

Speech synthesis method and device and computer storage medium
A speech synthesis and audio technology, applied in the computer field, can solve the problems of incomplete audio content, unable to reflect all the information of the input text, poor accuracy of speech synthesis, etc.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0053] The embodiment of the present application provides a speech synthesis method, figure 1 It is a flowchart of a speech synthesis method provided in Embodiment 1 of the present application. see figure 1 , the speech synthesis method provided by Embodiment 1 of the present application includes the following steps:
[0054] Step 101: Obtain a mixed sequence to be synthesized.
[0055] The mixed sequence to be synthesized is an input that requires speech synthesis, that is, the text information included in the mixed sequence to be synthesized needs to be converted into natural speech. The mixed sequence includes text to be synthesized and graphics to be synthesized. The text to be synthesized is text data in plain text format, for example, the text to be synthesized is Chinese text, English text or a mixed text of Chinese and English. The graphic to be synthesized is a picture including text information, specifically, it may include graphic text and / or graphic formula, an...
Embodiment 2
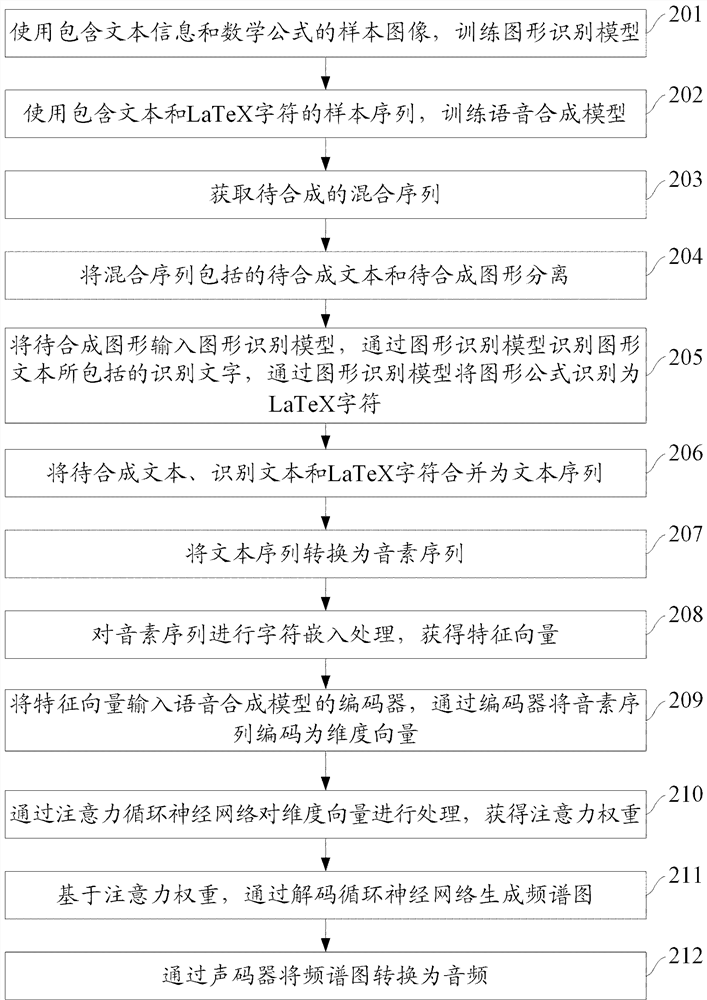
[0070] Based on the speech synthesis method provided in the first embodiment above, the second embodiment of the present application provides a speech synthesis method, which is a further specific description of the speech synthesis method described in the first embodiment, and this method can be applied to teaching text speech Synthetic application scenarios. figure 2 It is a flowchart of a speech synthesis method provided in Embodiment 2 of the present application. see figure 2 , the speech synthesis method provided in Embodiment 2 of the present application includes the following steps:
[0071] Step 201: Use sample images containing text information and mathematical formulas to train a pattern recognition model.
[0072] In the embodiment of the present application, before performing speech synthesis on the mixed sequence, it is first necessary to train the pattern recognition model so that it has the function of recognizing text and formulas from pictures. In a possi...
Embodiment 3
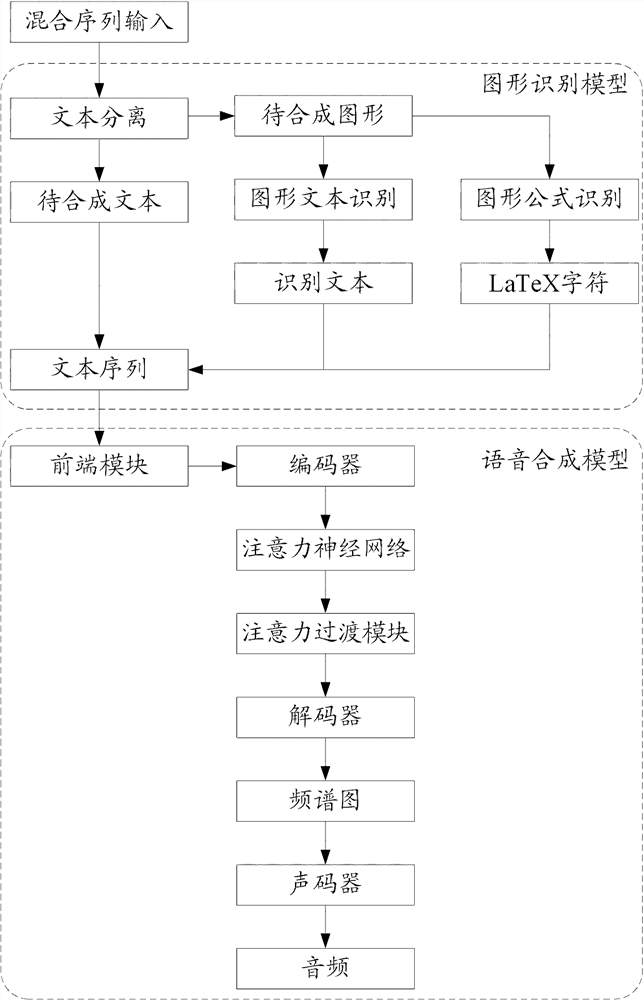
[0114] Based on the speech synthesis method provided in Embodiment 1 above, Embodiment 3 of the present application provides a speech synthesis method, which is a further specific description of the speech synthesis method described in Embodiment 1. image 3 It is a process schematic diagram of a speech synthesis method provided in Embodiment 3 of the present application. see image 3 , the speech synthesis method of embodiment three of the present application includes: performing text separation after inputting the mixed sequence, separating the text to be synthesized and the graphics to be synthesized included in the mixed sequence; separating the graphic text and the graphics formula to be synthesized; The plain text in the text is recognized to obtain the recognized text; the graphic formula is recognized as LaTeX characters; the text to be synthesized, the recognized text and the LaTeX characters are combined to obtain the text sequence; the text sequence is input into th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More