

Graph convolutional neural network model and vehicle trajectory prediction method using same
A convolutional neural network and vehicle trajectory technology, applied in the field of vehicle intelligent driving, can solve problems such as difficult to express implicit relationships, achieve the effects of improving generalization ability, avoiding over-fitting, and improving robustness
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

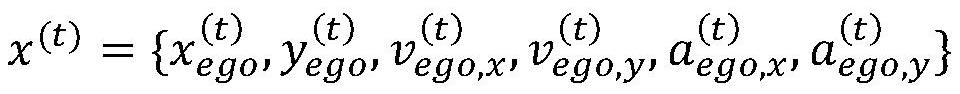
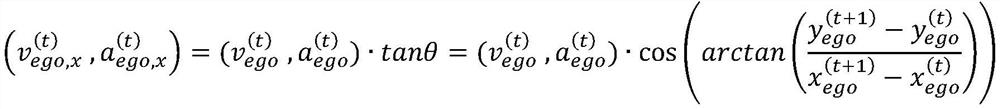
Examples
Embodiment Construction
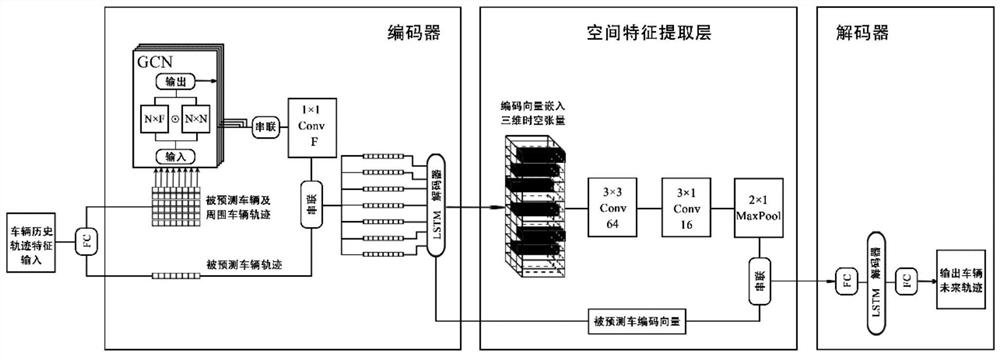
[0015] The present invention will be further described below in conjunction with accompanying drawing.
[0016] Step1: Model building
[0017] 1. Model input
[0018] The input feature value of trajectory prediction contains four necessary components, including the historical trajectory of the predicted vehicle, the historical trajectory of the surrounding vehicles of the predicted vehicle, the time TTC when the predicted vehicle and surrounding vehicles reach the collision point, and the vehicle behavior at each moment.
[0019] (1) The historical trajectory of the predicted vehicle
[0020] The historical trajectory sequence of the predicted vehicle can be expressed as:
[0021] x ego ={x (t-S) ,...,x (t-1) ,x (t)}
[0022] S is the length of the historical trajectory sequence, x (t) Indicates the historical trajectory of the vehicle under test, and t is the current moment, where:
[0023]
[0024] is the horizontal and vertical coordinates of the predicted car...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More