Pronunciation quality assessment and error detection method based on fusion of multiple characteristics and multiple systems
What is AI technical title?
AI technical title is built by PatSnap AI team. It summarizes the technical point description of the patent document.
A technology for quality assessment and error detection, applied in speech analysis, speech recognition, instruments, etc.
Active Publication Date: 2011-10-19
IFLYTEK CO LTD
View PDF4 Cites 0 Cited by
Summary
Abstract
Description
Claims
Application Information
AI Technical Summary
This helps you quickly interpret patents by identifying the three key elements:
Problems solved by technology
Method used
Benefits of technology
Problems solved by technology
[0005] In view of this, in view of the shortcomings of using a single feature and method in the prior art for pronunciation quality assessment and error detection, the main purpose of the present invention is to provide a method for pronunciation quality assessment and error detection based on multi-feature and multi-system fusion, to effectively Using a variety of speech features, making full use of a variety of evaluation and detection systems and performing information fusion, so as to maximize the advantages of various features and systems, and ensure the accuracy and reliability of pronunciation evaluation and error detection
Method used
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
View more
Image
Smart Image Click on the blue labels to locate them in the text.
Viewing Examples
Smart Image
Click on the blue label to locate the original text in one second.
Reading with bidirectional positioning of images and text.
Smart Image
Examples
Experimental program
Comparison scheme
Effect test
no. 1 example
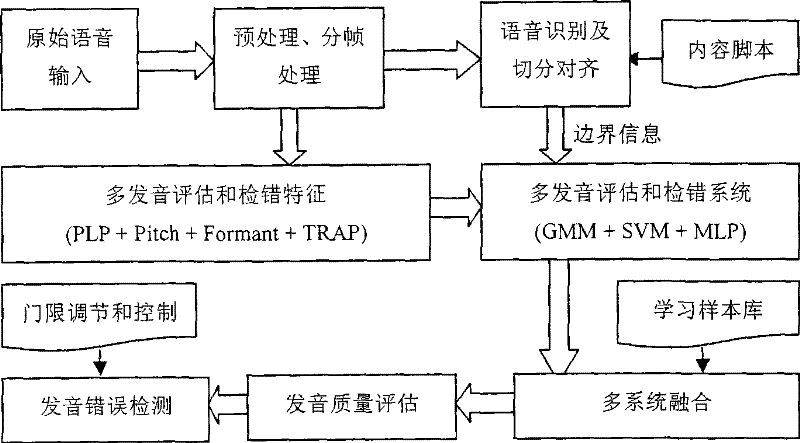
[0119] see Figure 1 to Figure 6 As shown, it is a flow chart of the first embodiment of the present invention, which evaluates and detects errors in the quality of vocabulary pronunciation, and its steps are:
[0120] Step 101, the user reads out the vocabulary speech that needs to be evaluated and checked;
[0121] Step 102, the original voice is preprocessed, the frame length is 25ms, and the frame interval is 10ms, and the processing is repeated until the voice signal ends;
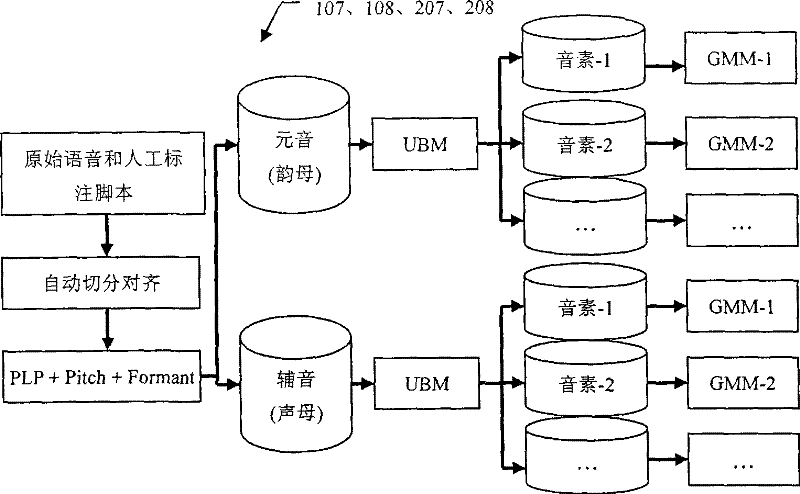
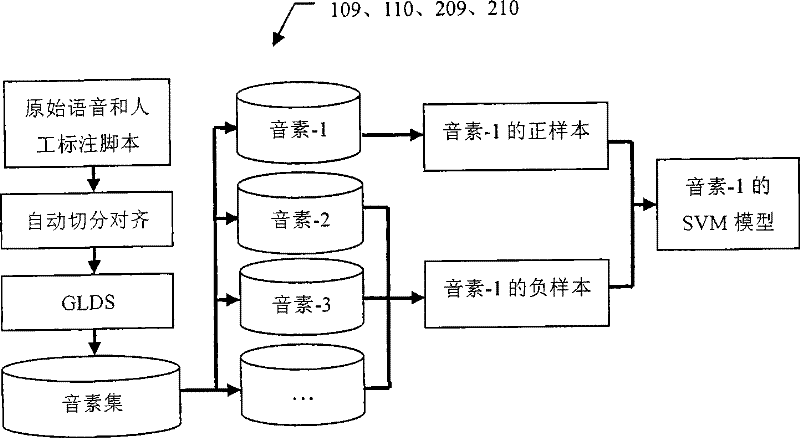
[0122] Step 103, when the content of the vocabulary is known, the speech is automatically segmented and aligned, and the speech recognition link is omitted for the vocabulary speech. The pronunciation model used for segmentation and alignment is trained using a large number of manually labeled Chinese or English corpora. English uses 44 phoneme pronunciation models (20 vowels, 24 consonants), and Chinese uses 61 phoneme pronunciation models (36 finals, 25 initials, including zero initials). The tra...
