Text compression method and device, text decompression method and device, computer equipment and storage medium
A text compression and computer program technology, applied in the field of data processing, can solve the problems of unavailable compression ratio and high compression files, etc., achieve the effect of compact representation and increase compression ratio
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
[0039] In order to make the purpose, technical solutions and advantages of the embodiments of the present application clearer, the technical solutions in the embodiments of the present application will be clearly and completely described below in conjunction with the drawings in the embodiments of the present application. Obviously, the described embodiments It is a part of the embodiments of this application, but not all of them. Based on the embodiments in this application, all other embodiments obtained by persons of ordinary skill in the art without making creative efforts belong to the scope of protection of this application.
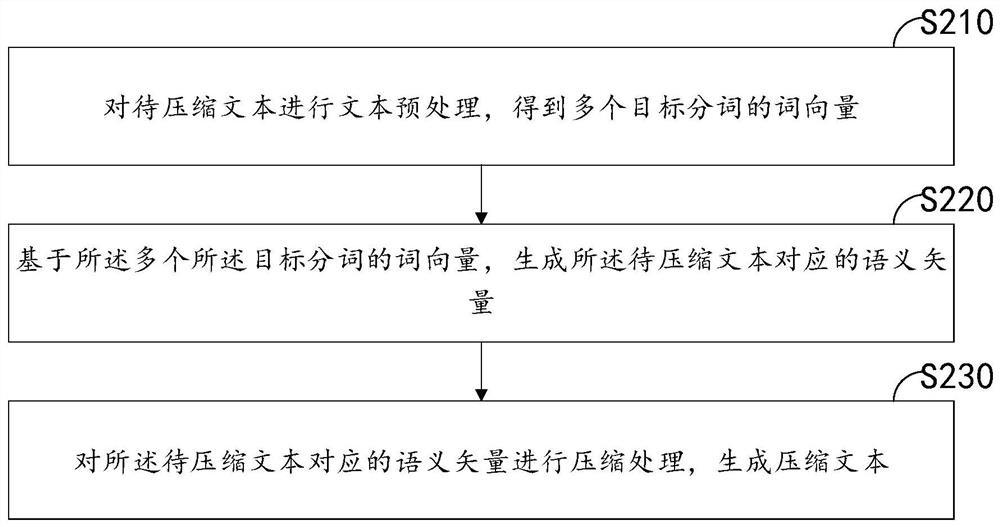
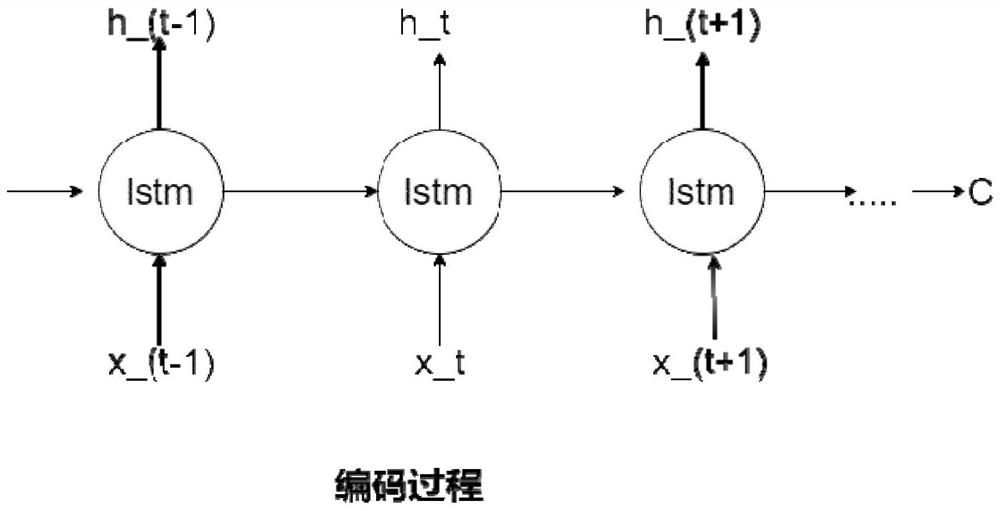
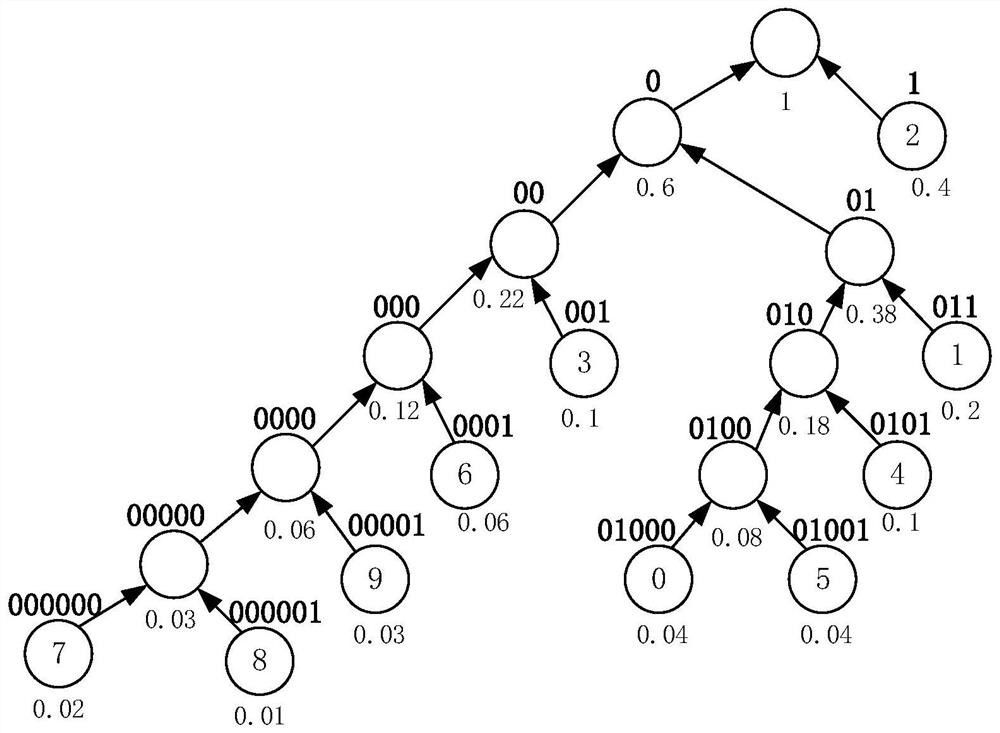
[0040] In one embodiment, figure 1 It is a schematic flow chart of a text compression method in an embodiment, referring to figure 1 , which provides a text compression method. This embodiment is mainly illustrated by applying the method to the server 120. The text compression method specifically includes the following steps:
[0041] Step S210,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More