

Strategy collaborative selection method based on deep reinforcement learning DDPG algorithm framework
A reinforcement learning and strategy technology, applied in the field of reinforcement learning, can solve problems such as excessive fluctuation of the strategy network, and achieve the effect of increasing generalization, improving overestimation problems, and improving overfitting.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

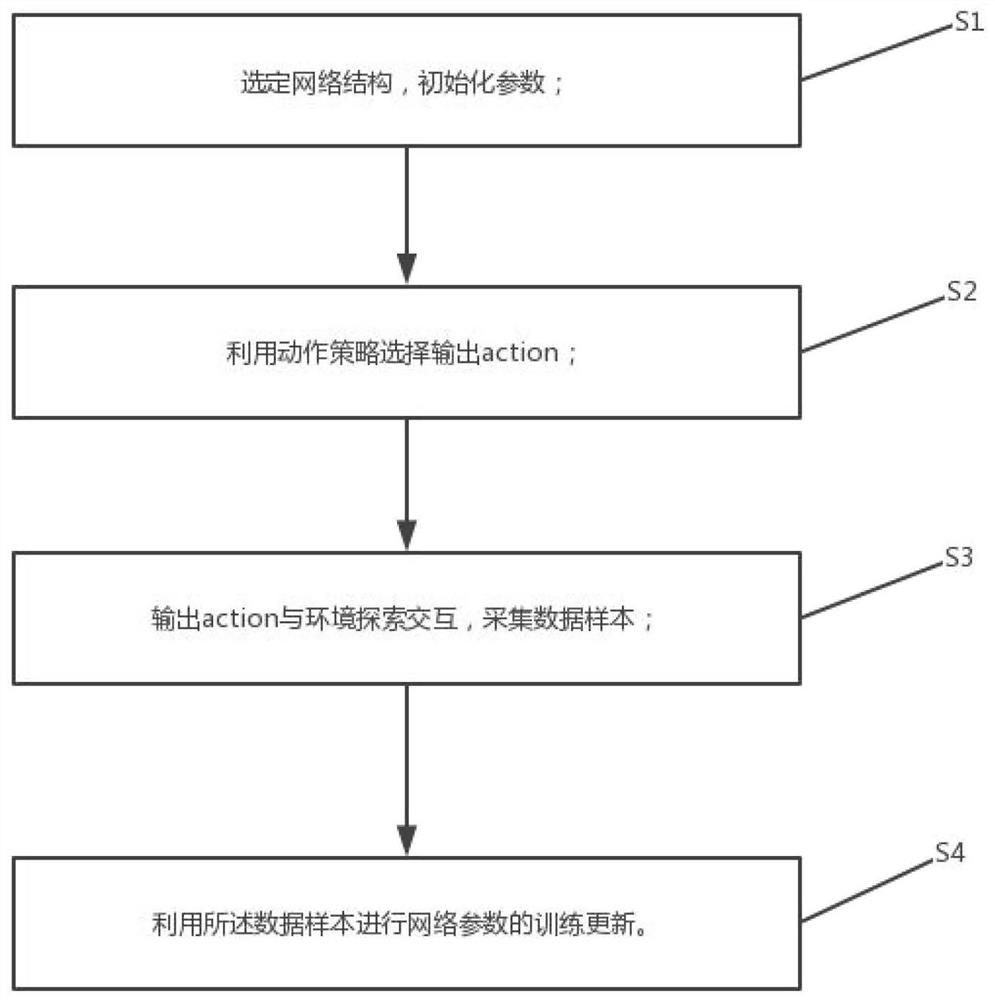
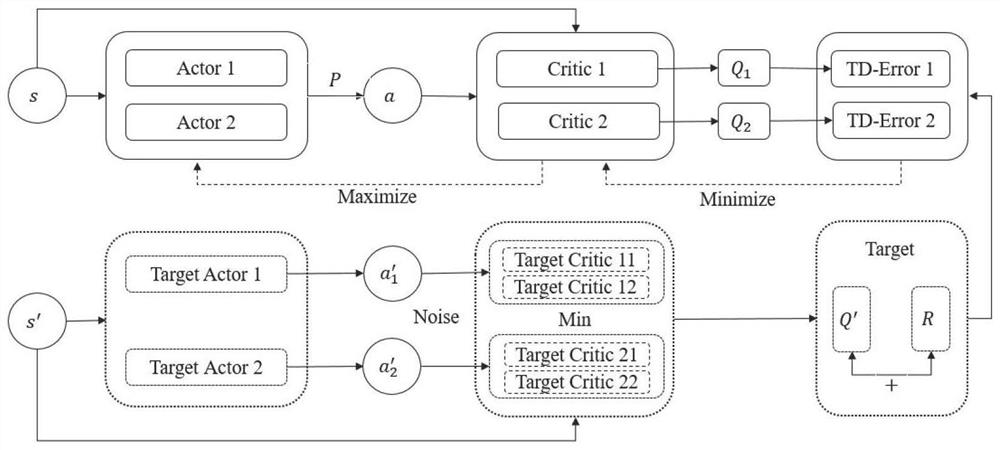
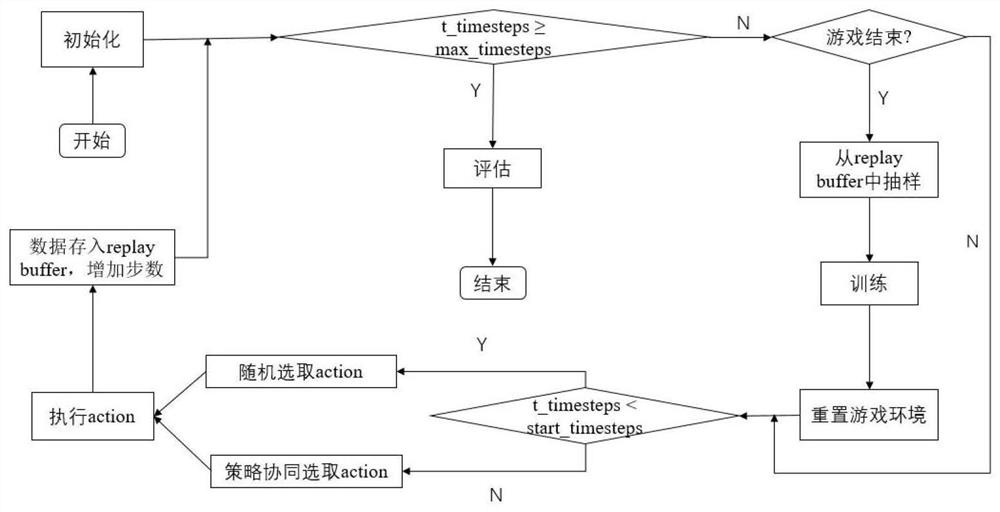
Examples
Embodiment Construction
[0024] Embodiments of the present invention are described in detail below, examples of which are shown in the drawings, wherein the same or similar reference numerals designate the same or similar elements or elements having the same or similar functions throughout. The embodiments described below by referring to the figures are exemplary and are intended to explain the present invention and should not be construed as limiting the present invention.
[0025] In describing the present invention, it should be understood that the terms "length", "width", "upper", "lower", "front", "rear", "left", "right", "vertical", The orientation or positional relationship indicated by "horizontal", "top", "bottom", "inner", "outer", etc. are based on the orientation or positional relationship shown in the drawings, and are only for the convenience of describing the present invention and simplifying the description, rather than Nothing indicating or implying that a referenced device or element...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More