

Multi-label microblog text classification method based on semi-supervised learning
A semi-supervised learning and text classification technology, applied in the field of multi-label classification of microblog text through semi-supervised models, can solve problems such as expensive costs, reduce creation costs, increase anti-interference ability, and improve training speed and accuracy Effect
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 1
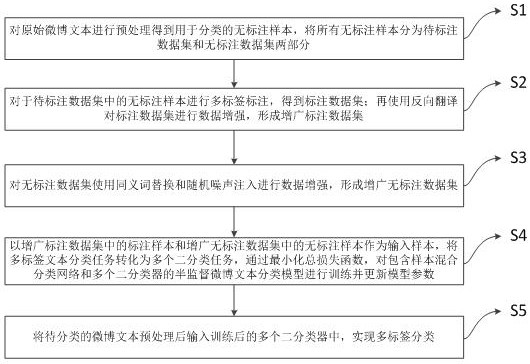
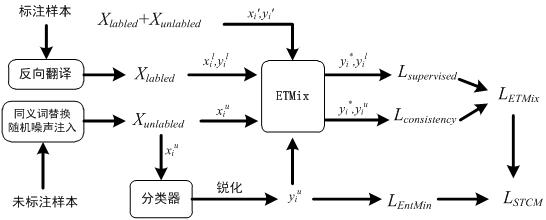
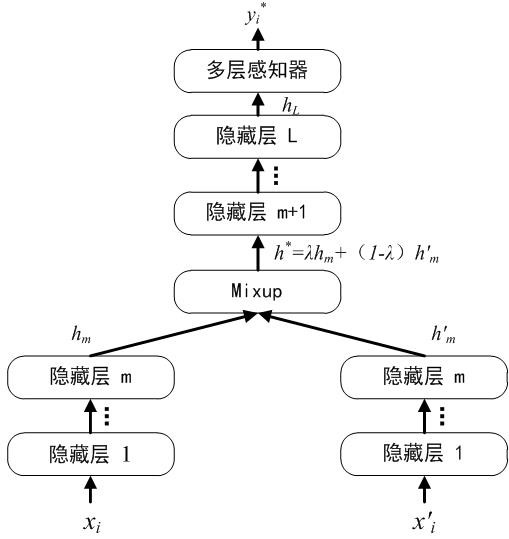
[0123] In this embodiment, the microblog data set is subjected to emotion extraction of positive, angry, sad, surprised and fearful five types of emotions, and five binary classification models are trained, and each binary classification model uses 150 labeled texts containing the emotion, 150 Texts that do not contain the emotion and 40,000 unlabeled texts are used to construct a training set. The basic steps are as described in S1~S5 above, and will not be repeated here. The following will mainly show some specific implementation details and effects of each step.
[0124] 1. According to the method described in steps S1~S5, use the PyTorch deep learning framework to build a text classification model for the board. The hyperparameters of the model mainly include the following categories:
[0125] 1) Augmented labeled dataset for each iteration training input X labled Annotated sample x i l Quantity batch_size_L=2; 2) Augmented unlabeled dataset for each iteration training...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More