

Method, system and device for efficient memory replacement between GPU devices and storage medium
A device-to-device and memory technology, applied in inter-program communication, multi-program device, processor architecture/configuration, etc., can solve problems such as insufficient memory, unbalanced memory requirements, etc., to reduce memory constraints, retrieve data in time, The effect of reducing memory
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment 1
[0026] An embodiment of the present invention provides a method for efficient memory replacement between GPU devices, which is a method for efficient memory replacement between GPU devices in a pipeline parallel scenario to reduce memory constraints. It mainly includes the following steps:
[0027] 1. Allocate work components for GPU devices participating in the swap work.
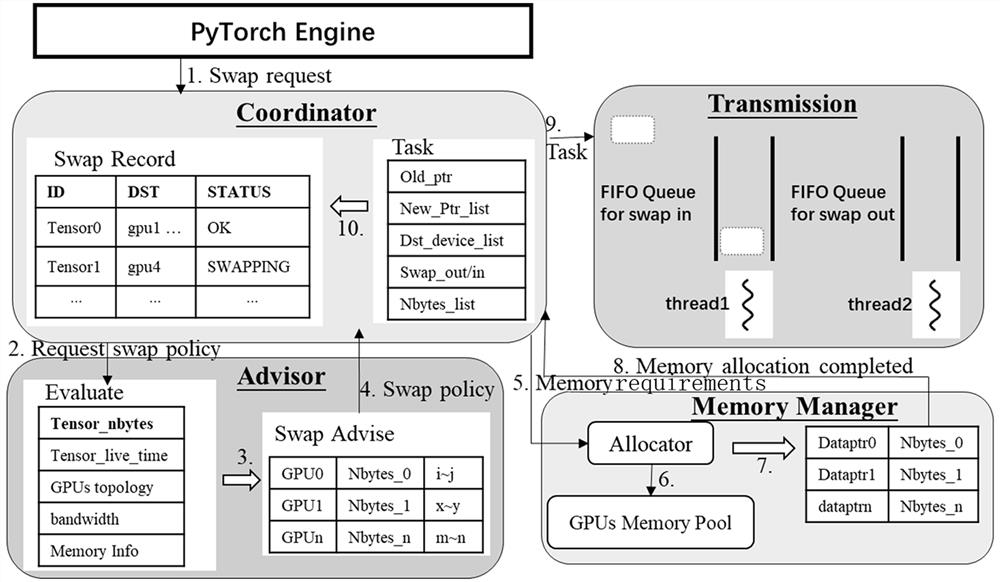
[0028] In the embodiment of the present invention, the work components mainly include: an advisor (Advisor), a memory manager (MemoryManager), a coordinator (Coordinator), and a transmitter (Transmission). like figure 1 shown, the architecture of the above four working components in a single GPU device is shown.
[0029] In the embodiment of the present invention, the GPUs participating in the work are other GPU devices including high memory load GPU devices, the high memory load GPU devices refer to the GPU devices whose memory load exceeds the set threshold, and the other GPU devices refer to the non-h...
Embodiment 2
[0052] The present invention also provides a system for efficient memory replacement between GPU devices, which is mainly implemented based on the methods provided in the foregoing embodiments, such as Figure 4 As shown, the system mainly includes:
[0053] The work component allocation unit is used to allocate work components to the GPU devices participating in the exchange work, including: proposers, memory managers, coordinators and transmitters;
[0054] The memory replacement unit is used to realize the memory replacement between GPU devices through work components, and the steps include: when the coordinator of the current GPU device receives the data exchange request, if the type of the data exchange request is data unloading, the proposer determines the relevant The data exchange scheme, and the memory manager allocates memory of the corresponding size in the destination GPU device according to the data exchange scheme, and generates the destination space information ...
Embodiment 3
[0057] The present invention also provides a processing device, such as Figure 5 As shown, it mainly includes: one or more processors; a memory for storing one or more programs; wherein, when the one or more programs are executed by the one or more processors, the One or more processors implement the methods provided by the foregoing embodiments.
[0058] Further, the processing device further includes at least one input device and at least one output device; in the processing device, the processor, the memory, the input device, and the output device are connected through a bus.
[0059] In this embodiment of the present invention, the specific types of the memory, the input device, and the output device are not limited; for example:
[0060] The input device can be a touch screen, an image capture device, a physical button or a mouse, etc.;
[0061] The output device can be a display terminal;
[0062]The memory may be random access memory (Random Access Memory, RAM), or ...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More