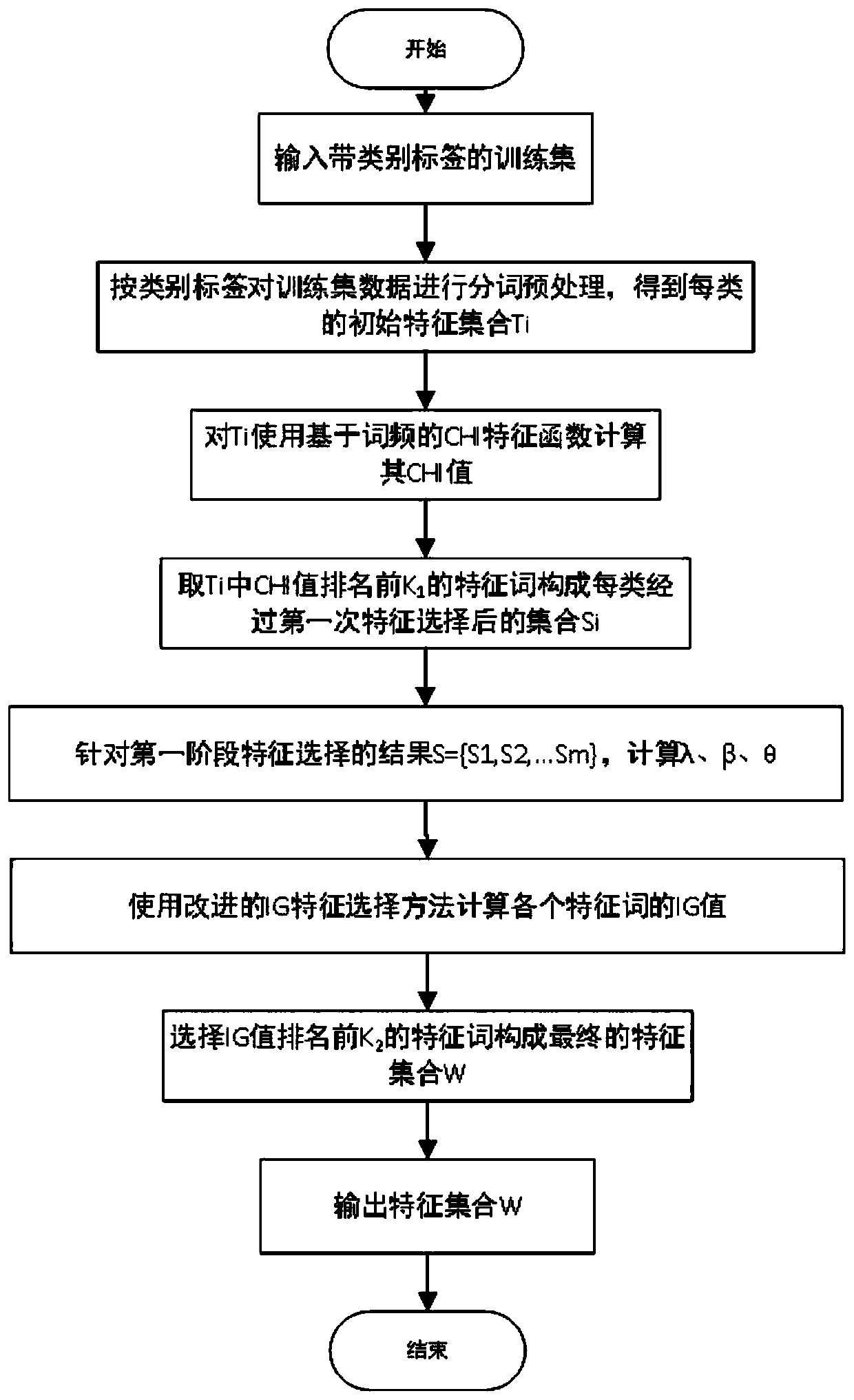
[0050] A two-stage text feature selection method under imbalanced datasets, such as figure 2 As shown, including the local feature selection method and the global feature selection method;
[0051] The local feature selection method, that is, using the CHI feature selection method based on word frequency to select local feature words, specifically includes the following steps:
[0052] Step S11: Obtain text data with category labels and use it as a training sample set D={d 1 , d 2 ,... d t};
[0053] Step S12: Preprocess the text data in the training sample set to obtain the category label set C={c 1 , c 2 ,... c m}, perform word segmentation and stop word processing according to the category, and each category c i Form an initial feature set T i ={t i1 , t i2 ,...t ik}, 1≤i≤m;
[0054] Step S13: Calculate the initial feature set T...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More