

Crowdsourcing test report similarity detection method based on natural language processing
A natural language processing and test report technology, applied in natural language data processing, software testing/debugging, electrical digital data processing, etc., can solve problems such as poor detection results of similar reports
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
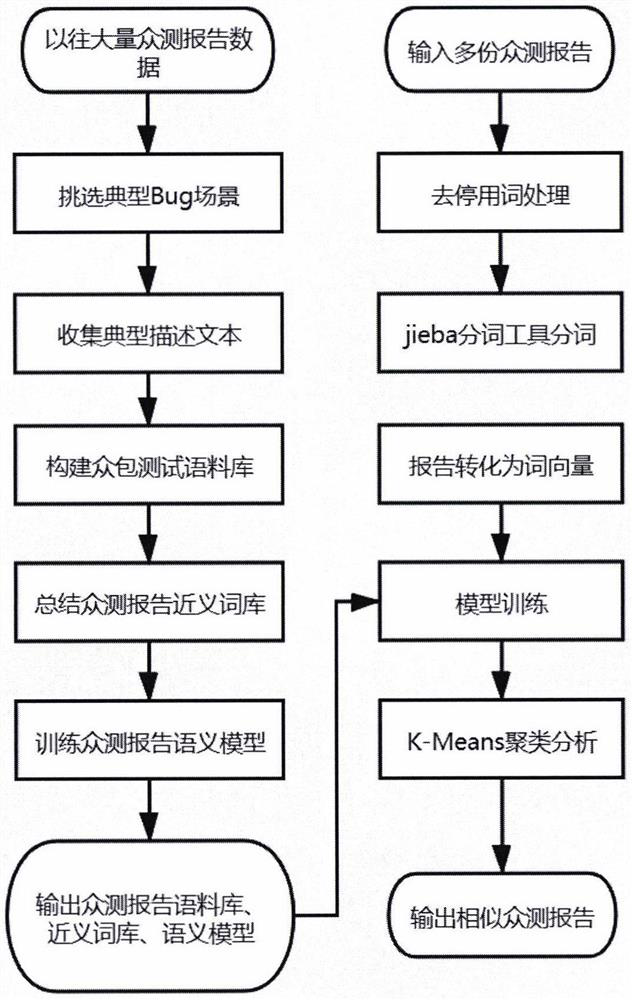
[0024] Several key technologies involved in the present invention are jieba word segmentation, Word2Vec model, K-means clustering and LSTM-DSSM deep learning model.
[0025] 1. Jieba participle
[0026] jieba is currently the best Chinese word segmentation component for Python. It mainly has the following three features. 1. Support 3 participle word mode
[0027] Mode: exact mode, full mode, search engine mode. 2. Support traditional word segmentation. 3. Support custom dictionary.
[0028] 2. Word2Vec model
[0029] Word2Vec, is a group of related models used to generate word vectors. These models are shallow, two-layer neural networks that are trained to reconstruct the linguistic text. The network is represented in terms of words and needs to guess the input words in adjacent positions. Under the assumption of the bag-of-words model in Word2Vec, the order of words is unimportant. After the training is completed, the Word2Vec model can be used to map each word to a v...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More