

Block-level data deduplication method based on NTFS file system
A file system and data technology, applied in the computer field, can solve the problems of large amount of data, huge amount of user data, huge image file, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment 1
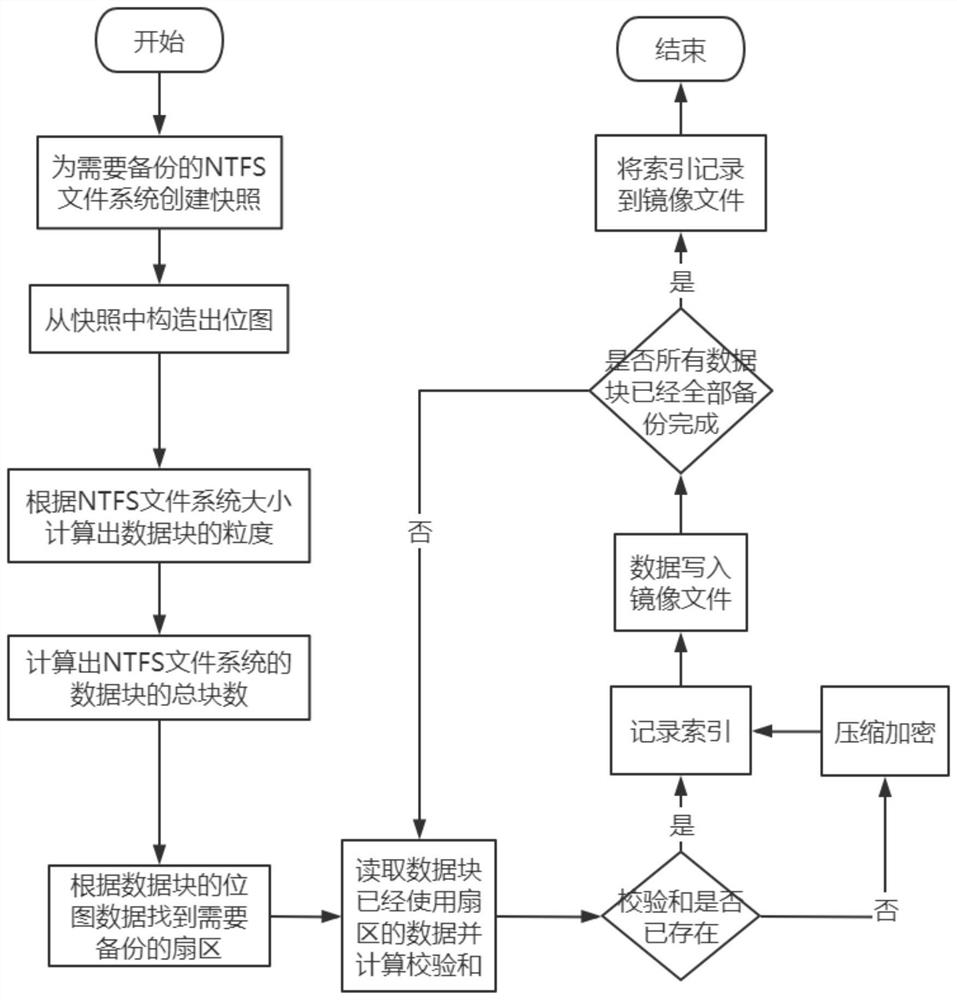
[0039] Such as figure 1 As shown, a block-level data deduplication method based on the NTFS file system includes the following steps:
[0040] Step S1. Create a snapshot for the NTFS file system that needs to be backed up;
[0041] Step S2. Constructing a bitmap from the snapshot;
[0042] Step S3. Calculate the granularity of the data block according to the size of the NTFS file system;
[0043] Step S4. Calculate the total number of blocks of the data blocks of the NTFS file system;
[0044] Step S5. Find the sector that needs to be backed up according to the bitmap data of the data block;
[0045] Step S6. Read the data of the used sector of the data block and calculate the checksum;
[0046] Step S7. Determine whether the checksum already exists, and if it exists, record the index; if not, record the index after compressing and encrypting, and write the data into the image file;
[0047] Step S8. Judging whether all the data blocks have been fully backed up; if all th...
Embodiment 2
[0062] This embodiment is a further specific technical solution of the first embodiment.
[0063]First, use the snapshot technology to create a snapshot for the NTFS file system that needs to be backed up, and then analyze the used cluster information of the NTFS file system by reading the snapshot, and construct the used bitmap of the file system based on the used cluster information According to the file information in the exclusion list, the bitmap information of the excluded files is constructed, and the bitmaps of these files to be excluded are excluded from the bitmap of the entire file system to generate the final bitmap data that needs to be backed up.
[0064] Then divide the entire file system into blocks according to the total size of the file system, and divide the data into blocks by dividing the number of bytes in the default block by the number of bytes in each cluster to calculate the minimum number of clusters each block occupies, and check the calculation. Wh...
Embodiment 3
[0098] Embodiment 3 is a further optimization of Embodiment 1 and Embodiment 2.
[0099] When the present invention is applied to a cloud storage system that stores massive data files, similar data blocks cannot be removed, resulting in huge image files generated during data backup. To solve this problem, this embodiment makes further optimizations. The scheme is as follows:
[0100] A method for deduplication of block-level data based on an NTFS file system for a cloud storage system, comprising the steps of:
[0101] Step A. Create a snapshot for the file system to be backed up;
[0102] Step B. Construct a bitmap from the snapshot; add a first-level index node in the cloud storage system, and the first-level index node is used to obtain the data block fingerprint of the file;
[0103] Step C. The primary index node constructs a secondary index consisting of a primary index and a secondary index according to the similarity of the files;
[0104] Step D. Deduplicating the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More