

Literature author name duplication disambiguation method and literature author name duplication disambiguation construction system
A document and author technology, applied in the field of document author duplication disambiguation, can solve the problems of inability to apply multi-language and multi-document types, difficult to guarantee the accuracy and recall level of disambiguation results, and achieve good compatibility.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment
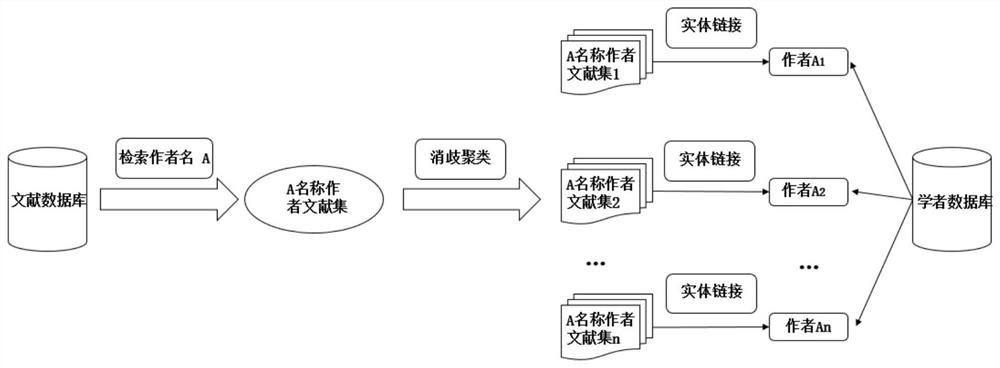
[0052] Embodiment: A method for disambiguation of the same name of a document author, such as figure 1 shown, including the following steps:
[0053] Step 1: Read the literature data and scholar data in the database;
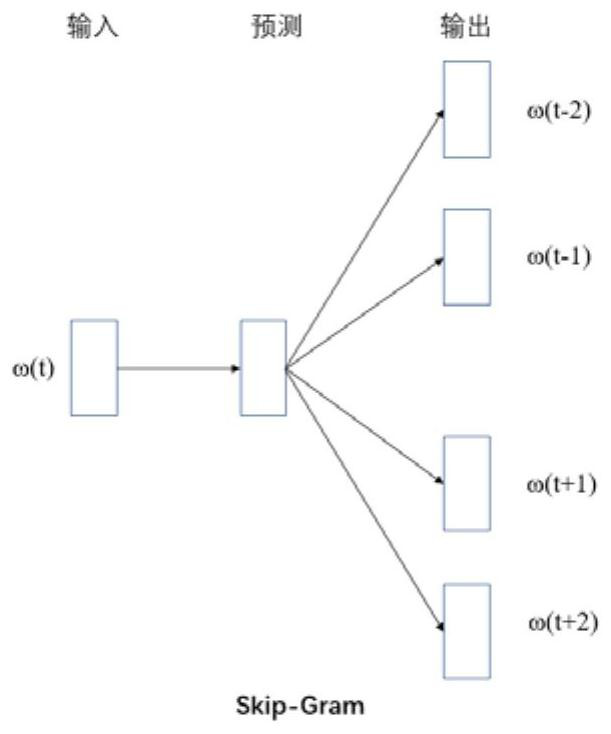
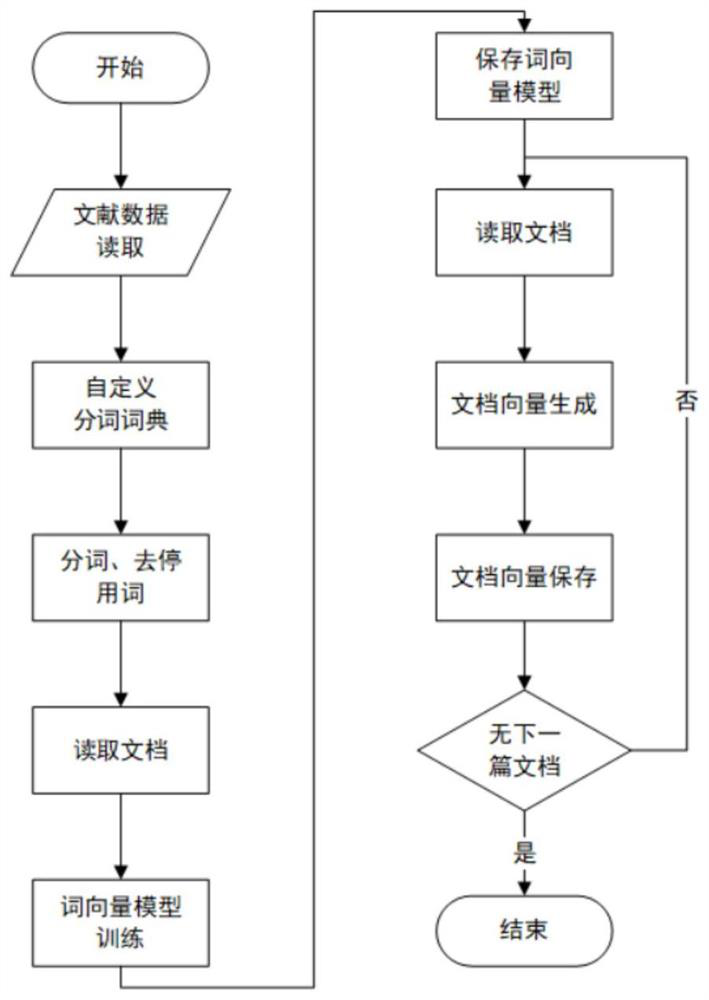
[0054] Step 2: Use the Word2Vec model to train and predict the document vector of each document;
[0055] Step 3: Construct the author-collaborator relationship network graph to be disambiguated and calculate the node similarity and clustering;
[0056] Step 4: Obtain the document vectors of the documents in the document clusters clustered by the collaborator relationship graph and calculate the similarity and clustering between the document clusters.
[0057] Described step one specifically includes:
[0058] Relevant data are read from the company's literature database and scholar database, including:
[0059] (1) ID, title, author, institution, abstract, periodical, year, keywords in Chinese paper data;
[0060] (2) ID, title, author, institution, abstract...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More