RDD partition internal data index establishing method, click checking method and joinRDD click checking method
A technology for establishing internal data and indexes, applied in database indexing, structured data retrieval, digital data information retrieval, etc., can solve problems such as poor performance of lookupAPI, improve query efficiency, prevent OOM, and improve query efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
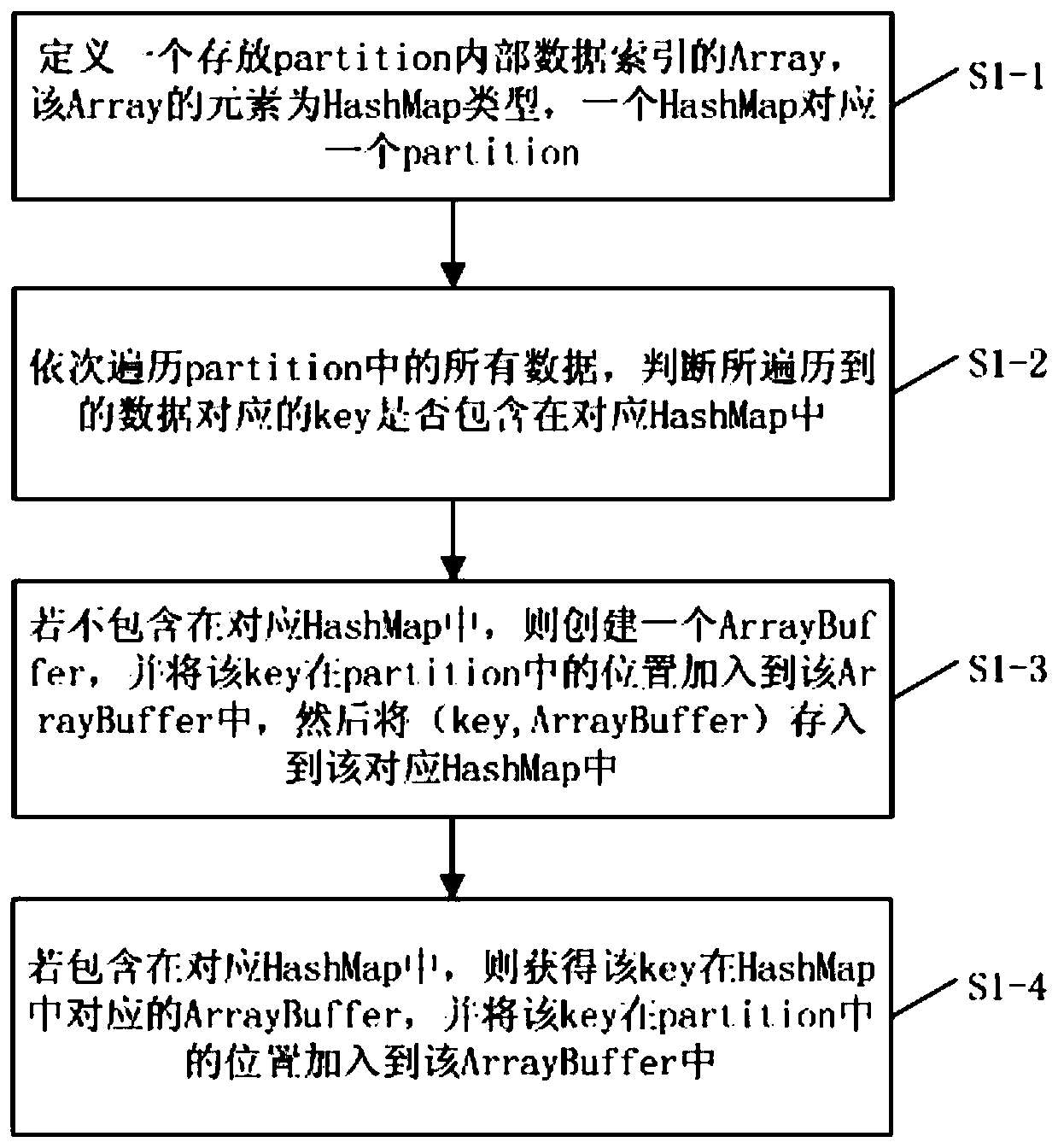
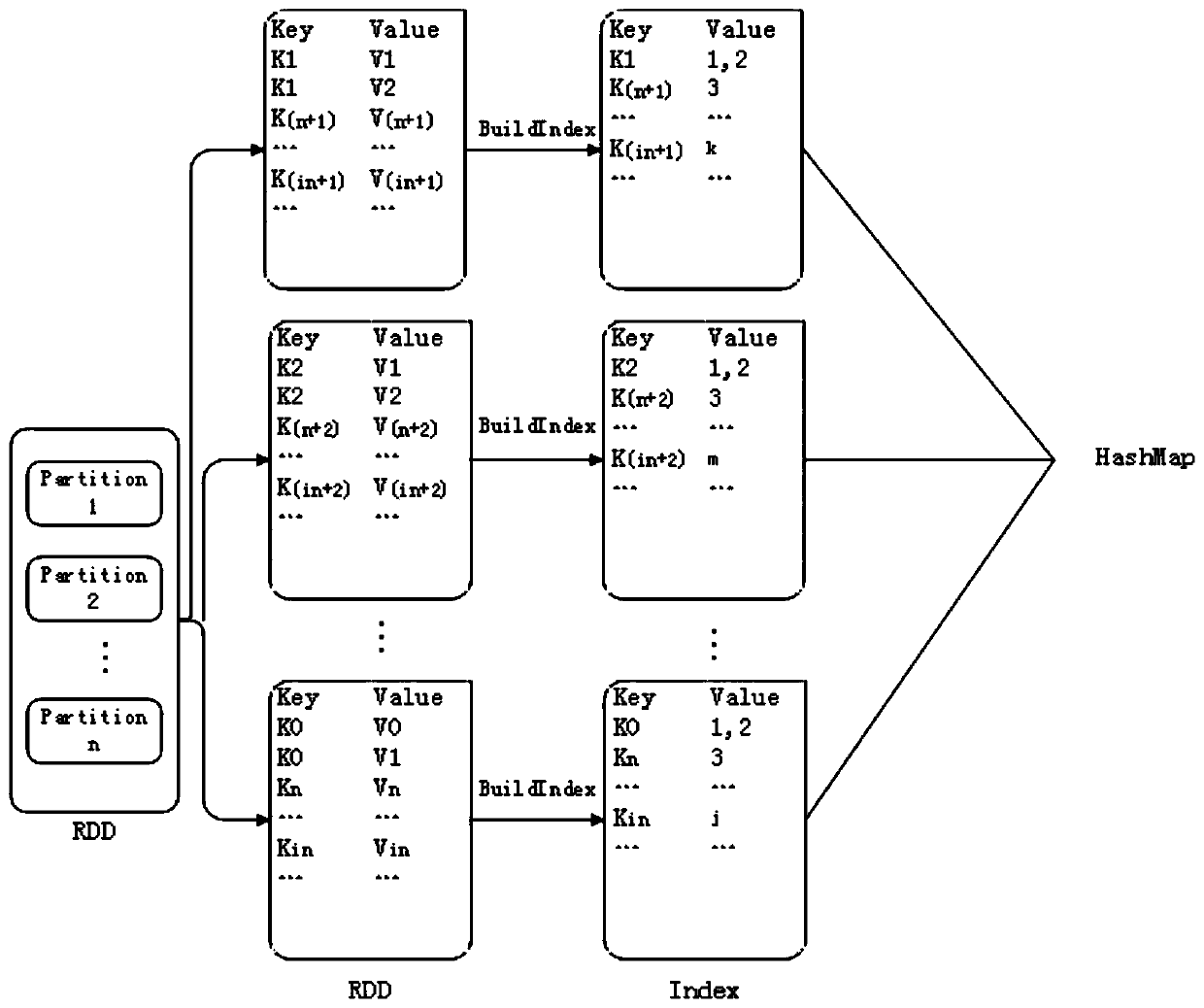
[0038] This embodiment provides a method for establishing an internal data index of an RDD partition. The index constructed for the RDD is an Array whose element type is HashMap, which corresponds to a partition one by one, and each HashMap stores the internal data index information of the corresponding partition.
[0039] What needs to be explained in this embodiment is that the data type of the RDD is (K, V). Before indexing, it is first possible to determine whether the RDD has a partitioner, and if there is a partitioner, perform subsequent steps. That is, ensure that the RDD has a partitioner, so as to ensure that elements with the same key value in the RDD will be in the same partition.
[0040] Such as figure 1 with 2 As shown, this method to establish partition internal data specifically includes the following steps:
[0041] S1-1, define an Array that stores the internal data index of the partition. The elements of the Array are of HashMap type, and a HashMap corres...
