Method for automatically acquiring new words from Chinese webpages
A new word and webpage technology, applied in the field of Internet data mining, can solve problems such as low algorithm efficiency, leakage of user privacy, poor Chinese support, etc., and achieve the effect of improving accuracy and processing efficiency
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
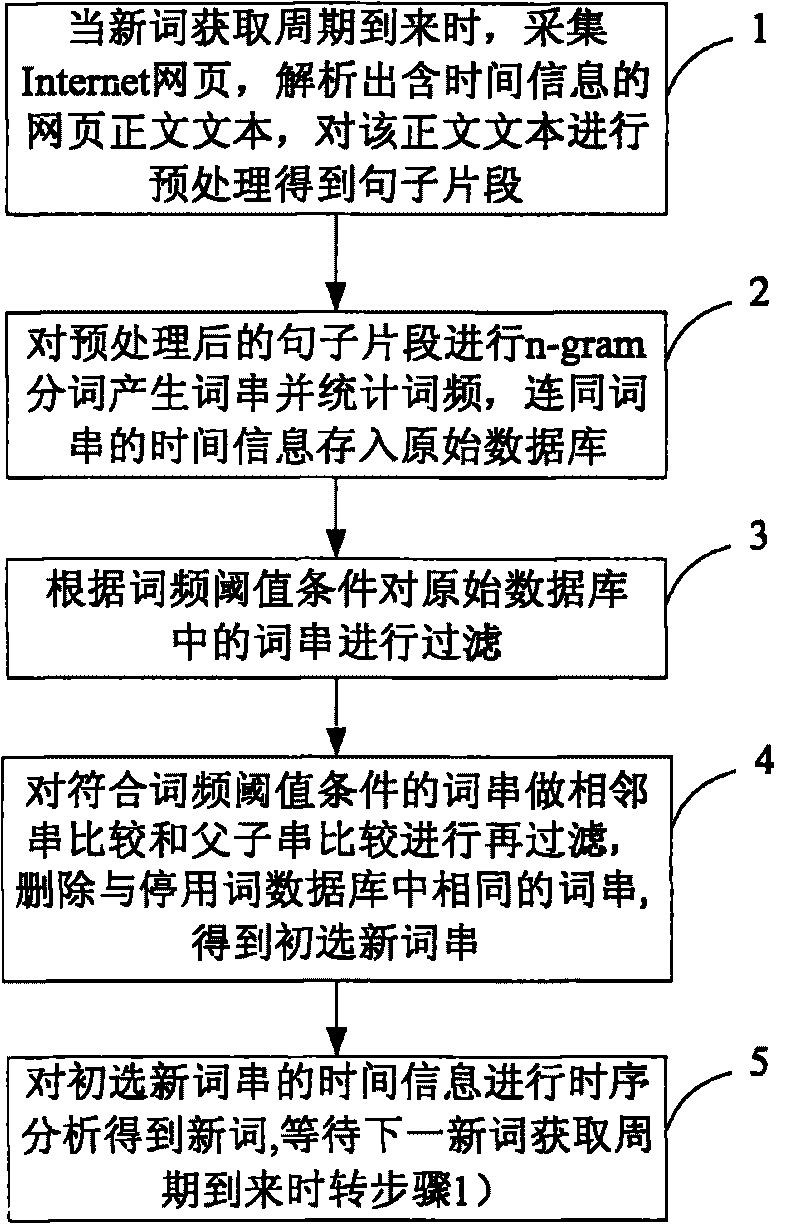
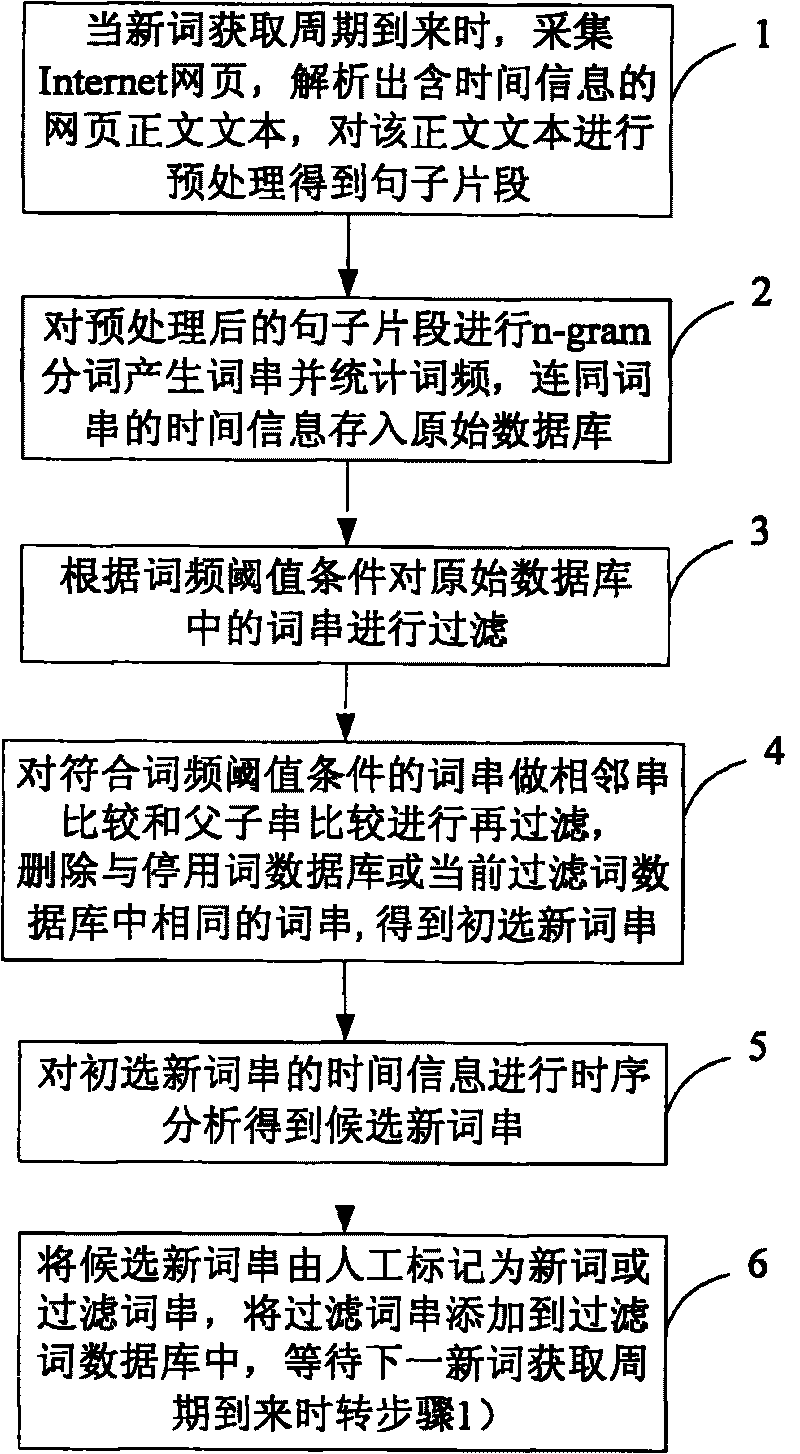
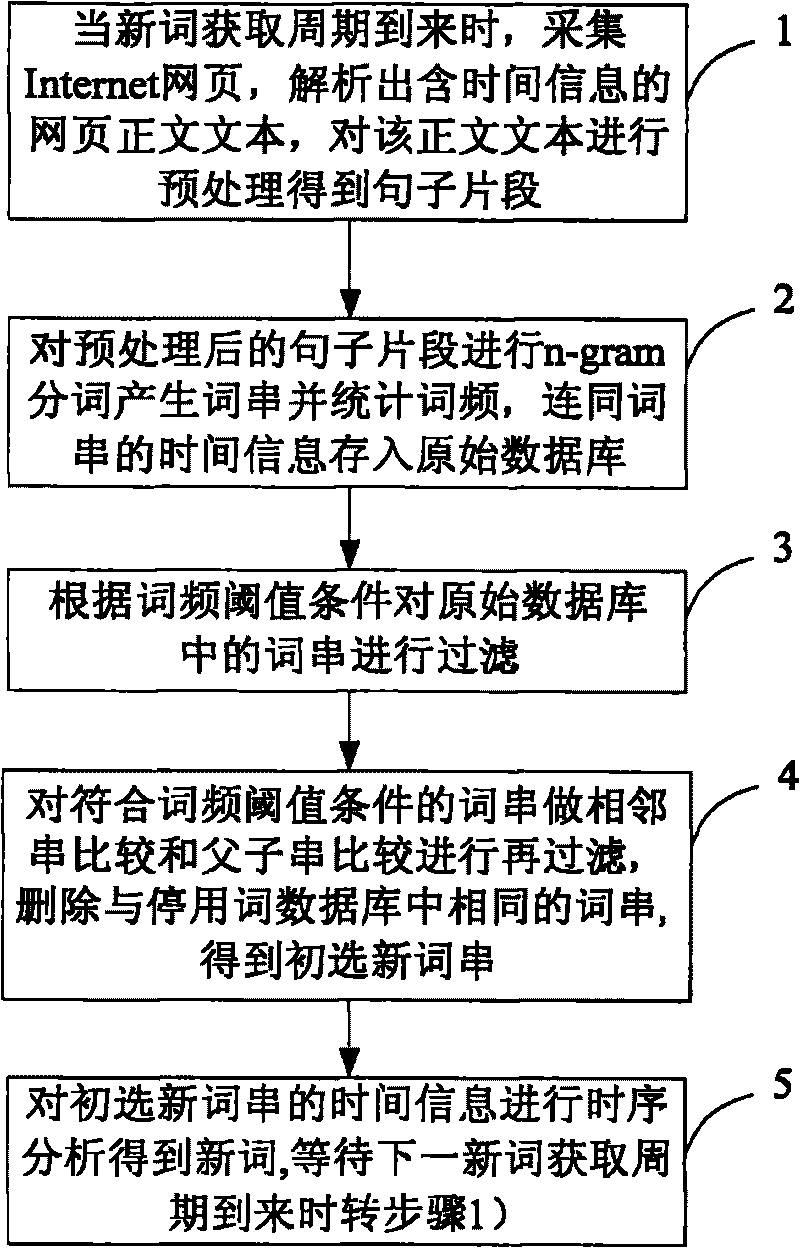
[0055] A kind of Chinese web page neologism automatic acquisition method that the present invention proposes, in conjunction with accompanying drawing and embodiment describe in detail as follows:
[0056] A kind of method that the present invention proposes automatic acquisition of new words in Chinese web pages, at first set original database and stop words database; Described original database is initially set as empty, is used for depositing the data that produces in the processing process of this new word acquisition method; The above-mentioned stop word database pre-stores words that cannot appear according to the Chinese language rules (can also be changed at any time according to needs), and used words to be deleted; set the new word acquisition cycle (the length of the cycle can be adjusted according to actual application needs) If you want to get new words in the near future, you can set the period to be short, otherwise you can set the period to be longer, and you ca...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More - Generate Ideas
- Intellectual Property
- Life Sciences
- Materials
- Tech Scout
- Unparalleled Data Quality
- Higher Quality Content
- 60% Fewer Hallucinations
Browse by: Latest US Patents, China's latest patents, Technical Efficacy Thesaurus, Application Domain, Technology Topic, Popular Technical Reports.
© 2025 PatSnap. All rights reserved.Legal|Privacy policy|Modern Slavery Act Transparency Statement|Sitemap|About US| Contact US: help@patsnap.com