

Semantic integration method for multi-source heterogeneous database
A semantic integration, multi-source heterogeneous technology, applied in the direction of unstructured text data retrieval, semantic tool creation, special data processing applications, etc., can solve problems such as not being able to adapt to application requirements
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
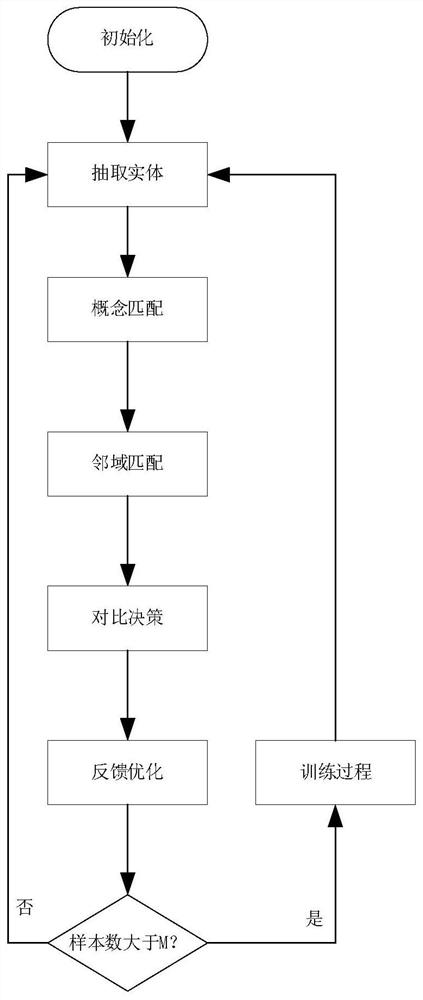
[0055] Using the above scheme, specifically include the following steps:
[0056] S1: Through the entity extraction model based on deep learning algorithm, domain-related entities are extracted from unstructured text, the start and end positions of the entities are obtained, and the corresponding categories of the entities are identified;
[0057] S2: Match the identified category of the entity to be aligned with the ontology concept in the knowledge graph to obtain a candidate set with the same category as the entity to be aligned;
[0058] S3: Obtain the graph representation of the entity to be aligned according to the entity context information of the unstructured text, and obtain the graph representation of the candidate entity according to the neighborhood relationship of the nodes in the knowledge graph;
[0059] S4: Use the deep reinforcement learning model to compare the graph representation of the candidate entity in the candidate set with the graph representation of ...
Embodiment 2
[0062] Using the above scheme, specifically include the following steps:
[0063] S11: Establish a label system, mark the unstructured text according to the label system, and construct a data set for entity extraction tasks;
[0064] S12: Using the pre-trained language model BERT, construct a sequence labeling model of BERT combined with conditional random field CRF. Based on this model, the entity extraction of the remaining unstructured text is completed, the start and end positions of the entity are obtained, and the corresponding category of the entity is identified;
[0065] Among them: for specific domain applications, the pre-trained language model BERT can first perform domain adaptation in large-scale unlabeled domain-related text corpora; for specific application tasks, task adaptation can be performed in task-related text corpora. To improve the performance of language model BERT in entity extraction tasks.
[0066] S21: According to the entity extraction result o...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More