Embodiment 2
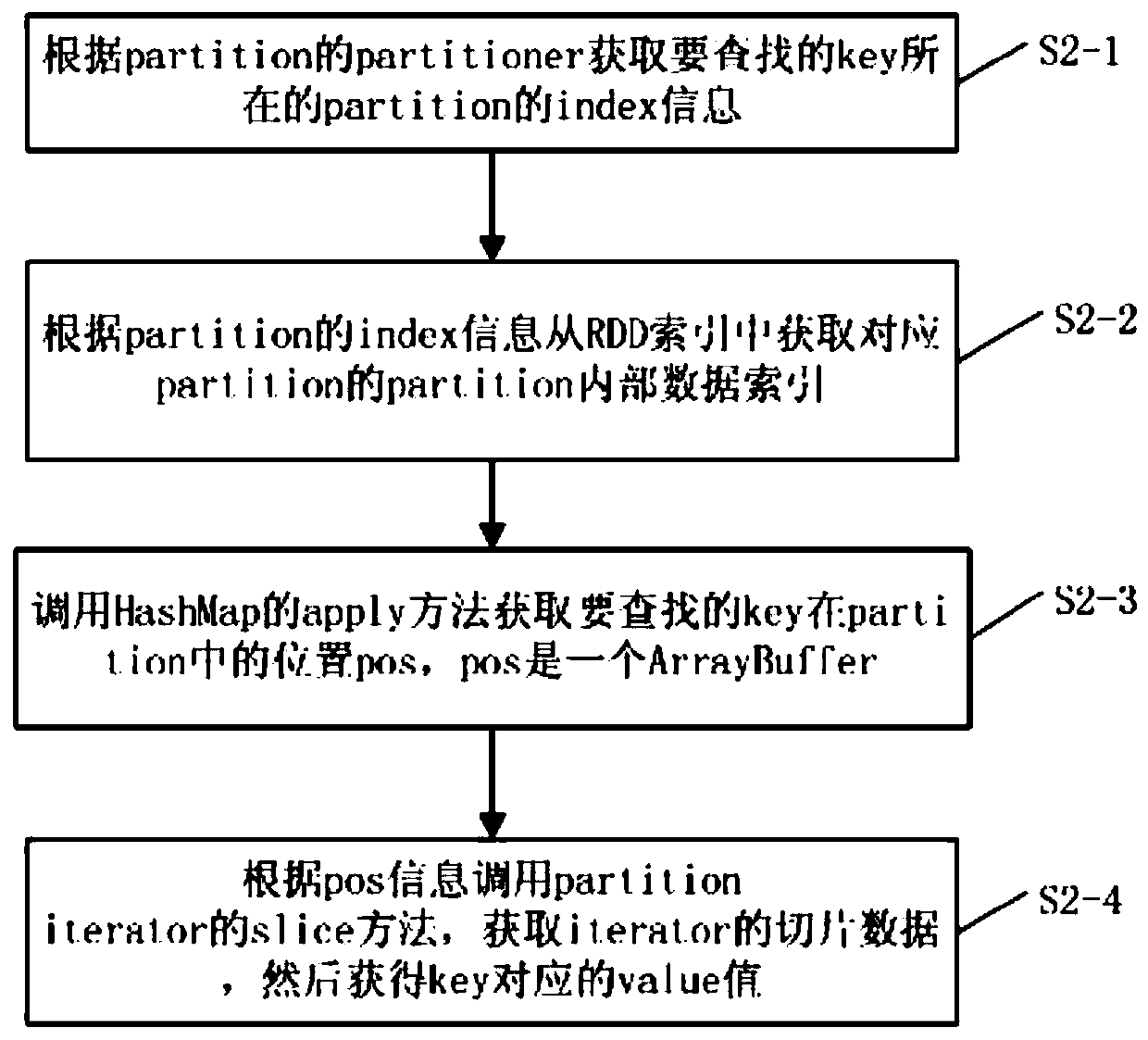
[0050] Based on the index established in Embodiment 1, this embodiment provides an RDD counting method, which uses the index search to obtain the partition index according to the partition information, and then obtains the position of the data in the partition according to the index, and finally obtains the data.
[0051] Such as image 3 As shown, the method specifically includes the following steps:
[0052] S2-1, obtain the index information of the partition where the key to be searched is located according to the partitioner of the partition;
[0053] S2-2, according to the index information of the partition, obtain the partition internal data index (ie a HashMap) corresponding to the partition from the RDD index;
[0054] S2-3, call the apply method of HashMap to obtain the position pos of the key to be found in the partition, pos is an ArrayBuffer;
[0055] S2-4, call the slice method of the partition iterator according to the pos information, obtain the slice data of ...
Embodiment 3
[0059] Based on the first and second embodiments above, this embodiment provides a join RDD enumeration method, using the index established by the method in the first embodiment and the enumeration method in the second embodiment to search the RDD after natural connection.
[0060] Such as Figure 4 As shown, the method specifically includes the following steps:
[0061] S3-1, call the method of Embodiment 1 for the two RDDs that need to be joined, and construct the corresponding RDD index;
[0062] S3-2, calling the method of Embodiment 2 on the two RDDs to find the value value that meets the conditions;
[0063] S3-3, combine the query results of the two RDDs and return the results in the form of join data.
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - R&D
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com