Real-time data on-line compression and decompression method
A real-time data and decompression technology, applied in the direction of electrical digital data processing, digital recording/reproduction, instruments, etc., can solve the problems of limited compression ratio, limited compression algorithm, low efficiency, etc., achieve high compression ratio, and realize online compression The effect of storing, flattening and decompressing reads
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


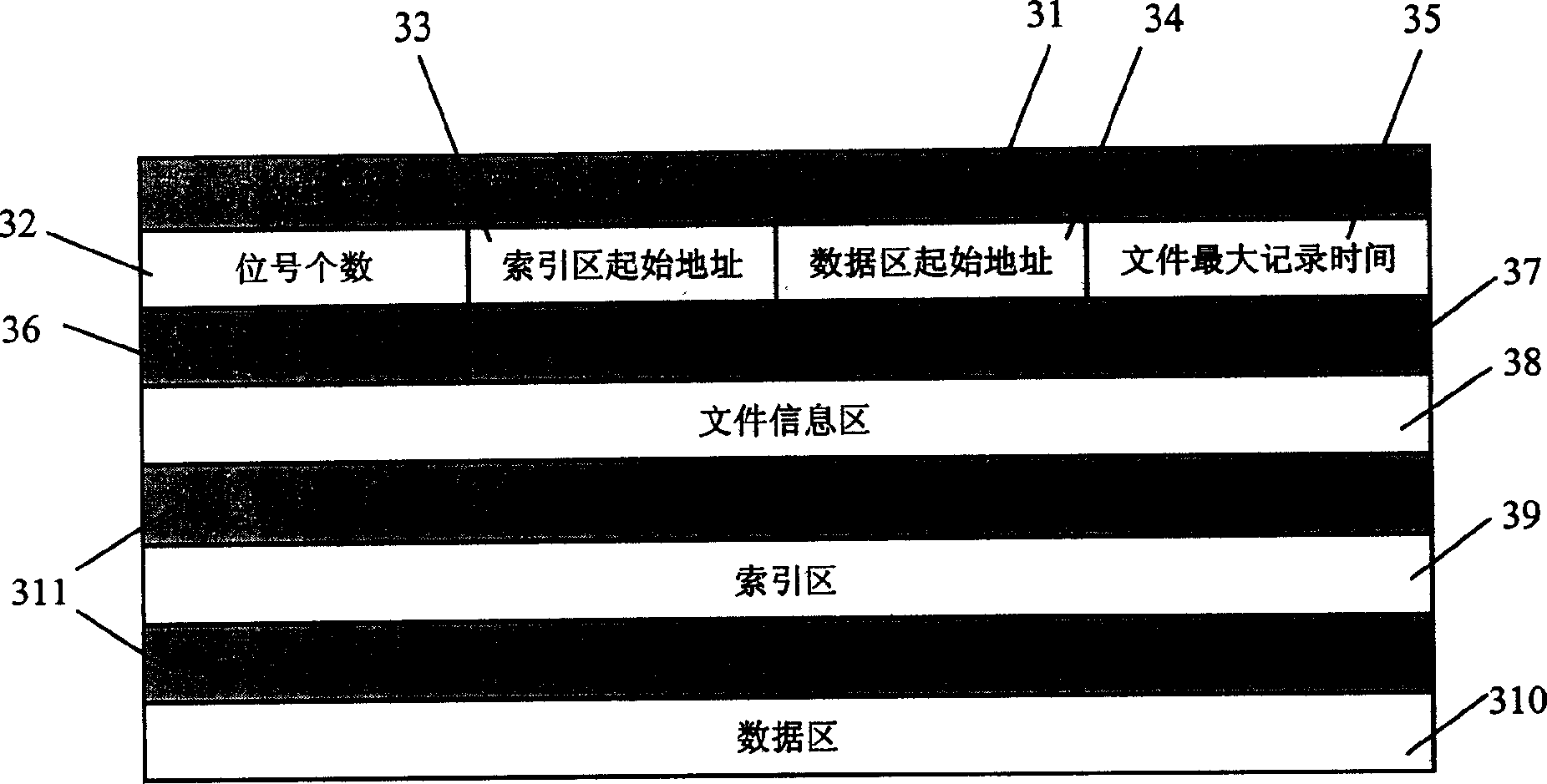
Examples
Embodiment Construction
[0047] The technical solutions of the present invention will be further described below in conjunction with the drawings and embodiments.
