

GP world model using strategy model to assist in training and training method thereof
A technology for world model, strategy
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment 2
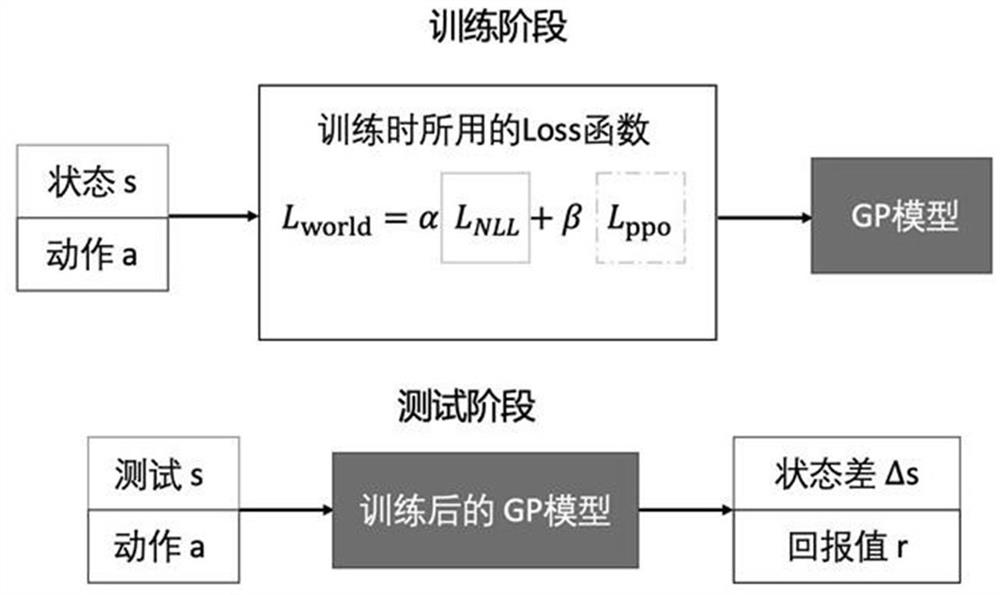
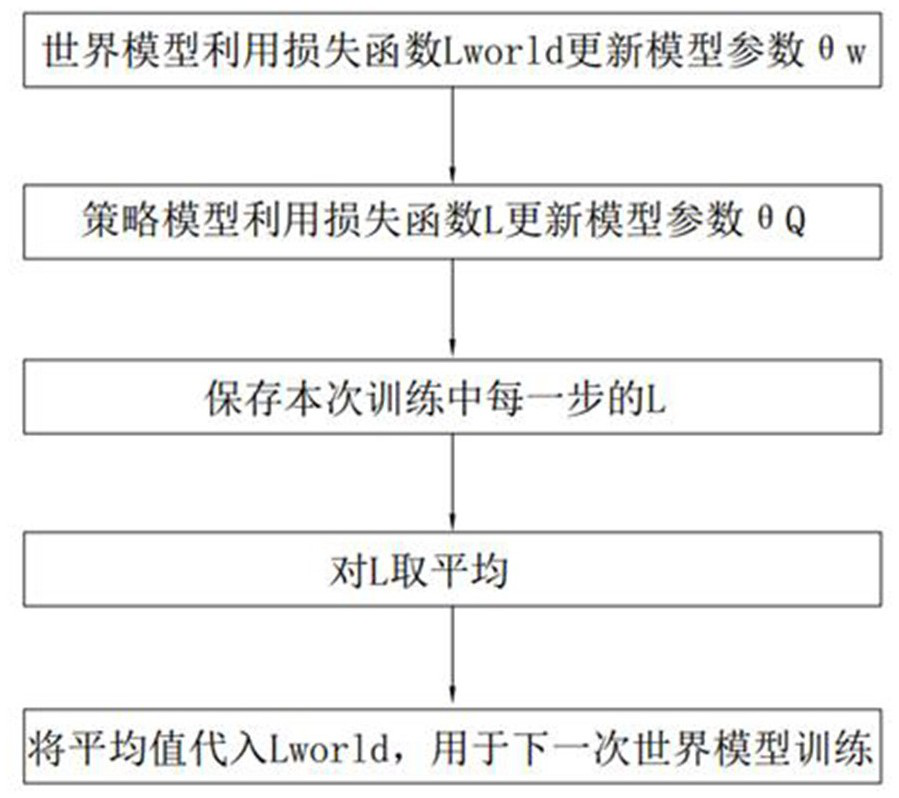
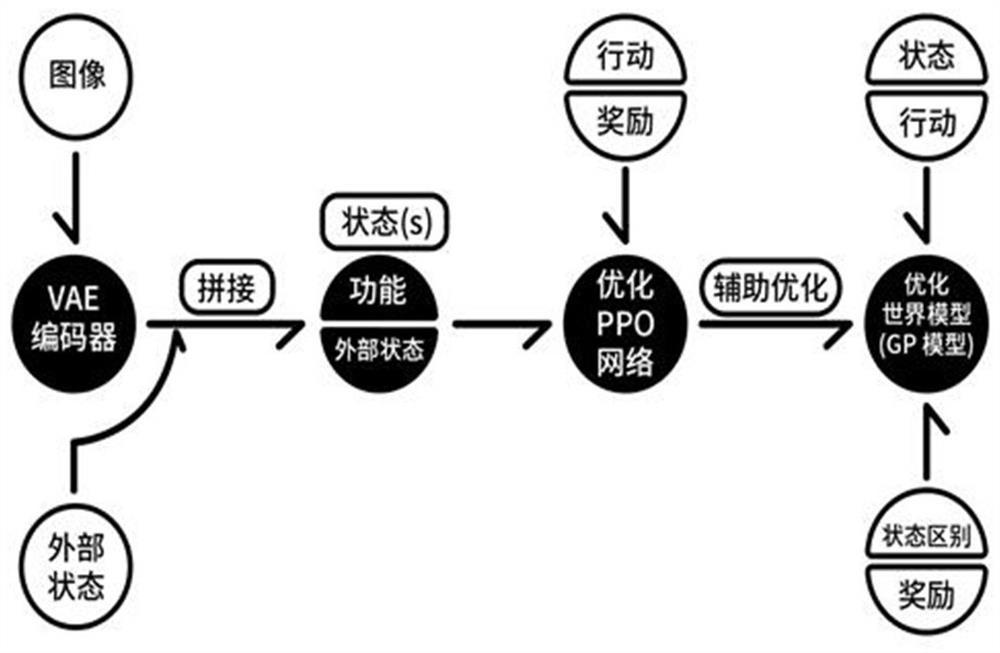
[0065] In this embodiment, this solution is used in the Dyna-PPO framework designed by the applicant to realize continuous action decision-making. In this framework, the policy model includes the PPO algorithm, so the second loss function in this embodiment is the loss of the PPO algorithm. function.
[0066] The PPO algorithm is a new policy gradient (Policy Gradient, PG) algorithm. The PPO method encourages exploration and limits policy changes to keep the policy update slow. It is a method that integrates intelligence optimization and policy optimization and can be used to process Continuity of motion problem. The PPO algorithm proposes that the objective function can be updated in small batches in multiple training steps, which solves the problem that the step size is difficult to determine in the traditional policy gradient algorithm. It will try to calculate a new strategy in each iteration step, and can achieve a new balance between the ease of implementation, sampling...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More