no. 2 example
[0141] see Figure 1 to Figure 5 ,as well as Figure 7 Shown, be the flow chart of the second embodiment of the present invention, the pronunciation quality of paragraph reading question type in the oral English test is evaluated and error detection, and its steps are:
[0142] Step 201, the examinee reads the English paragraph that needs to be evaluated and checked;
[0143] Step 202, the original voice is preprocessed, the frame length is 25ms, and the frame interval is 10ms, and the processing is repeated until the voice signal ends;
[0144] Step 203, performing speech recognition and automatic segmentation and alignment when the content of the paragraph is known. A large number of artificially labeled English corpus was used to train the pronunciation model, a total of 44 phoneme models (20 vowels, 24 consonants). Using the BEEP dictionary with pronunciation variation, the language model required in the recognition process is generated using known paragraph content scr...
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
PUM
Login to View More
Abstract
The invention discloses a pronunciation quality assessment and error detection method based on the fusion of multiple characteristics and multiple systems, which carries out assessment and error detection on pronunciation quality by a method utilizing multiple characteristic parameters to describe pronunciation quality and utilizing multiple inspecting systems to mutually fuse, and comprises the following steps: recognizing voice and automatically segmenting and aligning the voice; extracting the characteristic parameters used for voice quality assessment and error detection; acquiring pronunciation quality assessment and error detection model training data; training a plurality of pronunciation quality assessment and error detection systems; fusing a plurality of pronunciation quality assessment and error detection systems; and assessing pronunciation quality and detecting pronunciation errors. By utilizing the invention, multiple voice characteristics are effectively utilized, and multiple assessment and detection system are fully utilized and perform information fusion, thereby maximally exerting the advantages of various characteristics and systems, and ensuring the accuracy and reliability of pronunciation assessment and error detection.
Description
technical field [0001] The invention relates to the technical field of application of speech recognition and multi-system fusion technology in pronunciation quality assessment and pronunciation error detection, in particular to a pronunciation quality assessment and error detection method based on multi-feature and multi-system fusion. Background technique [0002] At present, the oral English test in China still adopts the form of manual evaluation. Due to the need to test a large number of candidates in a short period of time, the test organization is heavy, the test cost is high, and the efficiency is low. At the same time, manual evaluation is highly subjective and difficult to guarantee The objectivity and fairness of the examination. Using computer technology to automatically evaluate and detect pronunciation quality and pronunciation errors can effectively make up for the lack of manual evaluation methods, and can provide great help for language-assisted teaching. ...
Claims
the structure of the environmentally friendly knitted fabric provided by the present invention; figure 2 Flow chart of the yarn wrapping machine for environmentally friendly knitted fabrics and storage devices; image 3 Is the parameter map of the yarn covering machine
Login to View More
Application Information
Patent Timeline
Application Date:The date an application was filed.
Publication Date:The date a patent or application was officially published.
First Publication Date:The earliest publication date of a patent with the same application number.
Issue Date:Publication date of the patent grant document.
PCT Entry Date:The Entry date of PCT National Phase.
Estimated Expiry Date:The statutory expiry date of a patent right according to the Patent Law, and it is the longest term of protection that the patent right can achieve without the termination of the patent right due to other reasons(Term extension factor has been taken into account ).
Invalid Date:Actual expiry date is based on effective date or publication date of legal transaction data of invalid patent.



 Login to View More
Login to View More  Login to View More
Login to View More