

Drug risk grading method based on naive random oversampling and support vector machine
A technology of support vector machine and risk classification, which is applied in the field of drug risk classification based on naive random oversampling and support vector machine, which can solve the problems of lack of machine learning automatic decision-making and so on.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


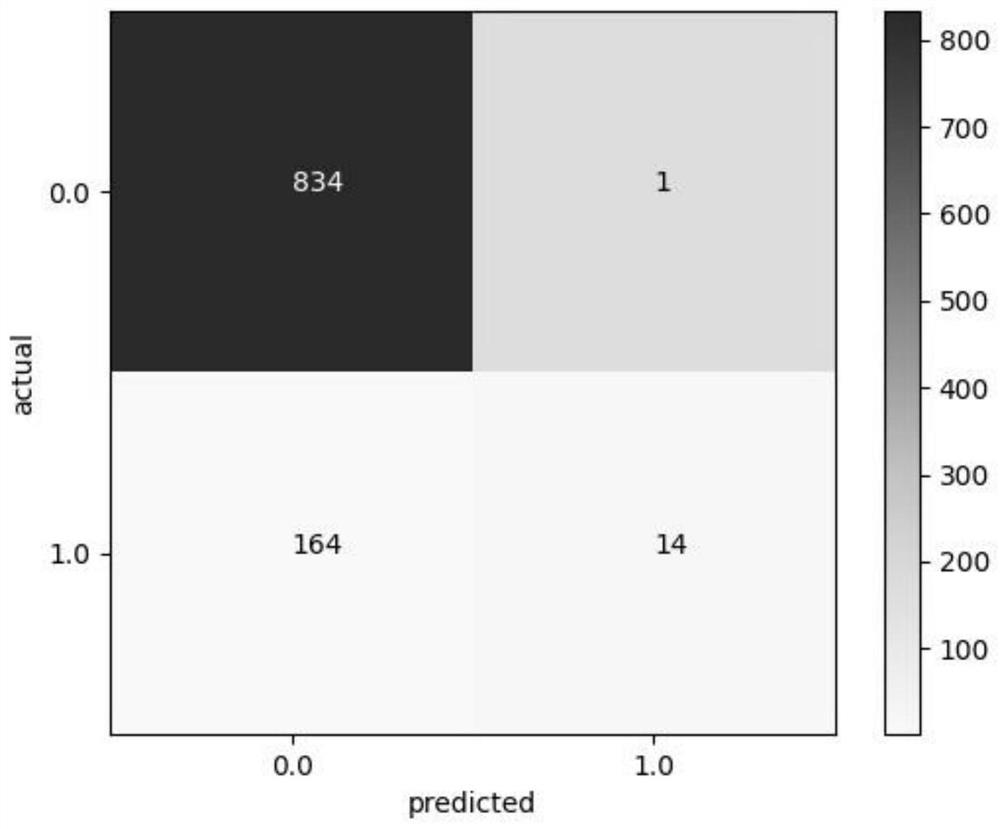
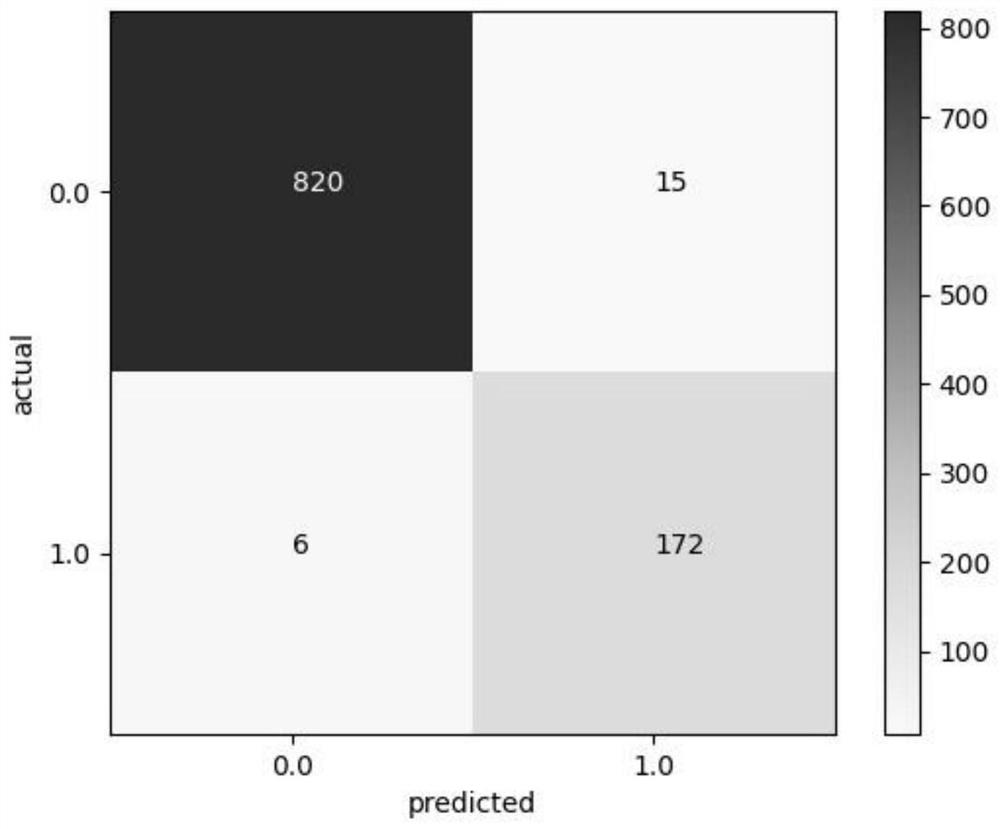
Examples
Embodiment 1
[0060] The method for drug risk classification based on naive random oversampling and support vector machine includes the following steps:
[0061] Step 1: Query the factors associated with the risk of adverse drug reactions in the spontaneously reported data, and establish the I 1 , I 2 , I 3 as an indicator of risk;
[0062] Step 2: Calculate the three index values of each drug based on the self-reported data;
[0063] The third step: taking drugs as objects and using three indicators as characteristics to establish a drug risk matrix;
[0064] Step 4: According to the National Essential Drugs List, classify the two types of drugs in the drug risk matrix. Prescription drugs are marked as "0" and non-prescription drugs are marked as "1". The marked data set is the original data, which is recorded as D 0 ;
[0065] Step 5: Since the number of prescription drugs is much larger than that of non-prescription drugs, the sample expansion of non-prescription drug data in the ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More