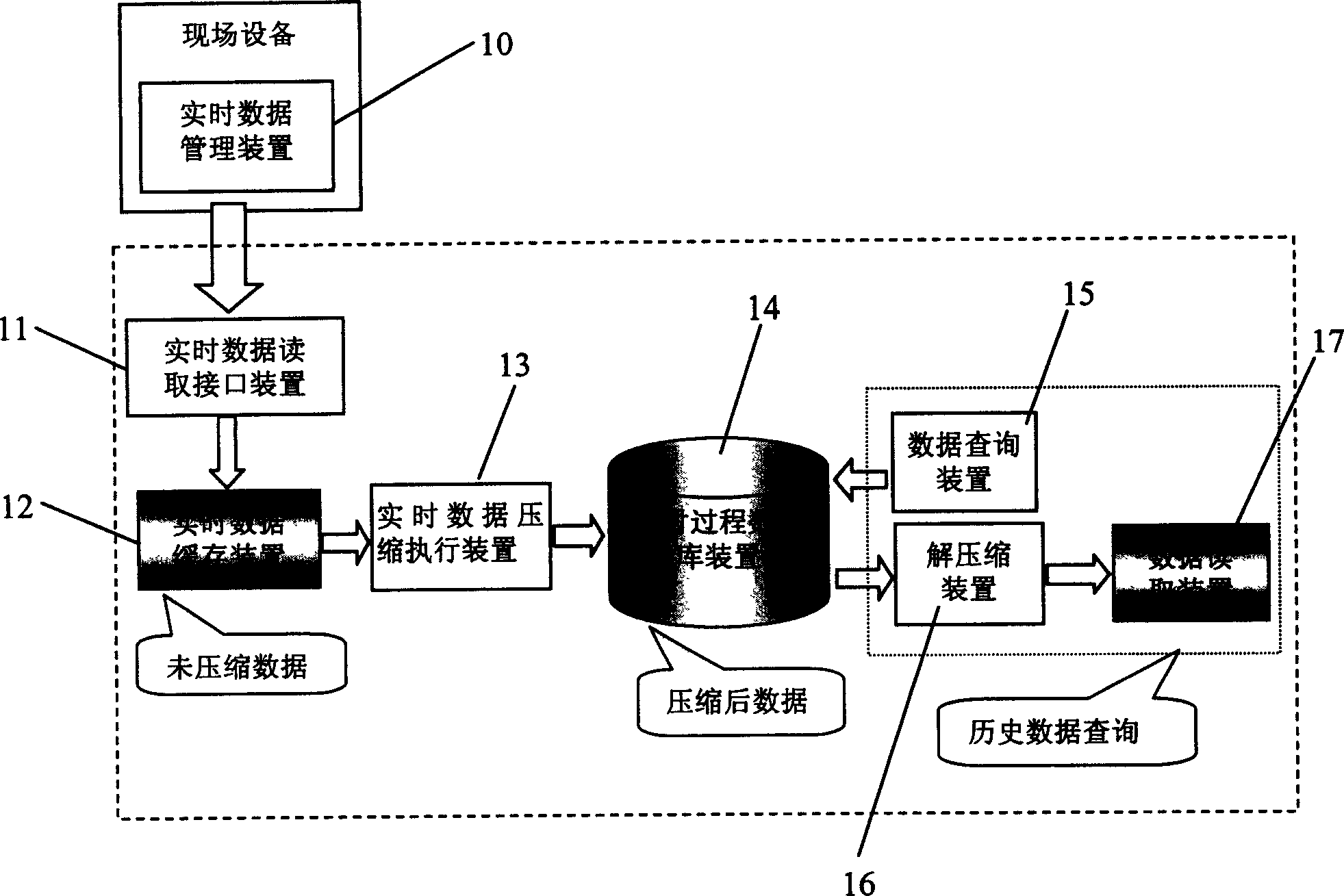
[0048] see figure 1 , is a block diagram of the overall structure of the present invention. It is a device adopting the real-time data online compression and decompression method described in the present invention, which includes a real-time data reading interface device 11, a real-time data cache device 12, a real-time data compression execution device 13, a real-time process database device 14, a data Inquiry device 15, decompression device 16, data reading device 17;
[0049] The real-time data reading interface device 11 is mainly responsible for the acquisition of data during the operation of the process monitoring system. Read the corresponding tag information list and its data;
[0050] The real-time data cache device 12 is used to temporarily store the bit number information obtained by the real-time data reading interface devic...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More 
PatSnap Eureka turns technology decisions into work you can execute. Powered by our Innovation Knowledge Graph, it runs expert workflows across engineering, life sciences, materials and intellectual property. Get your review-ready output in minutes.



