

Imbalanced data classification method based on clustering and distance weighting
A data classification and distance weighting technology, which is applied in character and pattern recognition, instruments, calculations, etc., can solve the problem of low recognition rate, achieve the effect of increasing importance, improving generalization performance, and reducing importance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image



Examples
Embodiment Construction
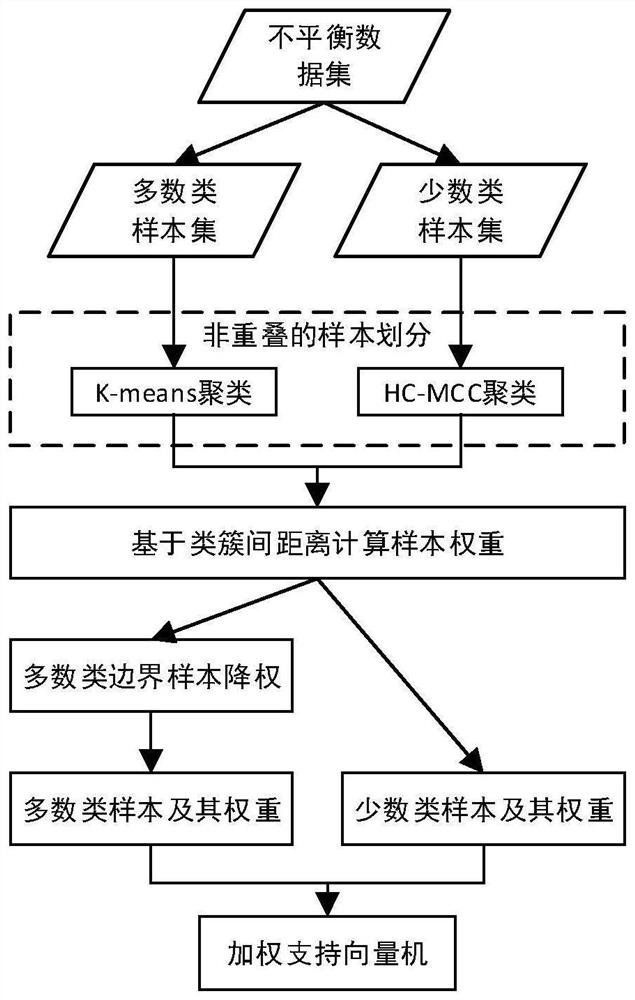
[0026] In order to make the objectives, technical solutions and technical effects of the present invention clearer, the present invention will be further described in detail below with reference to specific embodiments and simulation experiments.
[0027] like figure 1 As shown, an imbalanced data classification method based on clustering and distance weighting specifically includes the following steps:
[0028] Step 1. Data collection and preprocessing
[0029] Collect realistic imbalanced datasets from the UCI machine learning database T={(x 1 , y 1 ), (x 2 , y 2 ),...,(x N , y N )},in y i ∈{+1,-1}, i=1,2,...N, N is the total number of samples in the dataset. Divide the dataset into a minority class sample set X according to the target class label MN and the majority class sample set X MX , and the dataset imbalance rate is calculated by the following formula:
[0030]
[0031] In the above formula, N - is the number of samples of the majority class (negativ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More