

Cross-modal video time sequence action positioning method and system based on time sequence-space diagram
A positioning method and spatial map technology, applied in stereoscopic systems, image communication, character and pattern recognition, etc., can solve the problems of single length, neglect of interactive information, and low accuracy of positioning results, and achieve the effect of enhancing representation and improving accuracy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

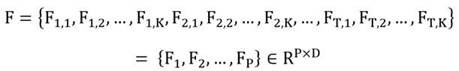
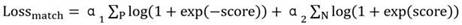
Examples
Embodiment 1
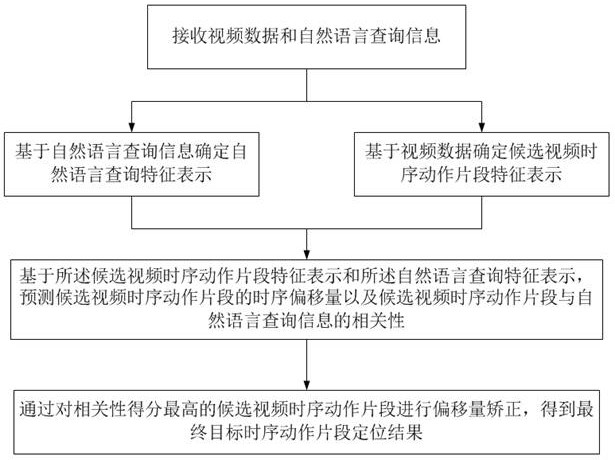
[0062] This embodiment provides a method for locating time-series actions in cross-modal videos based on a time-spatial diagram. The specific scheme of this embodiment is as follows figure 1 As shown, the method includes the following steps:
[0063] Step (1): Receive video data and natural language query information;
[0064] Step (2): Determine the natural language query feature representation based on the natural language query information;
[0065] Step (3): Based on the video data, determine the feature representation of the candidate video sequence action segment;
[0066] Step (4): Based on the feature representation of the candidate video sequence action segment and the natural language query feature representation, predict the timing offset of the candidate video sequence action segment and the candidate video sequence action segment and natural language query information relevance;
[0067] Step (5): By performing offset correction on the candidate video timing ac...
Embodiment 2
[0118] This embodiment provides a temporal-spatial diagram-based time-series action location system for cross-modal videos.
[0119] A time-series action localization system for cross-modal videos based on time-spatial graphs, including:
[0120] a data collection module configured to receive video data and natural language query information;
[0121] A language feature representation determining module configured to determine a natural language query feature representation based on natural language query information;
[0122] The video feature representation determination module is configured to determine the feature representation of the candidate video timing action segment based on the video data;
[0123] The feature representation analysis module is configured to predict the timing offset of the candidate video sequence action segment and the difference between the candidate video sequence action segment and the natural language query feature representation based on the...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More