

Method for removing repeated object based on metadata
A technology for repeating objects and metadata, applied in the field of data cleaning, can solve the problems that the accurate weight judgment scheme cannot be suitable for partial data errors in metadata, and cannot fully meet the requirements of metadata weight judgment, so as to narrow the scope of comparison and reduce the workload , the effect of improving work efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image


Examples
Embodiment Construction
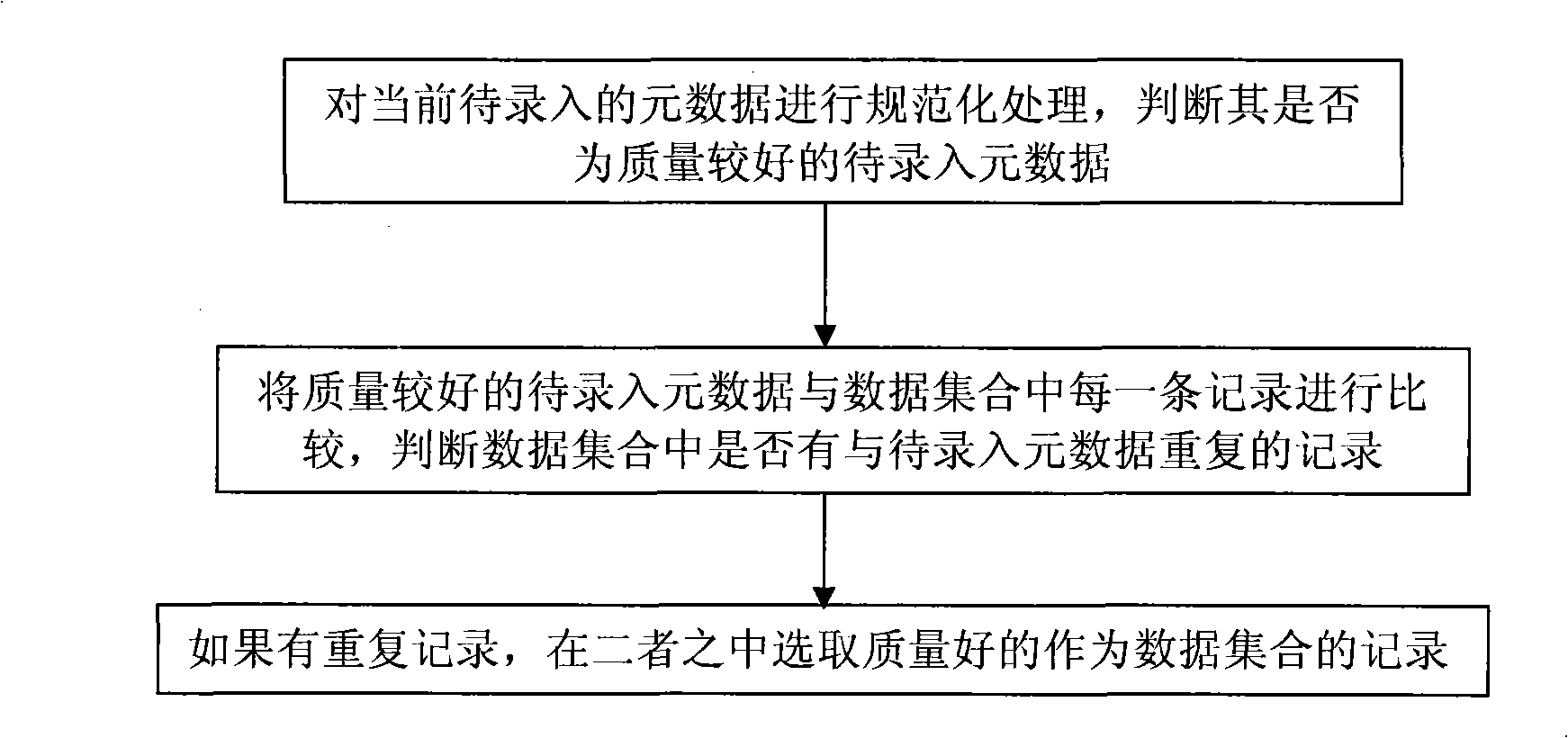
[0042] Aiming at the problem of heavy workload for removing dirty data in the existing metadata cleaning field, the present invention provides a method for removing duplicate objects based on metadata, refer to the attached figure 1 , which includes the following steps:
[0043] 1) Standardize the metadata currently to be entered, and judge whether it is metadata to be entered with good quality;
[0044] 2) Compare the better-quality metadata to be entered with each record in the data set, and determine whether there is a duplicate record in the data set with the metadata to be entered;
[0045] 3) If there are duplicate records, select a record with good quality among the two as the data set.
[0046]The information of a book on the Internet includes a large amount of metadata, most of which are dirty data, that is, data with poor quality. For example: Title: Romance of the Three Kingdoms; International Standard Book Number: ISBN7-305-01568-7; Publisher Number: 305; Publish...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More