

Automatic extraction method of web page information based on WEB structure
A technology for automatic extraction of web page information, applied in the Internet field, can solve the problem that applications cannot directly parse and utilize massive information, and achieve the effect of good extraction, noise reduction, and wide versatility.
- Summary
- Abstract
- Description
- Claims
- Application Information
AI Technical Summary
Problems solved by technology
Method used
Image

Examples
Embodiment Construction
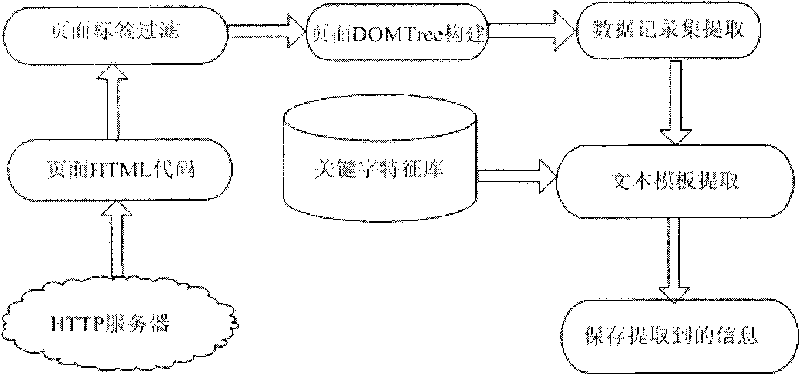
[0045] see figure 1 , the present invention includes the following modules: HTML source code acquisition module, DOMTree generation module, data record set extraction module, information extraction template generation module and intelligent classification module, first the HTML source code acquisition module obtains the HTML source code through the webpage URL; Then the DOMTree generation module corrects the wrong tags in the HTML, and filters the noise tags at the same time, and then generates a preprocessed page DOMTree; then extracts the data record set in the page according to the DOMTree characteristics of the page, and according to certain rules. The noise record set is filtered out, the acquired record set is analyzed, and the detailed information contained in it is obtained; at the same time, the extracted data record set is handed over to the information extraction template generation module for processing, and the information extraction template is generated; finally,...
PUM
 Login to View More
Login to View More Abstract
Description
Claims
Application Information
 Login to View More
Login to View More