

Deep reinforcement learning reward function optimization method for unmanned ship path planning
A technology of path planning and reinforcement learning, applied in vehicle position/route/altitude control, two-dimensional position/channel control, biological neural network model, etc. It can solve the problems of slow convergence speed of reward function and long training period.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
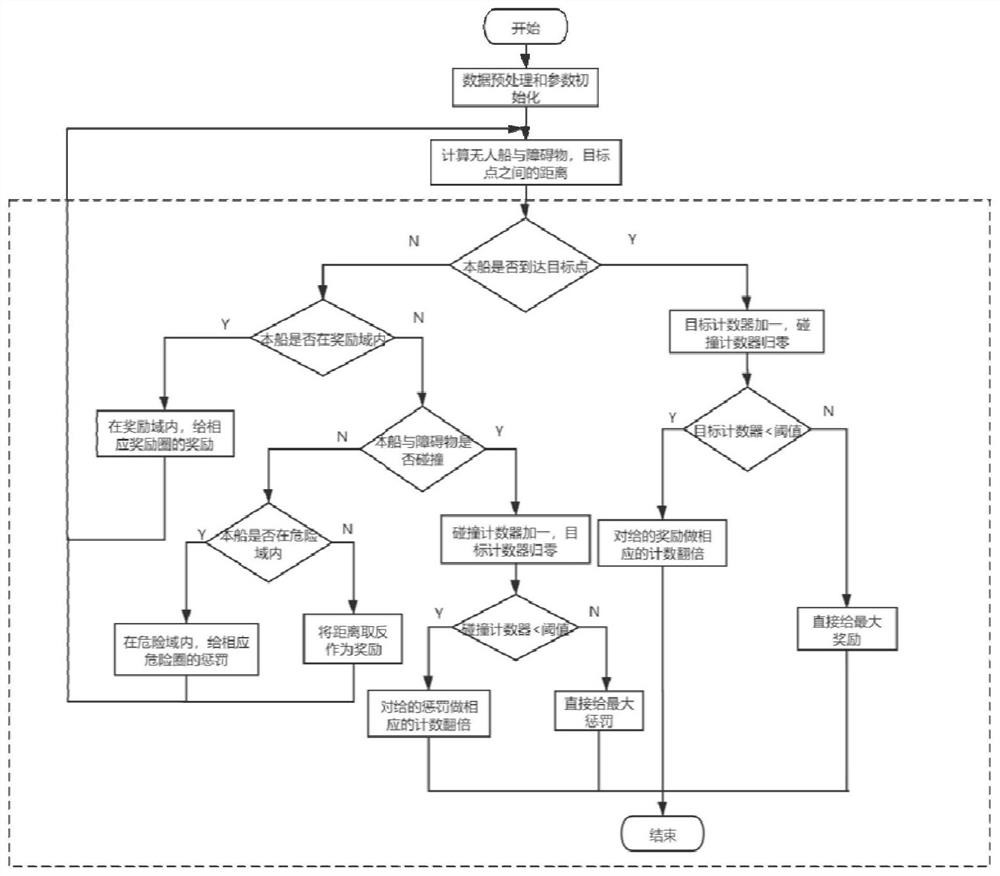
[0038] In order to enable those skilled in the art to better understand the solutions of the present invention, the following will clearly and completely describe the technical solutions in the embodiments of the present invention in conjunction with the drawings in the embodiments of the present invention. Obviously, the described embodiments are only It is an embodiment of a part of the present invention, but not all embodiments. Based on the embodiments of the present invention, all other embodiments obtained by persons of ordinary skill in the art without creative efforts shall fall within the protection scope of the present invention.
[0039]It should be noted that the terms "first" and "second" in the description and claims of the present invention and the above drawings are used to distinguish similar objects, but not necessarily used to describe a specific sequence or sequence. It is to be understood that the data so used are interchangeable under appropriate circumst...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More