

Method of reducing redundancy between two or more datasets
a dataset and redundancy reduction technology, applied in the field of system and method for storing data, can solve the problems of limiting the number of backups the user maintains, consuming a great deal of disk space, and modern disk drives also have undesirable properties, so as to achieve lower deduplication efficiency, high deduplication efficiency, and high deduplication performance
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Benefits of technology
Problems solved by technology
Method used
Image

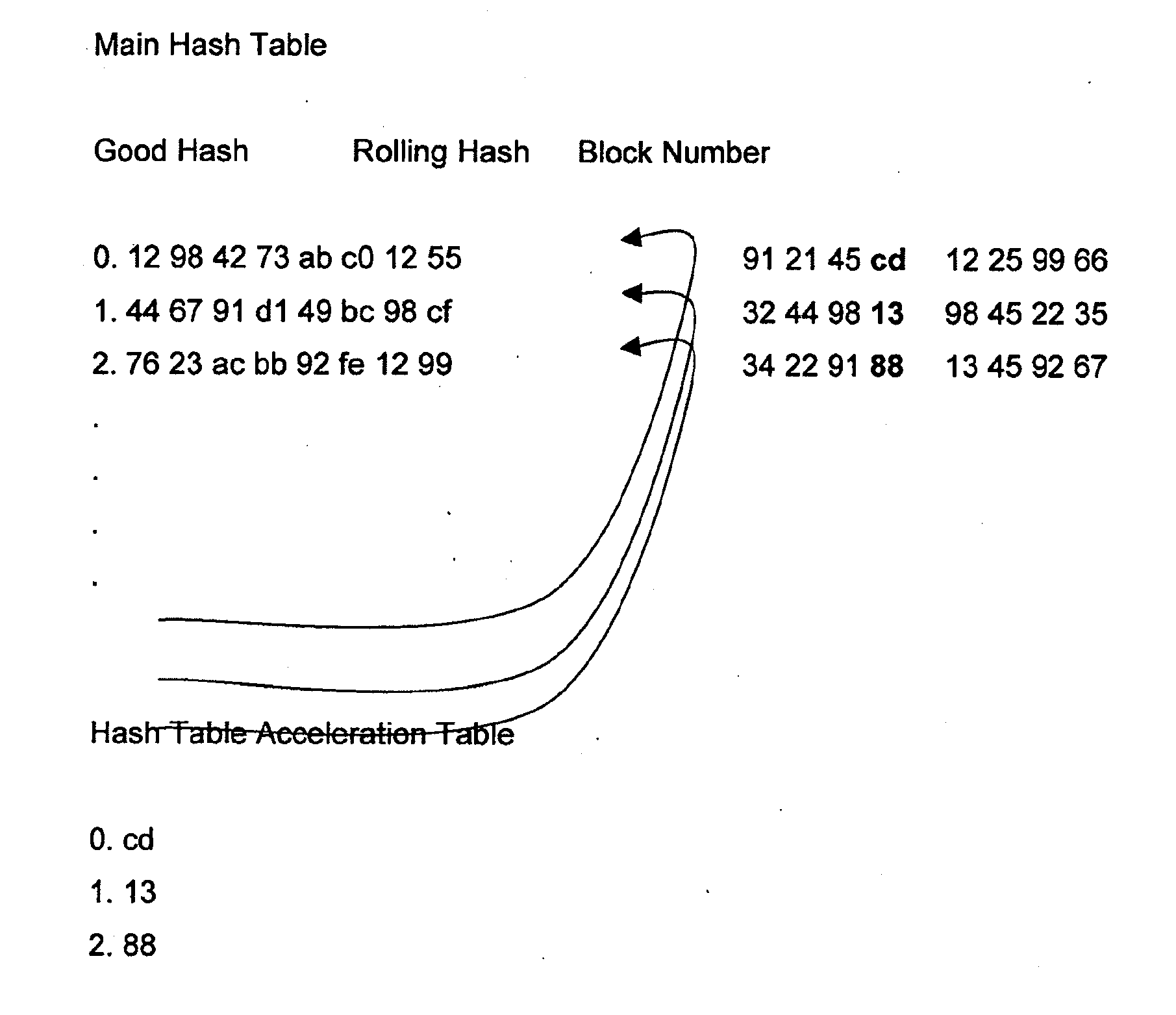
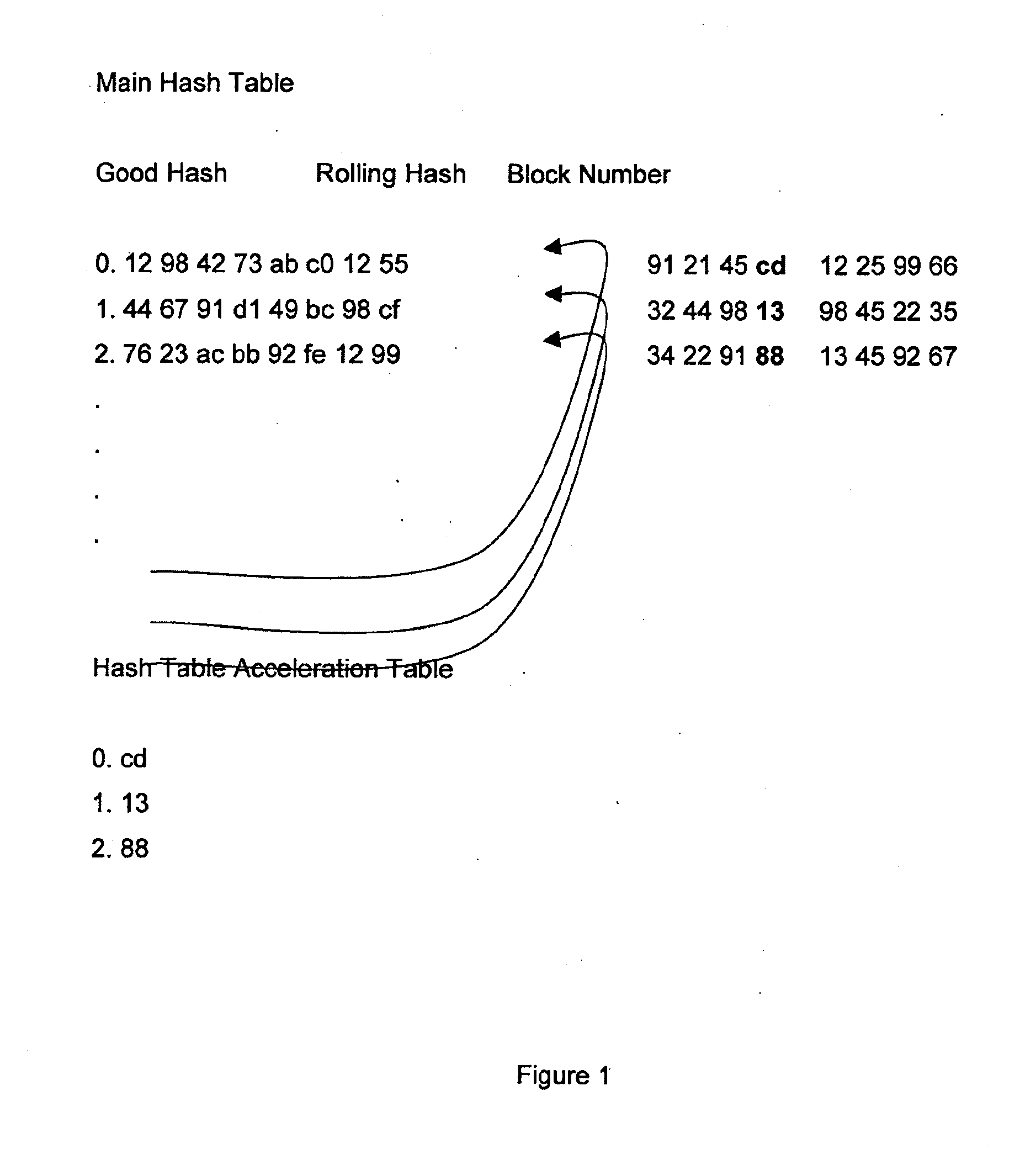
Examples
example cases
XXXVI. Example Cases
XXXVI. (1) Worst Case
[0548]As those familiar with the art of compression know, no compression technique is guaranteed to produce compression. Indeed, under worst-case conditions, every compression technique is guaranteed to produce output that is larger than its inputs.
[0549]Our Method is no exception and it is useful to understand this Method's limitations.
[0550]The amount of compression that one is likely to get from our Method is, on average, dependent on the size of the DDS; the larger the DDS the more likely it is that our Method will be able to detect and eliminate common data redundancy.
[0551]Consider a DDS with zero entries. The Method will proceed, roughly, as follows:
[0552]A pointless “Reference File Analysis Phase” would be done to build a non-existent DDS. As usual, the Reference File would be physically and / or logically copied to the Extended Reference File while digests are inserted into the DDS. Since the DDS has, by our example, no entries then th...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More