Image annotation method and device, image semantic segmentation method and device and model training method and device
A technology of semantic segmentation and image annotation, which is applied in image analysis, image data processing, instruments, etc., can solve the problems of low efficiency and high annotation cost in the annotation process, so as to improve generalization ability, uncertainty, and annotation efficiency effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

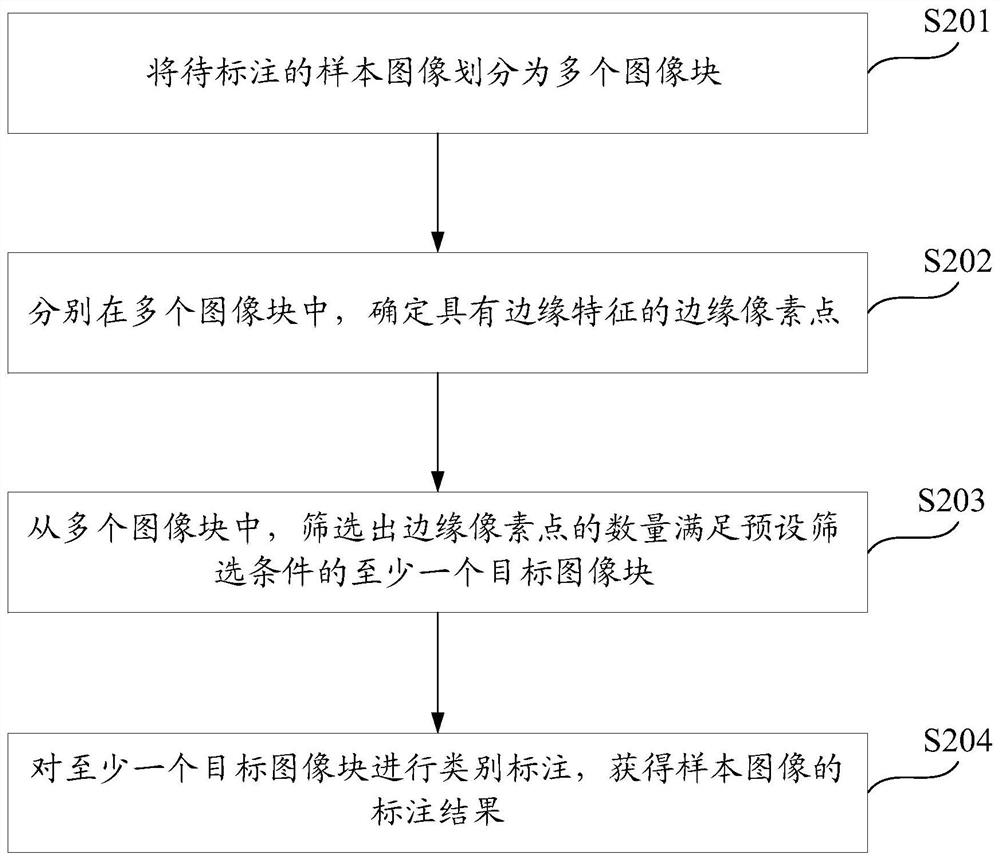
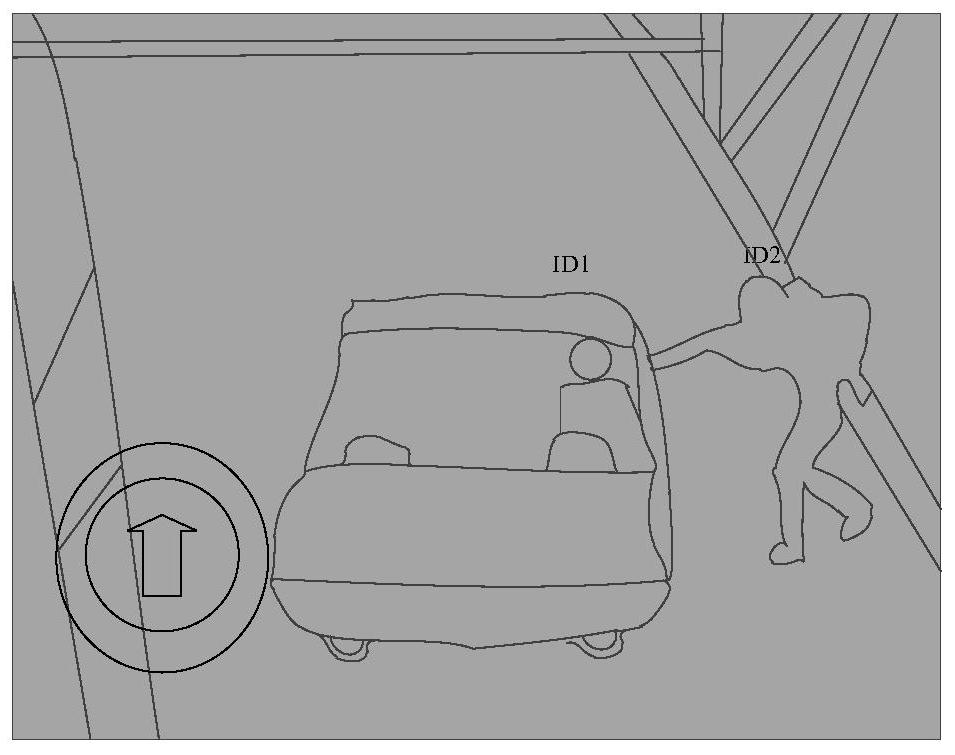
Examples
Embodiment Construction
[0085] In order to better understand the technical solutions provided by the embodiments of the present application, a detailed description will be given below in conjunction with the accompanying drawings and specific implementation manners.
[0086] In order to facilitate those skilled in the art to better understand the technical solutions of the present application, terms involved in the present application are introduced below.
[0087] 1. Artificial Intelligence (AI): It is the theory, method, technology and application of using digital computers or machines controlled by digital computers to simulate, extend and expand human intelligence, perceive the environment, acquire knowledge and use knowledge to obtain the best results system. In other words, artificial intelligence is a comprehensive technique of computer science that attempts to understand the nature of intelligence and produce a new kind of intelligent machine that can respond in a similar way to human intelli...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



