

Fault detection and nonlinear change introduction open source software reliability modeling method
A non-linear change, open source software technology, applied in software testing/debugging, error detection/correction, instruments, etc., can solve problems such as fault detection non-linear changes
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
[0074] Fault detection and the introduction of non-linear changes in open source software reliability modeling methods include the following steps:
[0075] Step 1. Propose model assumptions:
[0076] (1) The fault detection of open source software is a non-homogeneous Poisson process;
[0077] (2) During the development and testing of open source software, the number of faults detected is related to the number of faults remaining in the software, and the following formula can be obtained:
[0078]
[0079] Among them, μ(t) is the mean value function, which represents the expected cumulative number of detected faults up to time t, and ω(t) and a(t) represent the fault detection rate function and the fault content function respectively;
[0080] (3) The fault detection process of open source software is nonlinear, and the nonlinear change is represented by a nonlinear function:
[0081]
[0082] Among them, ω and θ respectively represent the fault detection rate and proportional parameter...
Embodiment 2
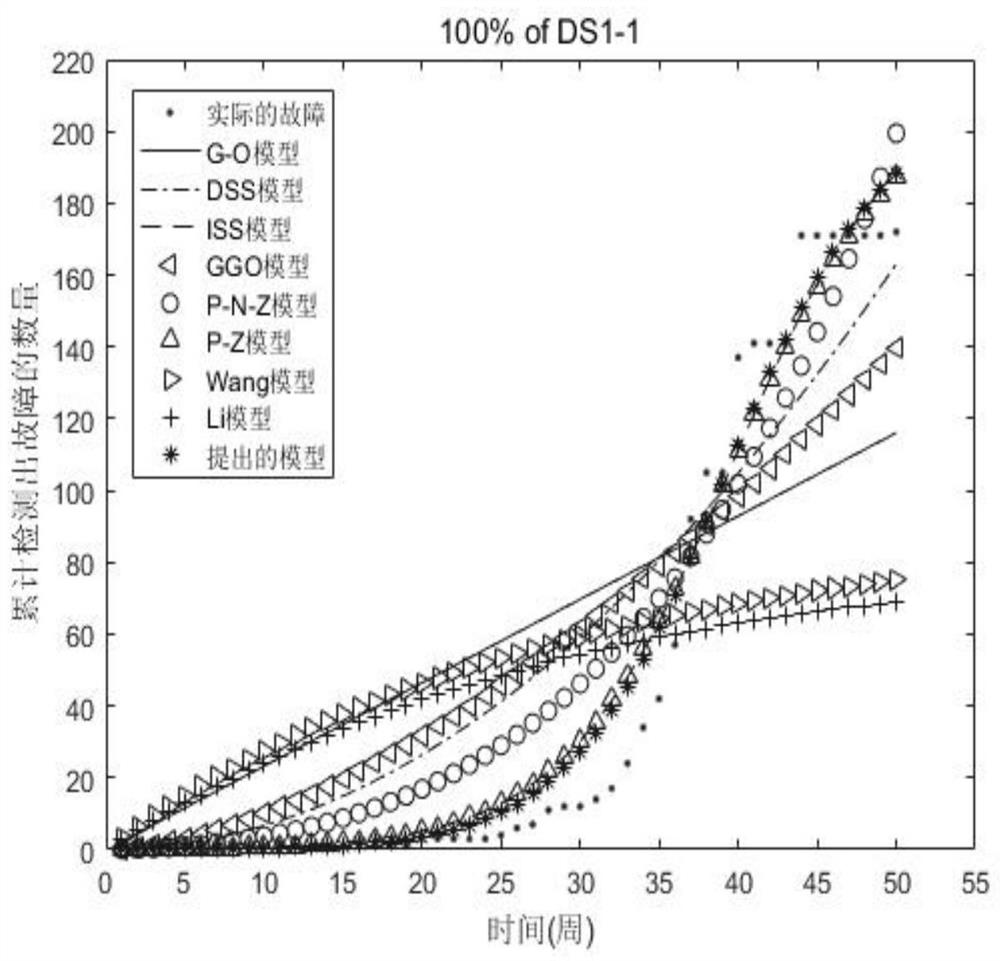
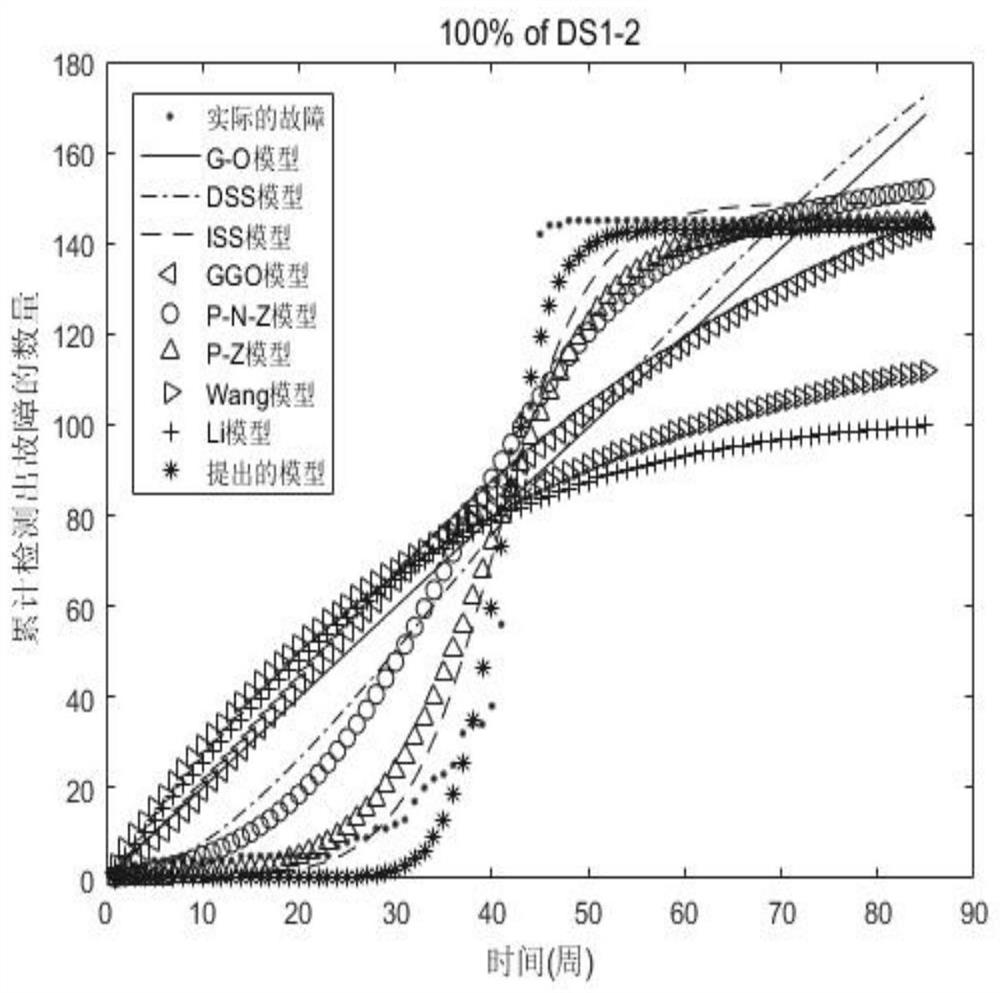
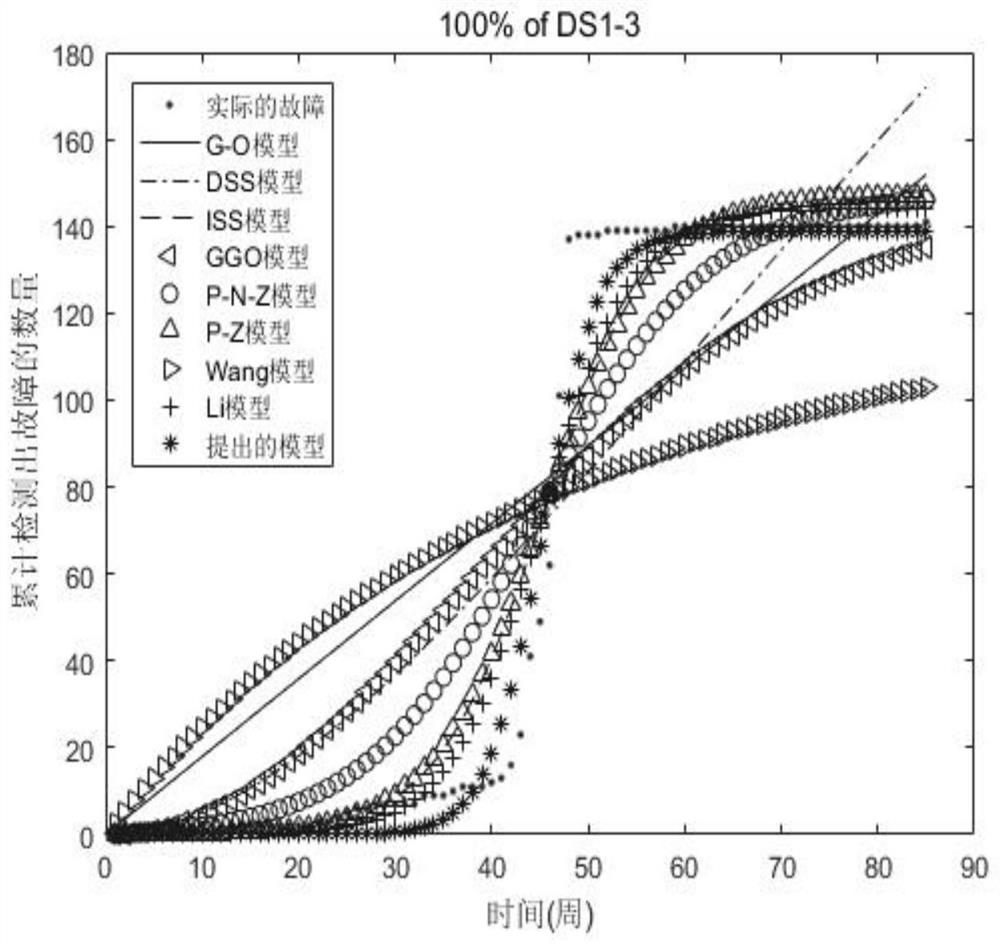
[0101] Model performance comparison
[0102] We collected fault data sets from three Apache projects in the fault tracking system. Its website is https: / / issues.apache.org / . The fault data of the open source software in the fault tracking system is called Issues. We deleted the faults whose fault statuses were "unrepairable", "invalid", "duplicate" and "no problem", and the rest were used as fault data sets. Table 1 lists the detailed failure data collection information of the open source software.
[0103] In order to compare the performance of the models, we used five model comparison criteria. They are MSE, R 2 , RMSE, TS and Bias. See Table 2 for details. In Table 2, μ(t j ) And O(t j ) Respectively represent the mean value function and the actual number of failures observed. n and m represent the sample size. In addition, in Table 2, the smaller the comparison standard value of these models from 1 to 4, the better the model performance. In addition, R 2 The larger the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More